







 FoldingNet是一种基于2D纸折叠思想的3D点云自动编码器,通过深度网格变形重建3D物体。它利用PointNet作为编码器,结合2D网格的解码器来学习点云的表示。实验结果显示,FoldingNet能够有效地进行形状插值和重建。
FoldingNet是一种基于2D纸折叠思想的3D点云自动编码器,通过深度网格变形重建3D物体。它利用PointNet作为编码器,结合2D网格的解码器来学习点云的表示。实验结果显示,FoldingNet能够有效地进行形状插值和重建。
清库存系列
1. 概要
题目:FoldingNet: Point Cloud Auto encoder via Deep Grid Deformation (CVPR’18 spotlight)
论文:https://openaccess.thecvf.com/content_cvpr_2018/papers/Yang_FoldingNet_Point_Cloud_CVPR_2018_paper.pdf
补充材料:https://openaccess.thecvf.com/content_cvpr_2018/Supplemental/1129-supp.pdf
代码:https://www.merl.com/research/license#FoldingNet
简述: 基于2D纸折叠的思想产生3D物体
后续延伸:
- FoldingNet++
- Real-time Soft Robot 3D Proprioception via Deep Vision based Sensing
类似工作:
AtlasNet, 其是使用multiple grid块来初始化2D grid。
2. 动机
神经网络能否学习纸的折叠呢?
3D点云数据大部分来源于物体表面小区域可以看成是2D流体,可以通过2D经过一系列变换获取得到。

3. 思想
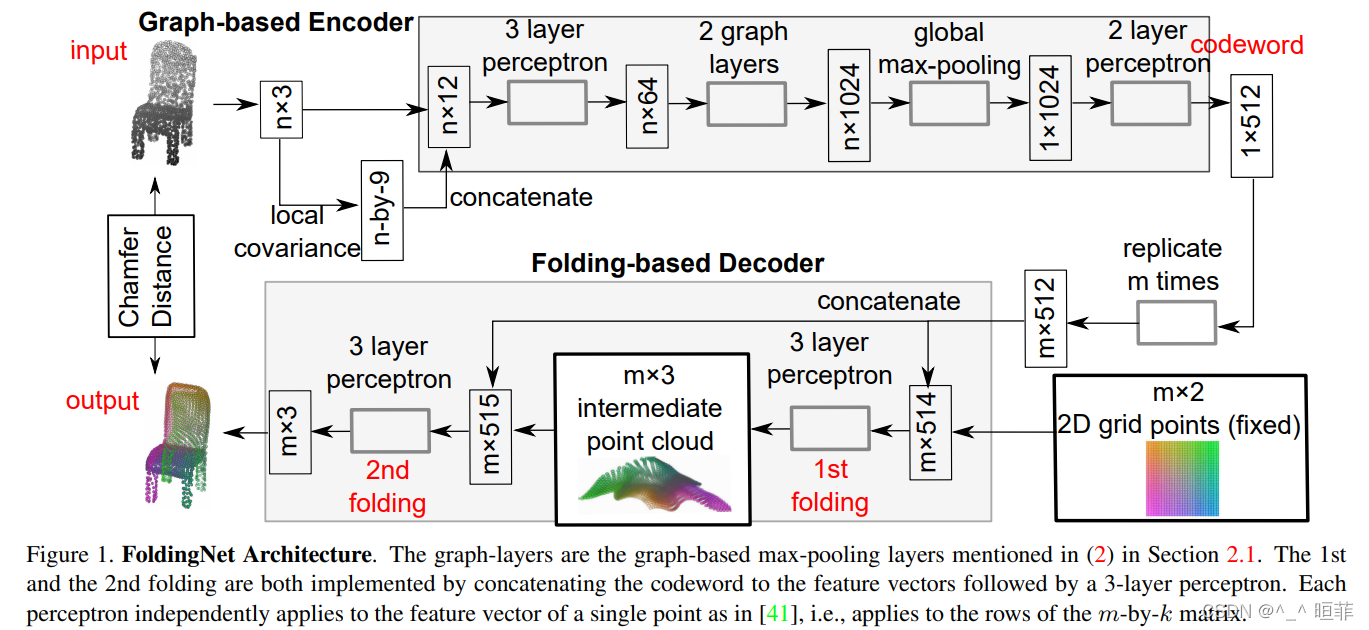
整体框架:主设计解码器
主要是设计了解码器,Encoder直接使用PointNet部分和简单图思想。
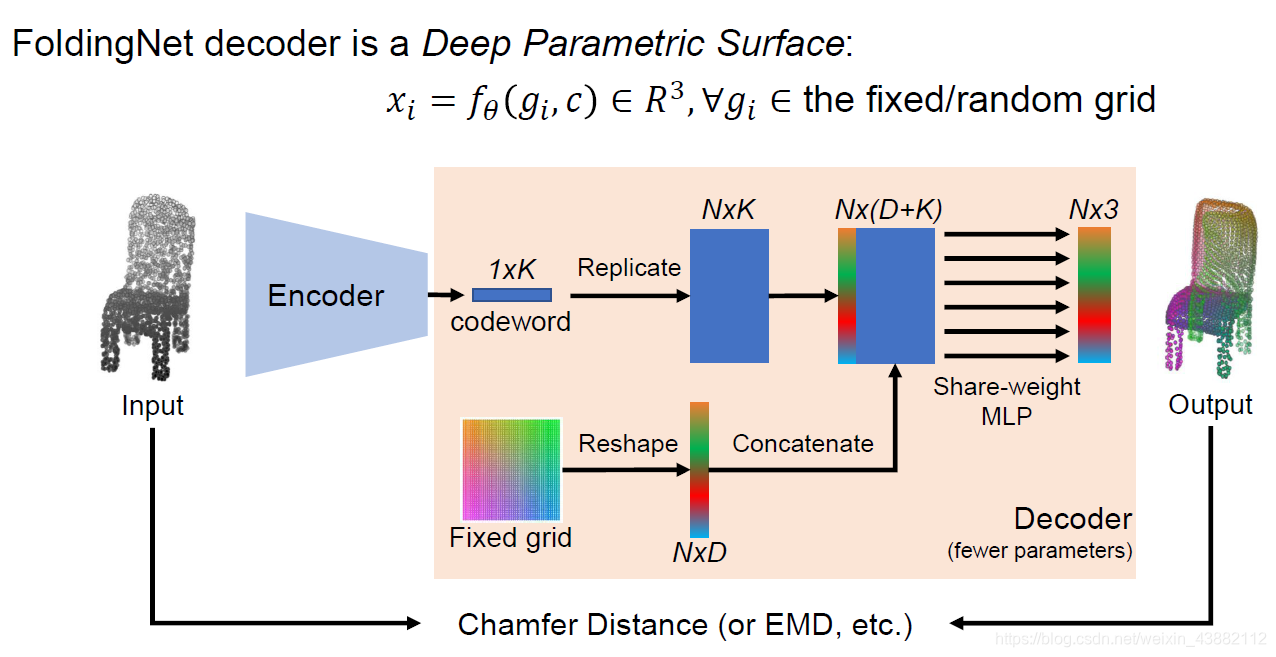
简单来讲,就是把隐码复制了N份,然后与2D的网格进行拼接,形成Nx(D+K)维度的隐码,通过学习获得有位置信息的点云。
其实可以简单理解成为几何当中的一个定义:自然界里的高维数据可以表示为低维非线性的流形。这里就运用这个思想将三维点云认为是二维的流形,那么二维里面就用一个简单的网格来模拟。所以其受限在只可以模拟3D中没有环出现的情况,有环的出现时就不行了。所以才有了后面FoldingNet++的出现用来解决有环出现的情况。
基于图的编码器Encoder
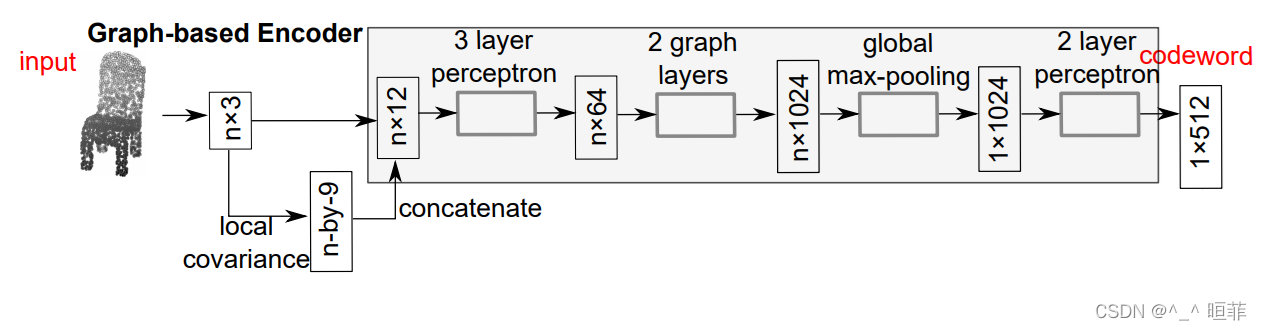
编码器 = 多层感知器 + 基于图的最大池化层,两者拼接在一起形成编码器;
图的构成:16-KNN, 对于每个点,计算器的局部协方差矩阵,使用 3 × 3 3\times3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2094
2094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









