







文章目录
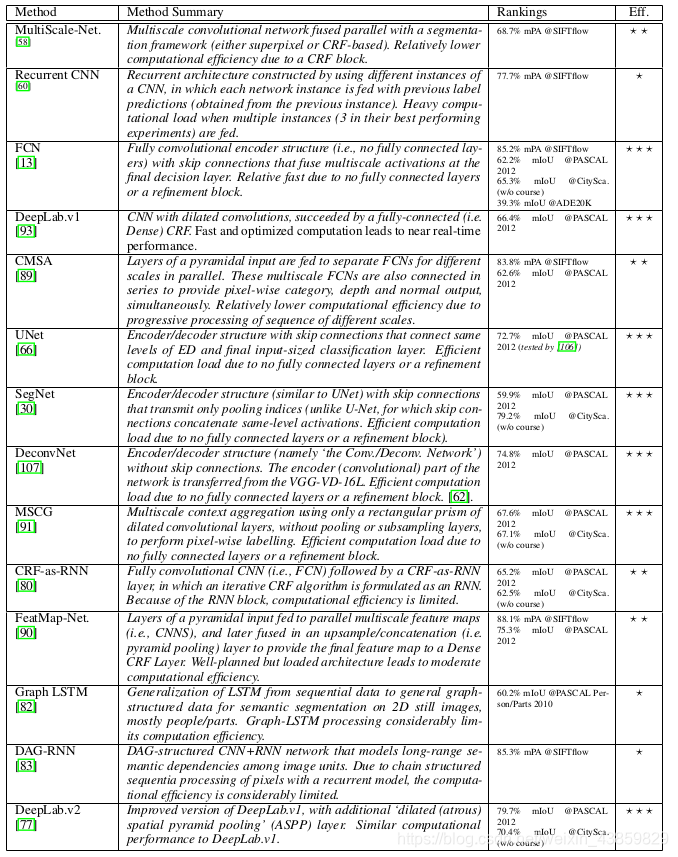
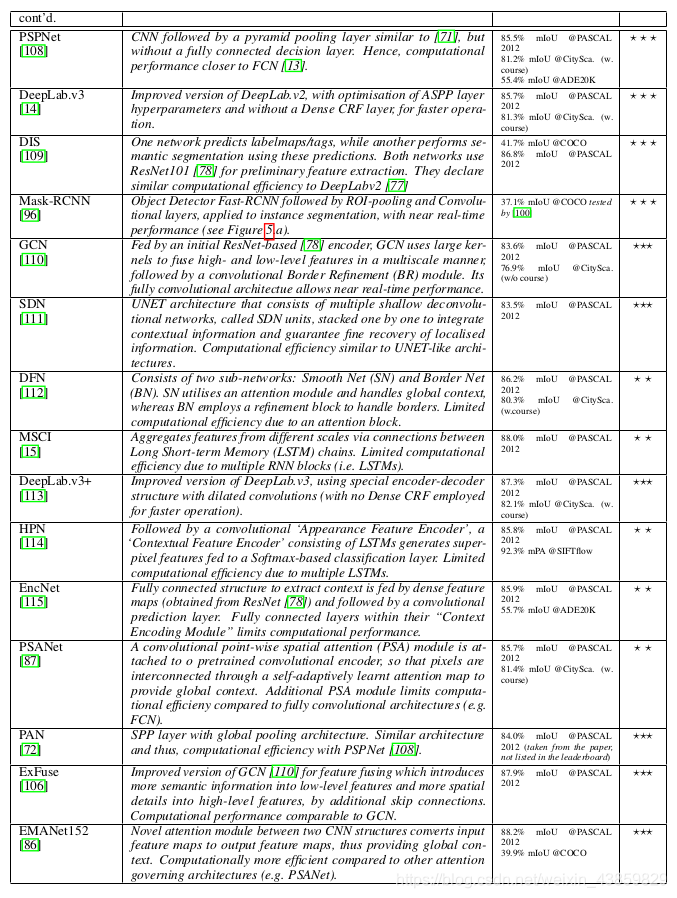
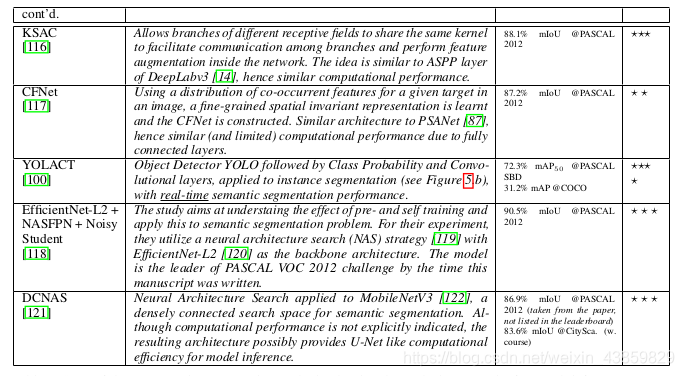
FCN
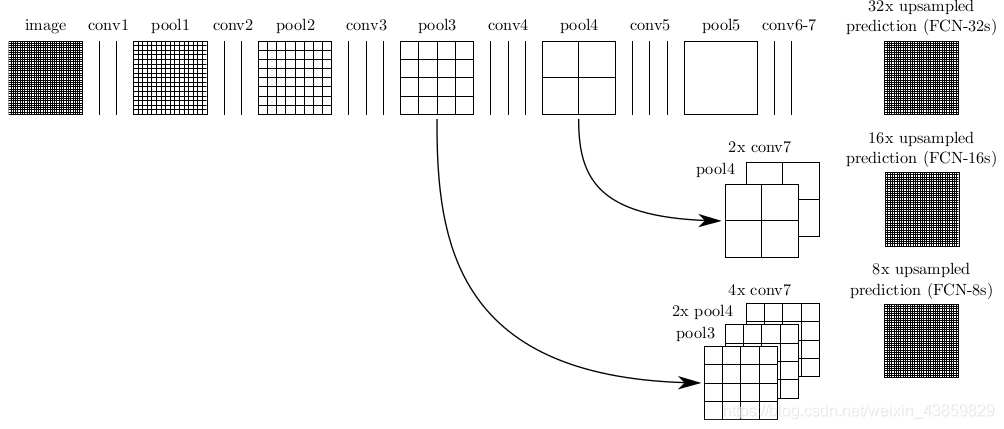
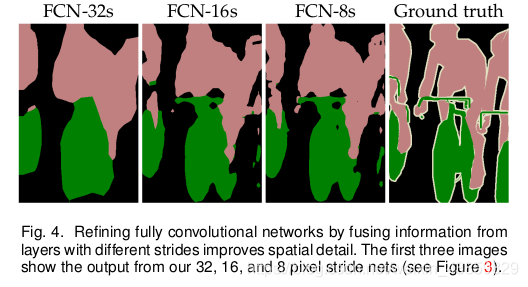
FCN-32X
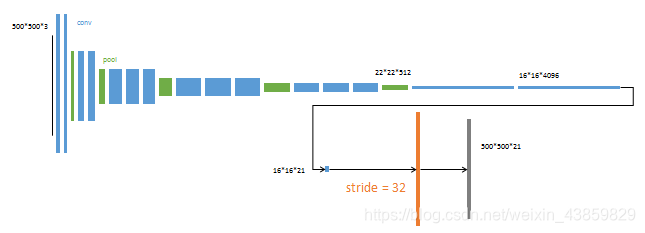
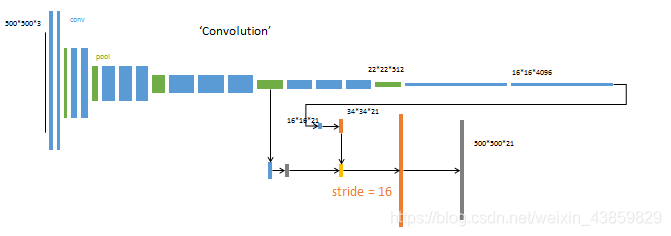
FCN-16X
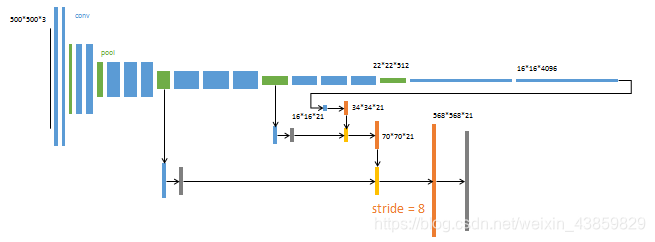
FCN-8X
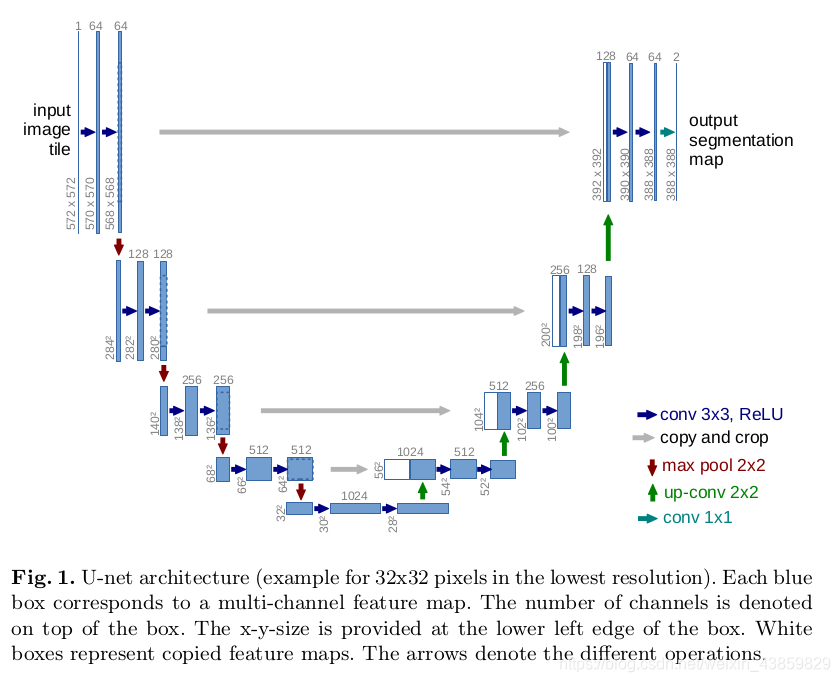
U-NET
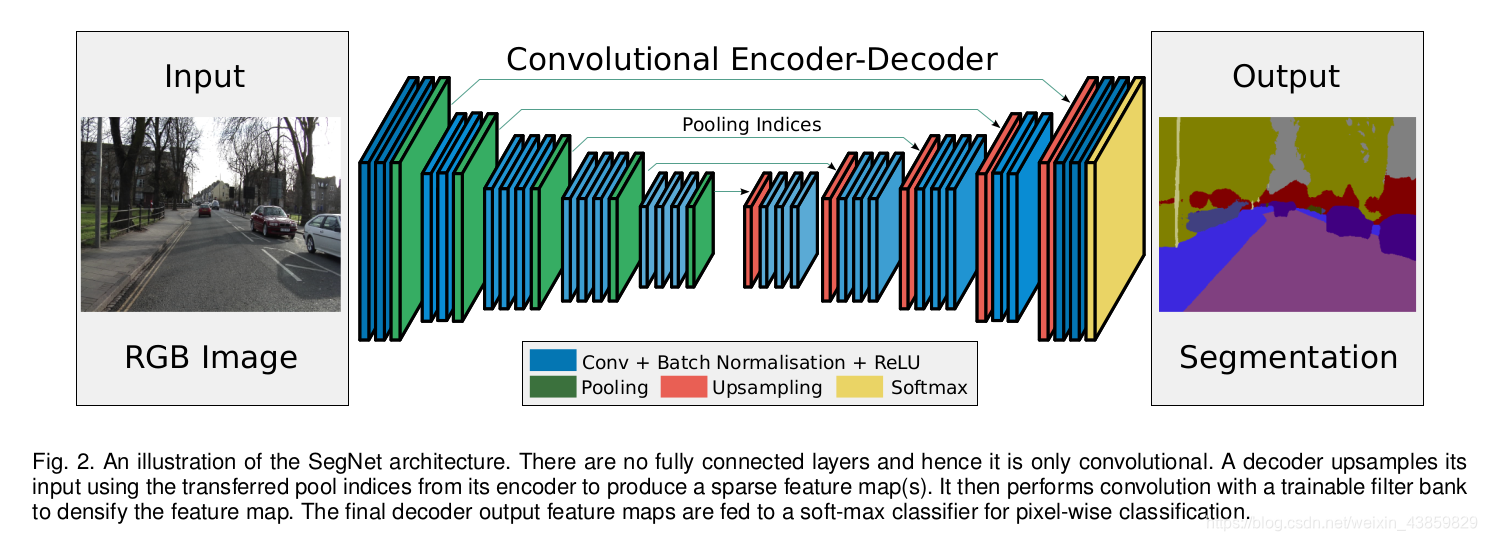
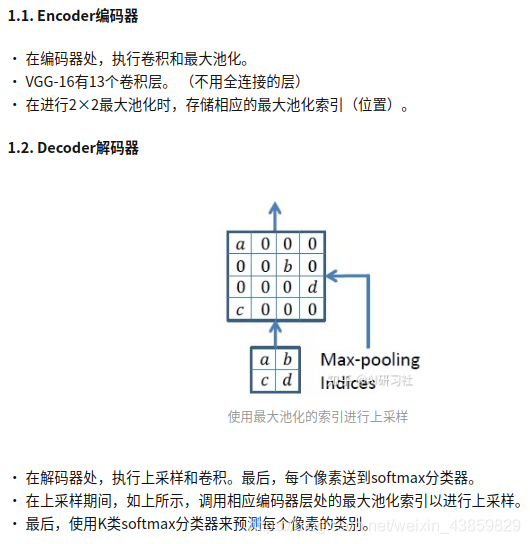
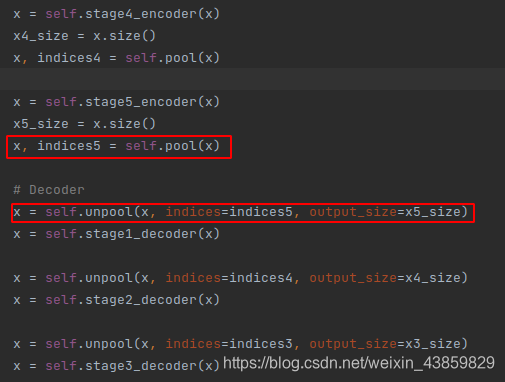
SEG-NET
DeepLab
deeplabv1
针对标准的深度卷积神经网络的两个主要问题:1.Striding操作使得输出尺寸减小; 2.Pooling对输入小变化的不变性,v1 使用空洞卷积(atrous)+条件随机场(CRFs)来解决这两个问题。
DeepLab v1是在VGG16的基础上做了修改:
VGG16的全连接层转为卷积
最后的两个最大池化层去掉了下采样
后续卷积层的卷积核改为了空洞卷积
在ImageNet上预训练的VGG16权重上做finetune
deeplab v2
v2的改进:提出了空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP),使用多个采样率采样得到的多尺度分割对象获得了更好的分割效果。
基础层使用了resnet
使用不同的学习率策略
针对物体的多尺度问题,提出ASPP模块;在卷积之前以多种采样率在给定的特征层上进行重采样;使用多条平行的有不同采样率的空洞卷积层。
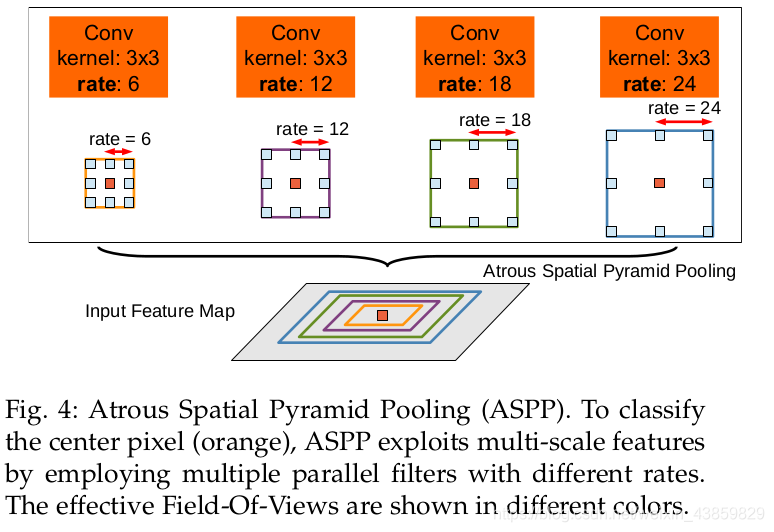

deeplab v3
DeepLabv3 的主要变化如下:
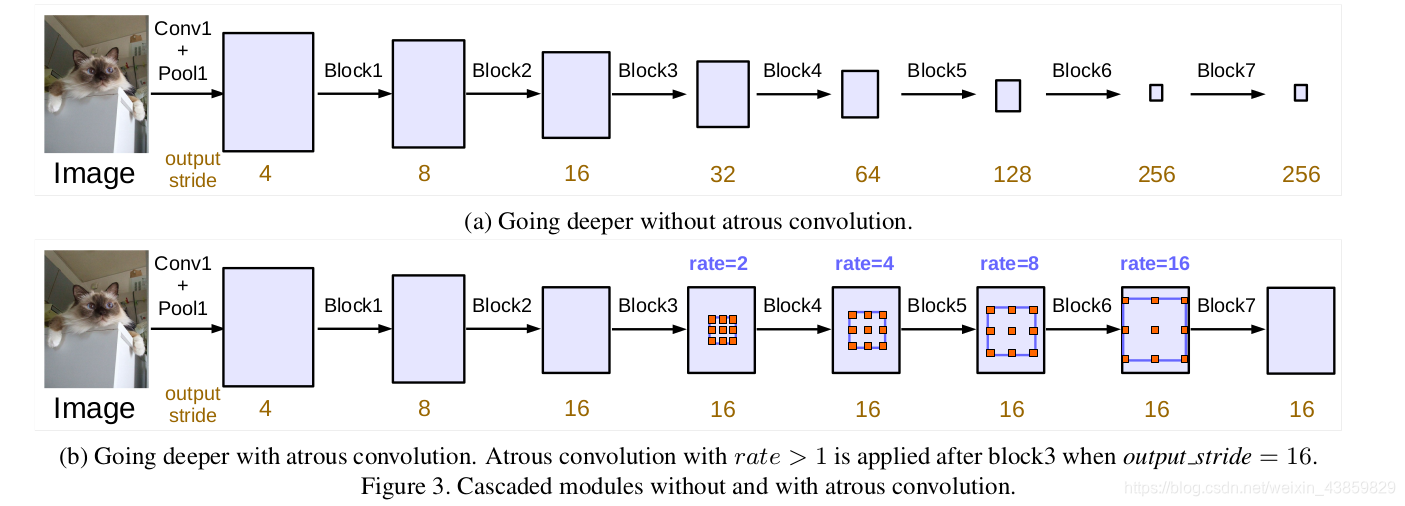
- 使用了Multi-Grid 策略,即在模型后端多加几层不同 rate 的空洞卷积:
- 将 batch normalization 加入到 ASPP模块.
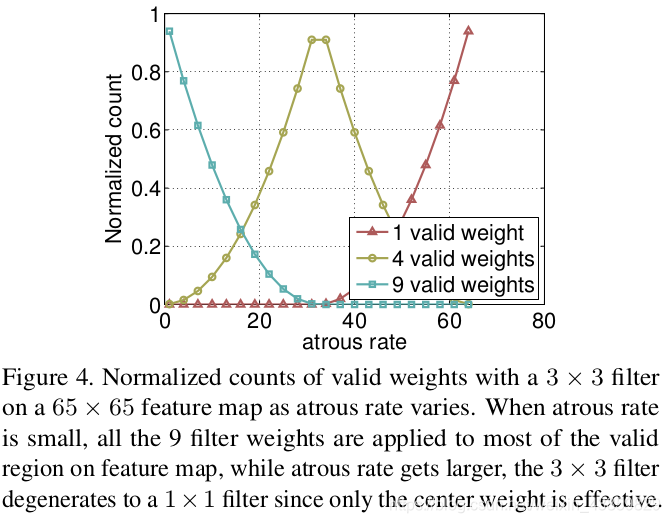
- 具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息。不过,论文发现,随着sampling rate的增加,有效filter特征权重(即有效特征区域,而不是补零区域的权重)的数量会变小,极端情况下,当空洞卷积的 rate 和 feature map 的大小一致时, [3x3] 卷积会退化成 [1x1] :
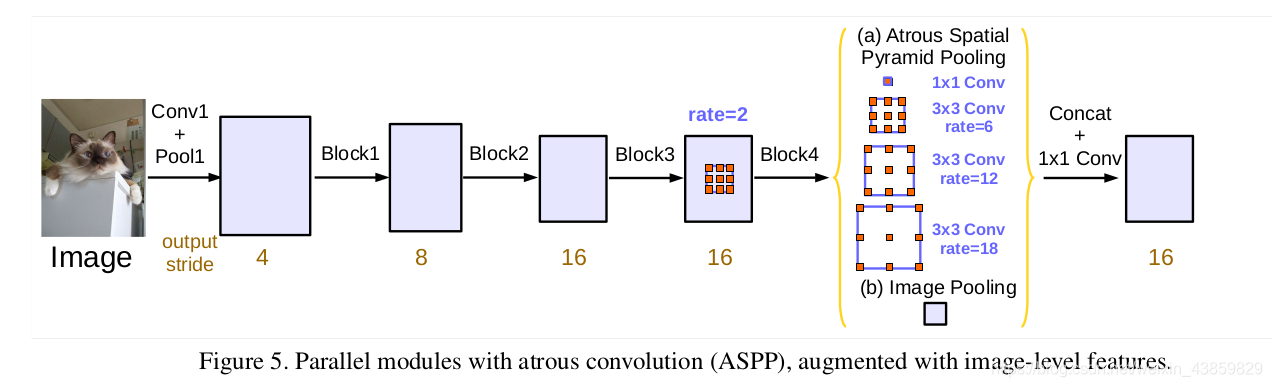
- 为了保留较大视野的空洞卷积的同时解决这个问题,DeepLabv3 的 ASPP 加入了 全局池化层+conv1x1+双线性插值上采样 的模块
deeplab V3+
最大的改进是将 DeepLab 的 DCNN 部分看做 Encoder,将 DCNN 输出的特征图上采样成原图大小的部分看做 Decoder ,构成 Encoder+Decoder 体系,双线性插值上采样便是一个简单的 Decoder,而强化 Decoder 便可使模型整体在图像语义分割边缘部分取得良好的结果。
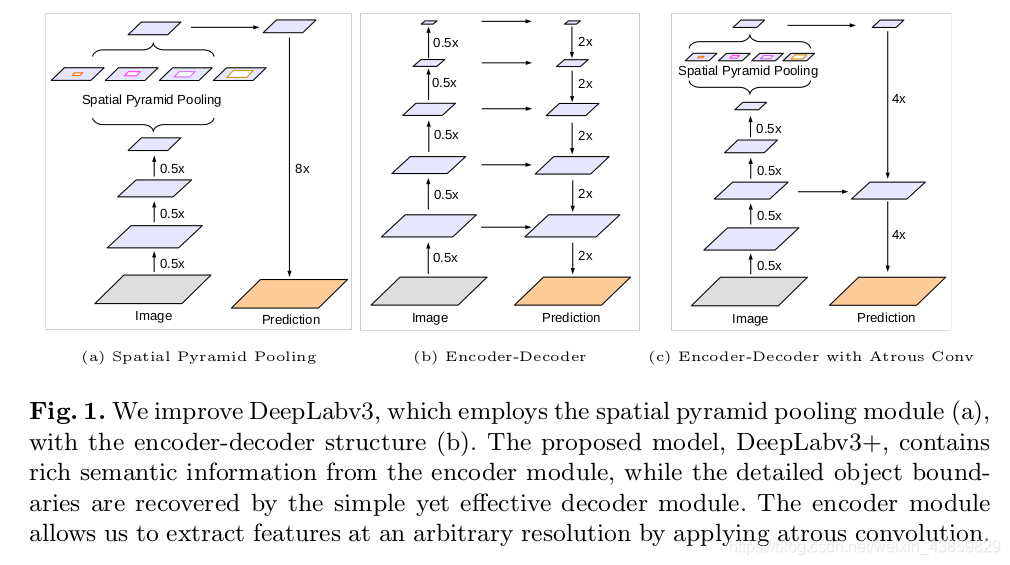
具体来说,DeepLabV3+ 在 stride = 16 的DeepLabv3 模型输出上采样 4x 后,将 DCNN 中 0.25x 的输出使用 [1x1] 的卷积降维后与之连接(concat)再使用 [3x3] 卷积处理后双线性插值上采样 4 倍后得到相对于 DeepLabv3 更精细的结果。
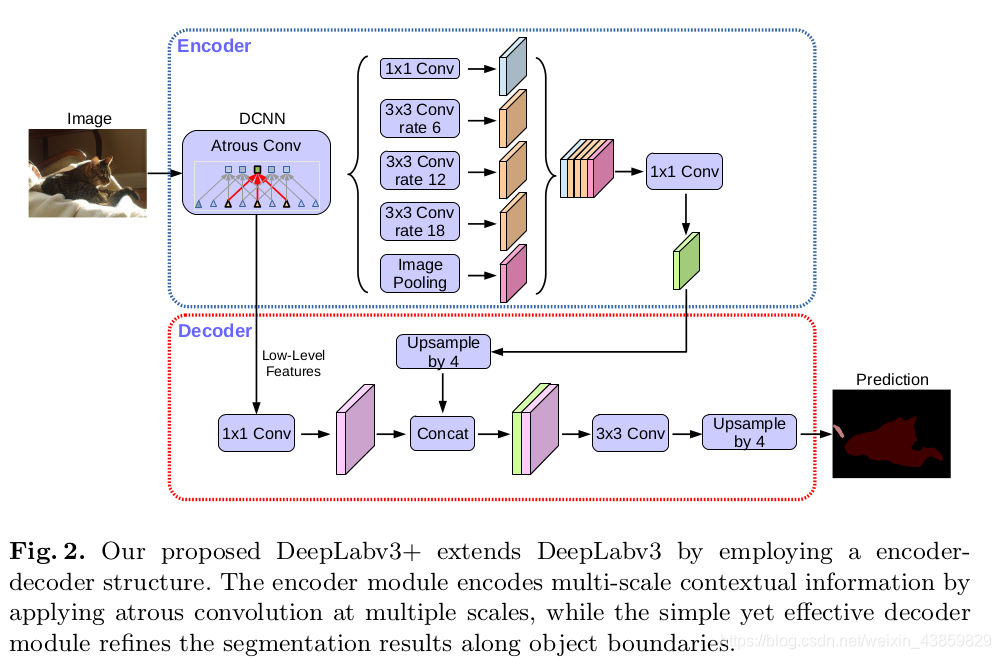
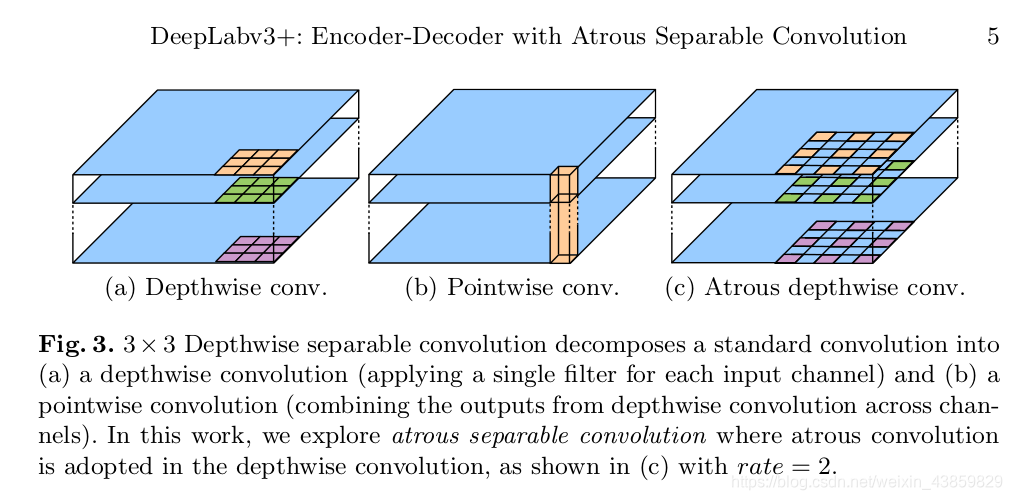
还借鉴MobileNet,使用 Depth-wise 空洞卷积
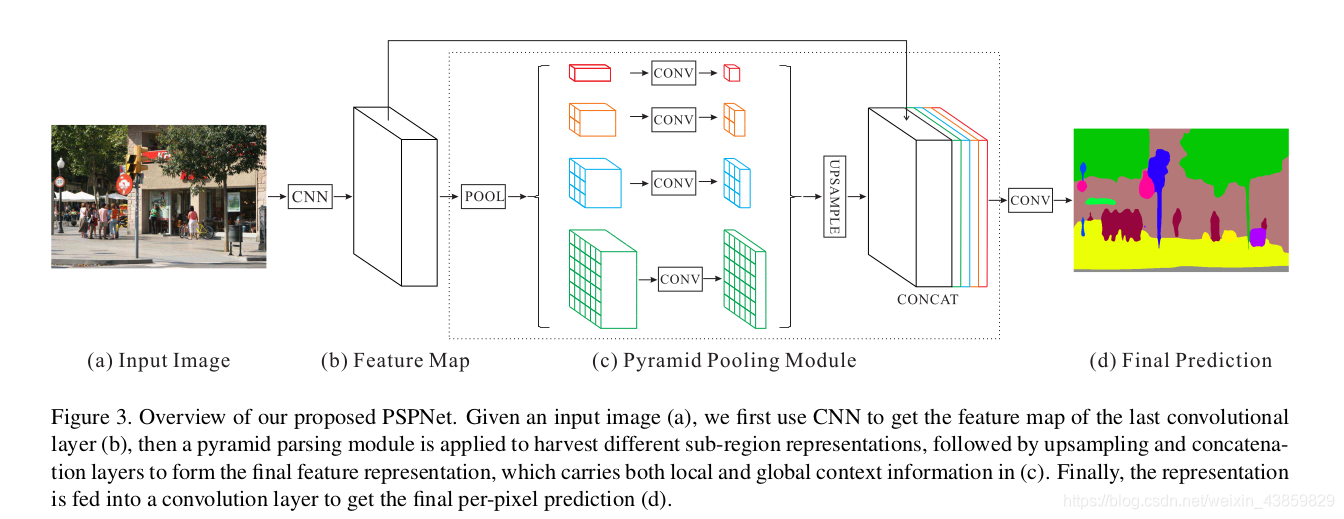
PSP-Net
目前基于FCN的模型的主要问题是缺乏合适的策略来利用全局场景中的类别线索,对于典型的复杂场景理解,以往为了获得全局图像级特征,空间金字塔池化被广泛应用,这种空间统计方法为整体场景解析提供了一个很好的描述符,空间金字塔池化网络(SPPNet)进一步提高了这种能力。
我们为深层的ResNet开发了一种有效的优化策略,基于深度监督的loss:
经过深度预先训练的网络能带来良好的性能,然而,网络深度的增加可能会带来额外的优化难度。相反,我们提出了一个附加loss,可以监督初始结果,并用后面的最终loss来学习残差。因此,深层网络的优化被分解为两个问题,每一个都更容易解决。
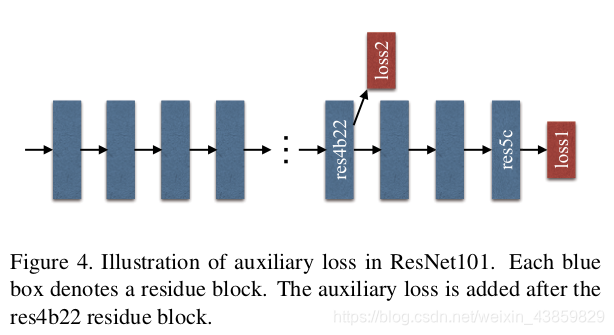
基于注意力的语义分割之PSANet、DANet、OCNet、CCNet、EMANet、SANet等
参考这个地方
PSANet
作者认为由于卷积核的物理结构设计,导致CNN中的信息流被约束在局部区域中,从而限制了复杂场景的理解。因此,本文的创新点在于(1)通过自适应学习一个注意力掩码,将特征映射上的每个位置与其他位置联系起来,来缓和这种局部邻域约束;(2)设计双向信息传播路径,即每个位置聚合其他所有位置的信息来帮助预测自己,同时每个位置的信息可以分布到全局,协助所有其他位置的预测。
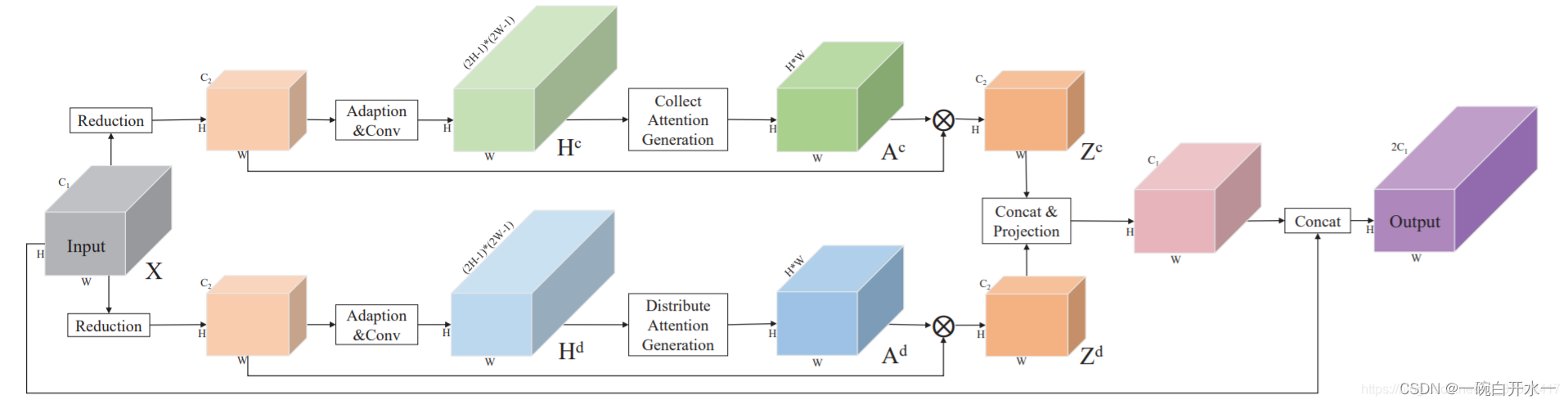


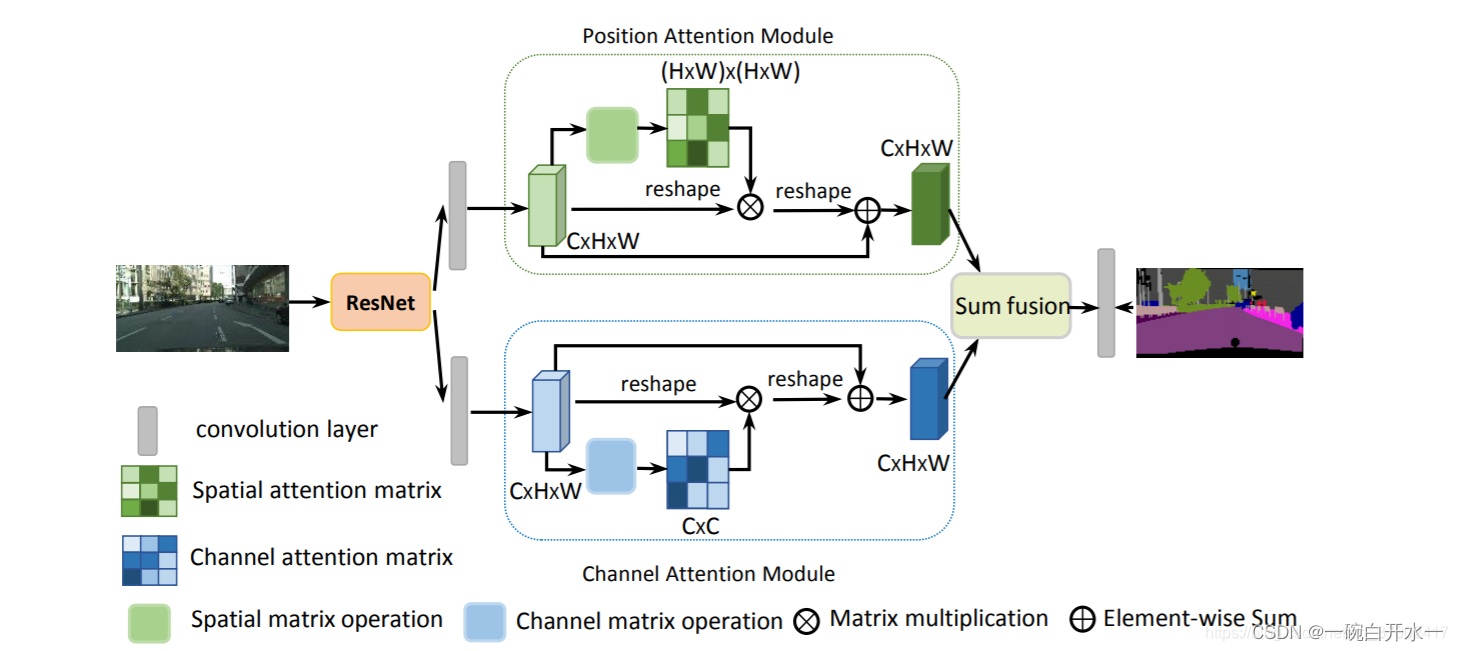
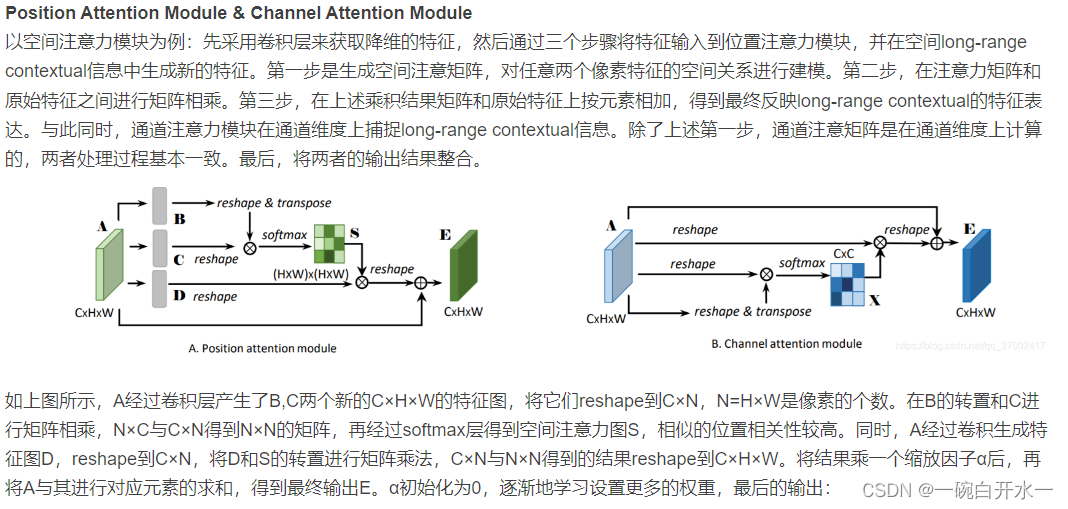
DANet(2019)
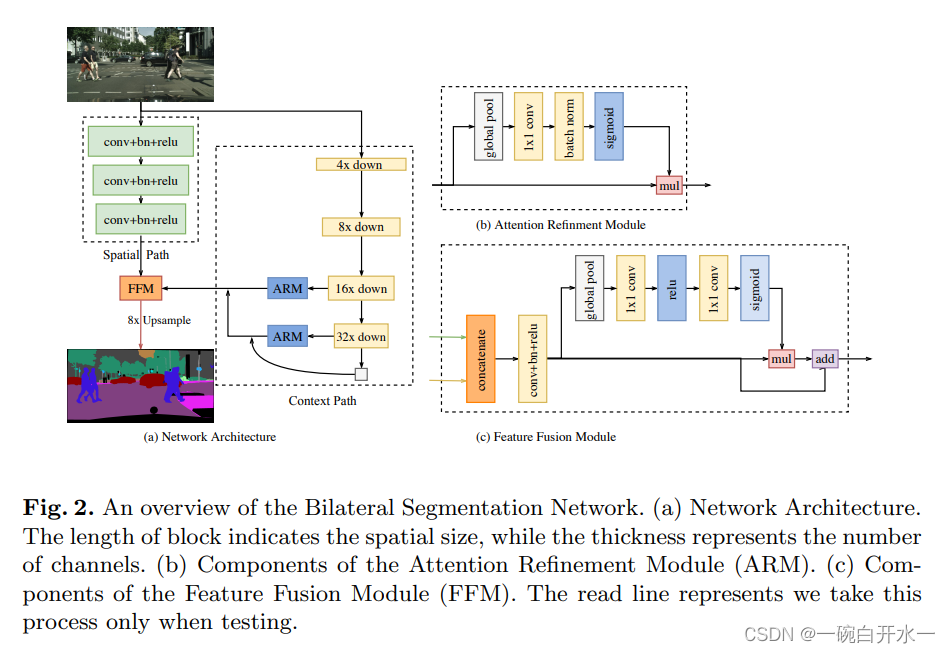
BISENET
- 提出了一种包含空间路径(SP)和上下文路径(CP)的双边分割网络(BiSeNet), 将空间信息保存和接受域提供的功能解耦成两条路径。
- 提出了特征融合模块(FFM)和注意细化模块(ARM),以在可接受的成本下进一步提高精度。
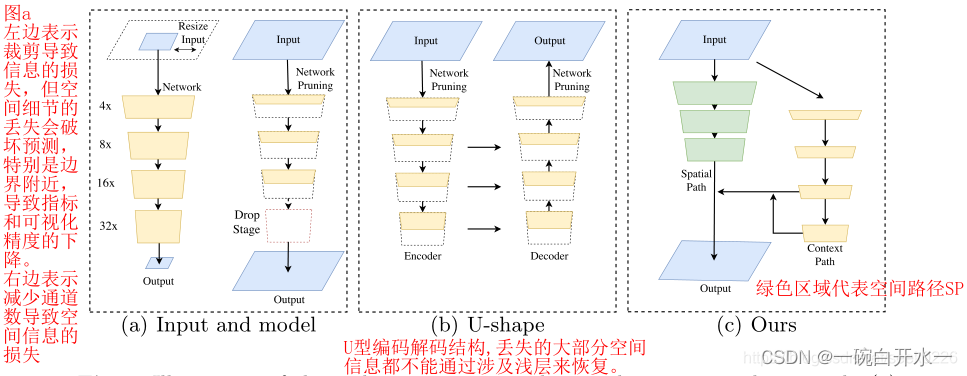
作者对比了当前用于三种用于加速模型的实时语义分割算法:
图(a)左侧所示,通过裁剪图片降低尺寸和计算量,但是会丢失大量边界信息和可视化精度。
图(a)右侧所示,通过修建/减少卷积过程中的通道数目,提高推理速度。其中的红色方框部分,是作者提及的ENet建议放弃模型的最后阶段(downsample操作),模型的接受域不足以覆盖较大的对象导致的识别能力较差。
图形(b)所示为U型的编码,解码结构,通过融合骨干网的细节,u型结构提高了空间分辨率,填补了一些缺失的细节,但是作者认为在u型结构中,一些丢失的空间信息无法轻易回复,不是根本的解决方案。
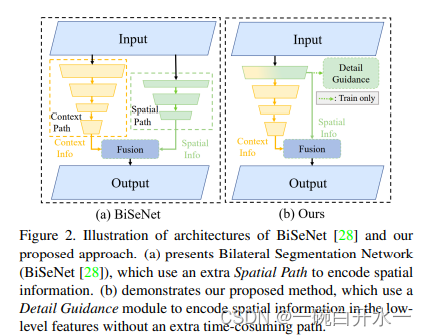
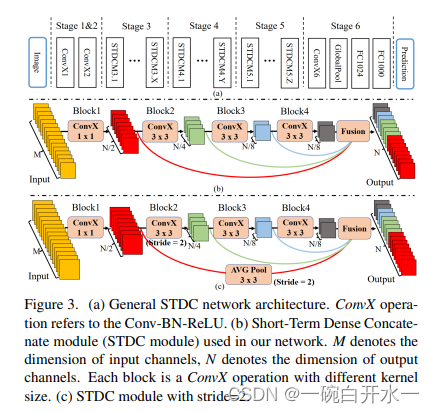
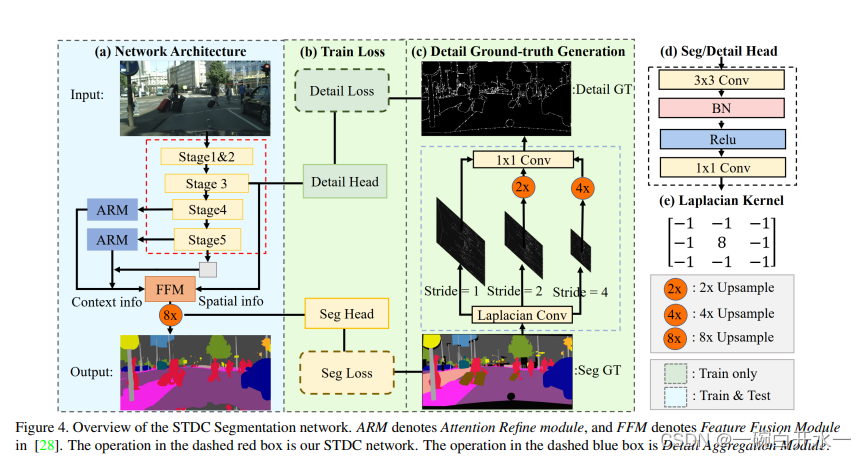
STDC
下图中可以看出STDC网络删除了BISeNet中的spatial path,并使用Detail Guidance结构去代替空间路径的功能。这里先简要提下Detail Guidance,即使用拉普拉斯卷积核生成一个Detail GT图,然后使用Detail GT图与下采样8倍的特征图计算一个辅助Detail Loss。通过这个loss提升网络学习到边缘信息的能力。另外,该loss分支只在训练阶段存在,模型测试阶段推理时是不需要的,因此不会带来推理耗时。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









