







【机器学习】生成对抗网络 GAN
GAN能干什么?
要问生成对抗网络(GAN)为什么这么火,就得看看它能干什么。
GAN是最近2年很热门的一种无监督算法,他能生成出非常逼真的照片,图像甚至视频。我们手机里的照片处理软件中就会使用到它。
GAN的核心思想是通过学习真实训练数据,生成“以假乱真”的数据。
GAN的设计初衷
一句话来概括 GAN 的设计动机就是——自动化。
1.从人工提取特征——到自动提取特征
深度学习最特别最厉害的地方就是能够自己学习特征提取。
机器的超强算力可以解决很多人工无法解决的问题。自动化后,学习能力更强,适应性也更强。
2.从人工判断生成结果的好坏——到自动判断和优化
监督学习中,训练集需要大量的人工标注数据,这个过程是成本很高且效率很低的。
而人工判断生成结果的好坏也是如此,有成本高和效率低的问题。
而 GAN 能自动完成这个过程,且不断的优化,这是一种效率非常高,且成本很低的方式。
下面我们通过GAN的原理来理解它是如何实现自动化的。
GAN 的基本原理(大白话)
生成对抗网络(GAN)由2个重要的部分构成
1.生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器。
2.判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”。
生成模型的任务是生成看起来自然真实的、和原始数据相似的实例。判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的(真实实例来源于数据集,伪造实例来源于生成模型)。

训练过程
1.第一阶段:固定“判别器D”,训练“生成器G”
我们使用一个还 OK 的判别器,让一个“生成器G”不断生成“假数据”,然后给这个“判别器D”去判断。
一开始,“生成器G”还很弱,所以很容易被揪出来。
但是随着不断的训练,“生成器G”技能不断提升,最终骗过了“判别器D”。
到了这个时候,“判别器D”基本属于瞎猜的状态,判断是否为假数据的概率为50%。
2.第二阶段:固定“生成器G”,训练“判别器D”
当通过了第一阶段,继续训练“生成器G”就没有意义了。这个时候我们固定“生成器G”,然后开始训练“判别器D”。
“判别器D”通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,“生成器G”已经无法骗过“判别器D”。
3.循环阶段一和阶段二
通过不断的循环,“生成器G”和“判别器D”的能力都越来越强。
最终我们得到了一个效果非常好的“生成器G”,我们就可以用它来生成我们想要的图片了。
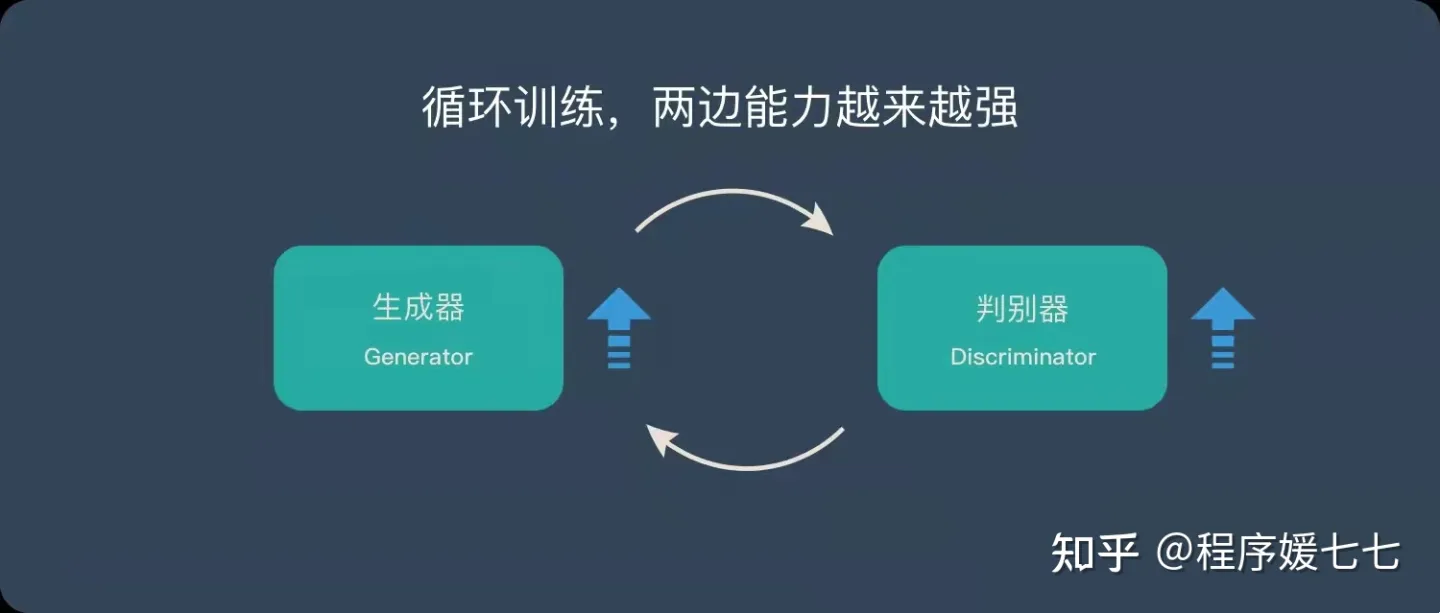
也就是说,生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。
模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步。
这样我们就可以使用这个生成器来生成我们想要的图片了(用于做训练集之类的)。
GAN的总结
1.GAN&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1933
1933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









