







DETR存在的问题
1.收敛速度慢
2.对小目标物体检测效果不好,因为transformer计算量大,受限于计算规模,CNN提取特征时只采取了最后一层特征,没有用FPN等结构。所以对于小目标检测效果不好。
论文主要观点
-
通过对DETRdecoder中的attentionmap进行可视化,发现query查询到的区域都是物体的extremity末端区域。所以论文认为attention尝试找到物体的边界区域。
-
论文中认为DETRtransofmer结构中的信息主要可以分为两部分,一部分是与图像的特征(颜色纹理等)相关的信息,称为content,比如encoder或decoder的输出信息。另一部分是代表空间上的信息,称为spatial,比如position embedding等。
-
detr中的CNN与encoder只涉及图像特征向量提取;decoder中的self-attn只涉及query之间的交互去重;所以收敛慢的最可能原因发生在cross attn
-
Cross attention中的K包含encoder输出信息(content key Ck)与position embedding(spatial Key Pk),Q包含self attention的输出(content query Cq)和object query(spatial query Pq)信息。论文中发现去掉cross attention中的object基本不掉点,所以收敛慢很可能是content query难学习导致的。
-
提出了reference point的概念,为每个query设定一个检测范围,使得匹配更加稳定,加快了收敛
-
原始detr混合两者学习,使得content query难学习。所以将content与spatial进行解耦
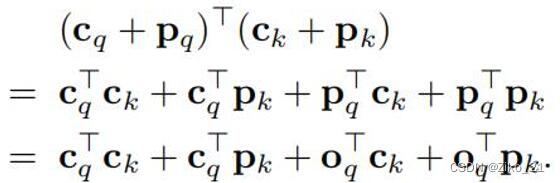
变为
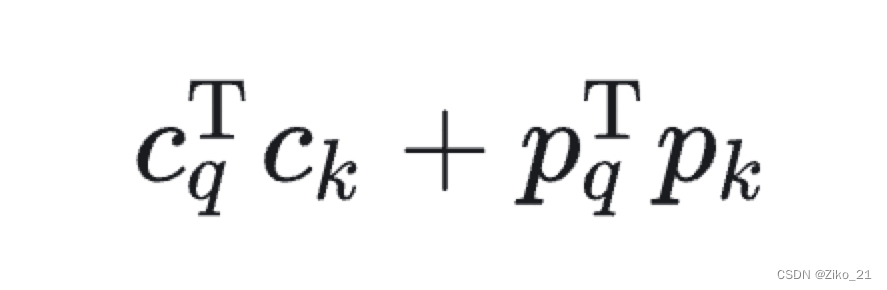
网络结构
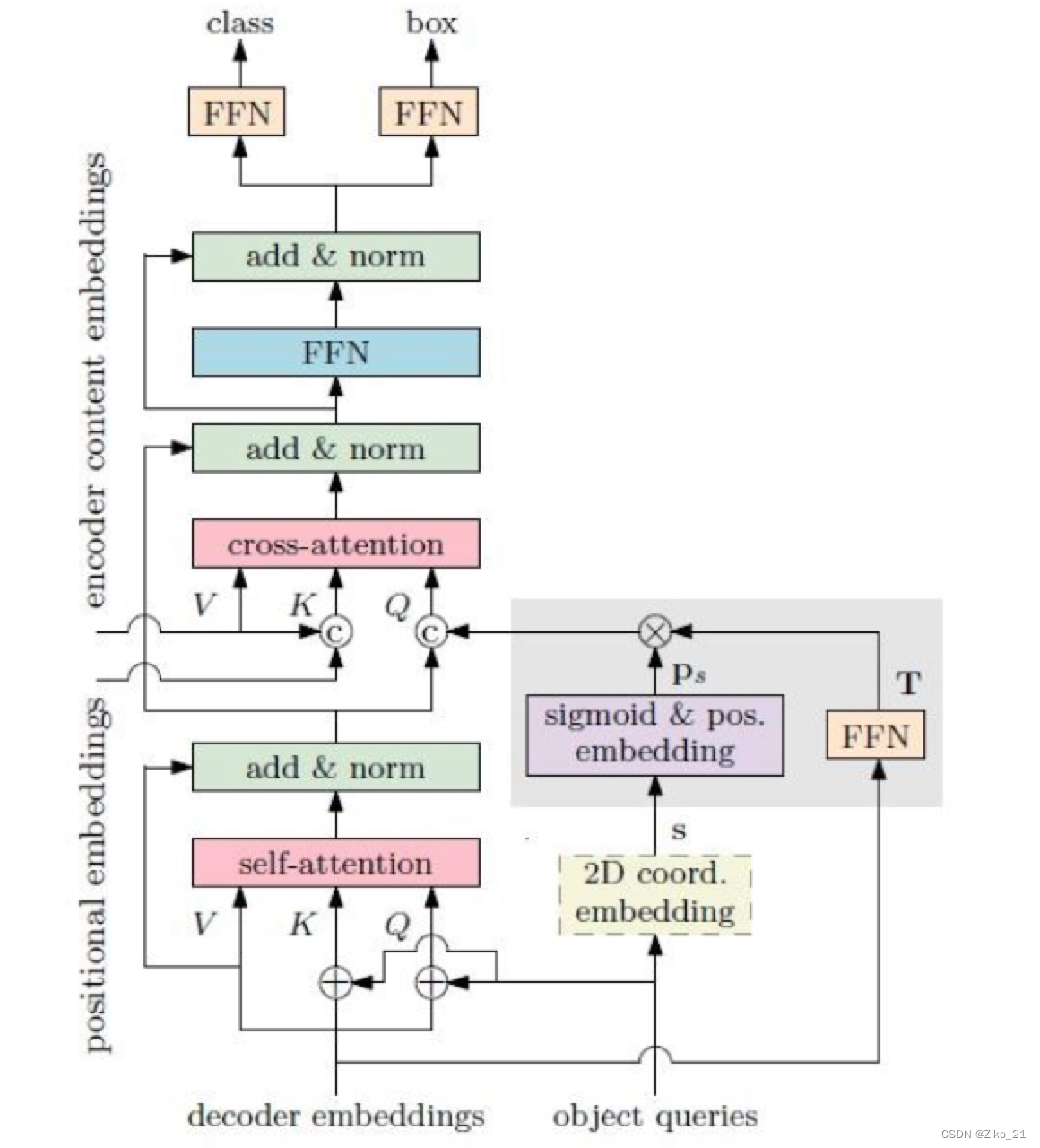
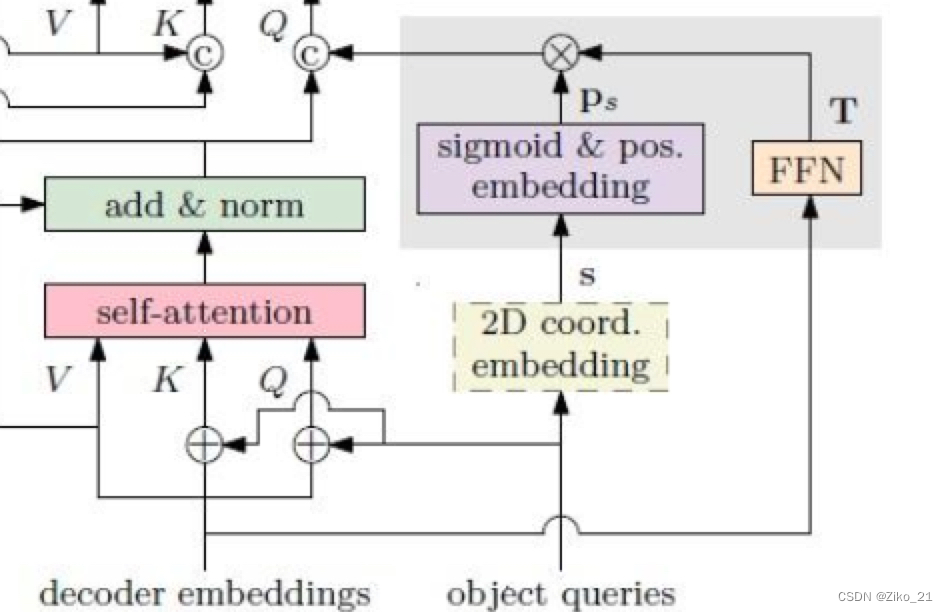
对于object query生成了一个2D坐标embedding(上图中的s),用于限定当前query的预测范围。最终decoder的输出的是相对与s的偏移量
bbox回归输出:
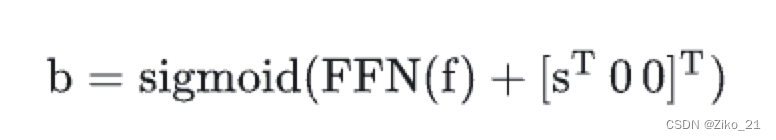
其中f是decoer的输出,S表示x,y的坐标。最终b是[x,y,w,h]的向量。
classifier分类输出:
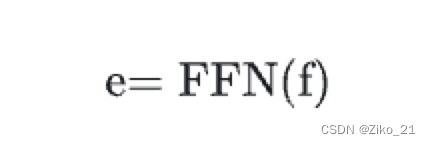
f是decoder的输出,输出每个候选框的类别
decoder Pq生成:
提出了reference point的概念,即图中的s,是一个2d的坐标(q_num,B,2),由object queries经过一个线性层生成,代表了每个query的预测范围。
s经过sigmoid和position embedding后(图中的Ps),跟FFN(decoder embedding)(即图中的T)做内积。得到空间特征Pq
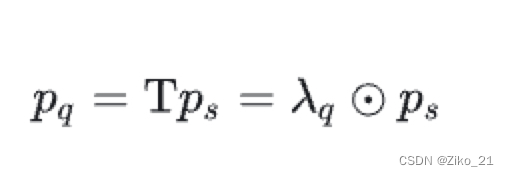
代码spatial query这一部分的实现:
# query_pos [num_query,batch,d_model]
# reference_points_before_sigmoid [num_query,batch,2] 从query预测一个坐标,代表了这个query预测的大概范围
reference_points_before_sigmoid = self.ref_point_head(query_pos) # [num_queries, batch_size, 2]
reference_points = reference_points_before_sigmoid.sigmoid().transpose(0, 1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









