







 本文介绍了深度学习中的梯度下降法和随机梯度下降法(SGD)。梯度下降法是寻找函数局部极小值的算法,而SGD作为其变种,每次仅用部分样本进行优化,提高了计算速度。在SGD的基础上,引入了动量概念以加速收敛并避免局部最优。实际训练中,通常采用小批量随机梯度下降,以平衡计算效率和收敛速度。
本文介绍了深度学习中的梯度下降法和随机梯度下降法(SGD)。梯度下降法是寻找函数局部极小值的算法,而SGD作为其变种,每次仅用部分样本进行优化,提高了计算速度。在SGD的基础上,引入了动量概念以加速收敛并避免局部最优。实际训练中,通常采用小批量随机梯度下降,以平衡计算效率和收敛速度。
首先要搞懂损失函数与代价函数。
损失函数是单个样本与真实值之间的差距
代价函数是整个样本集与真实值的平均差距
随机梯度下降就是不使用代价函数对参数进行更新,而是使用损失函数对参数更新。
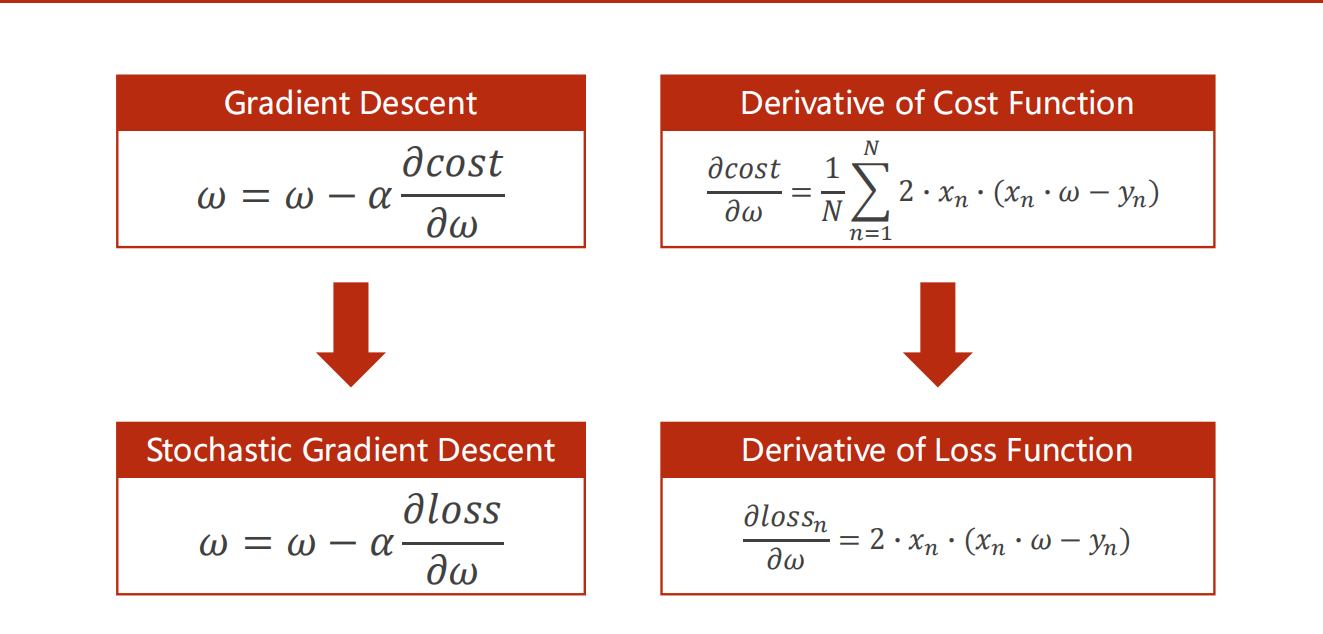
梯度下降法( gradient descent )是一阶最优化算法,通常也称为最速下降法,是通过函数当前点对应梯度(或者是近似梯度)的反方向,使用规定步长距离进例行迭代搜索,从而找到一一个函数的局部极小值的算法,最好的情况是希望找到全局极小值。但是在使用梯度下降算法时,每次更新参数都需要使用所有的样本。如果 对所有的样本均计算一次, 当样本总量特别大时,对算法的速度影响非常大,所以就有了随机梯度下降(stochastic gradient descent, SGD )算法。它是对梯度下降法算法的一种改进,且每次只随机取一部分样本进行优化, 样本的数量一般是2的整数次幂,取值范围是32~256,以保证计算精度的同时提升计算速度,是优化深度学习网络中最常用的一类算法。
SGD算法及其一些变种, 是深度学习中应用最多的一类算法。在深度学习中,SCD通常指小批随机梯度下降( mini-batch gradient descent )算法,其在训练过程中,通常会使用一个固定的学习率进行训练。 即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









