







介绍
数据和特征决定了机器学习的上限,而模型和算法用来逼近这个上限。
简单来说就是对现有数据集进行特征的选取,特征并不是越多越好,特征越多代表模型越复杂越难拟合,所以选择对预测有价值的特征信息有助于模型的收敛预测。
特征工程又包括了特征提取、特征构建、特征选择等。
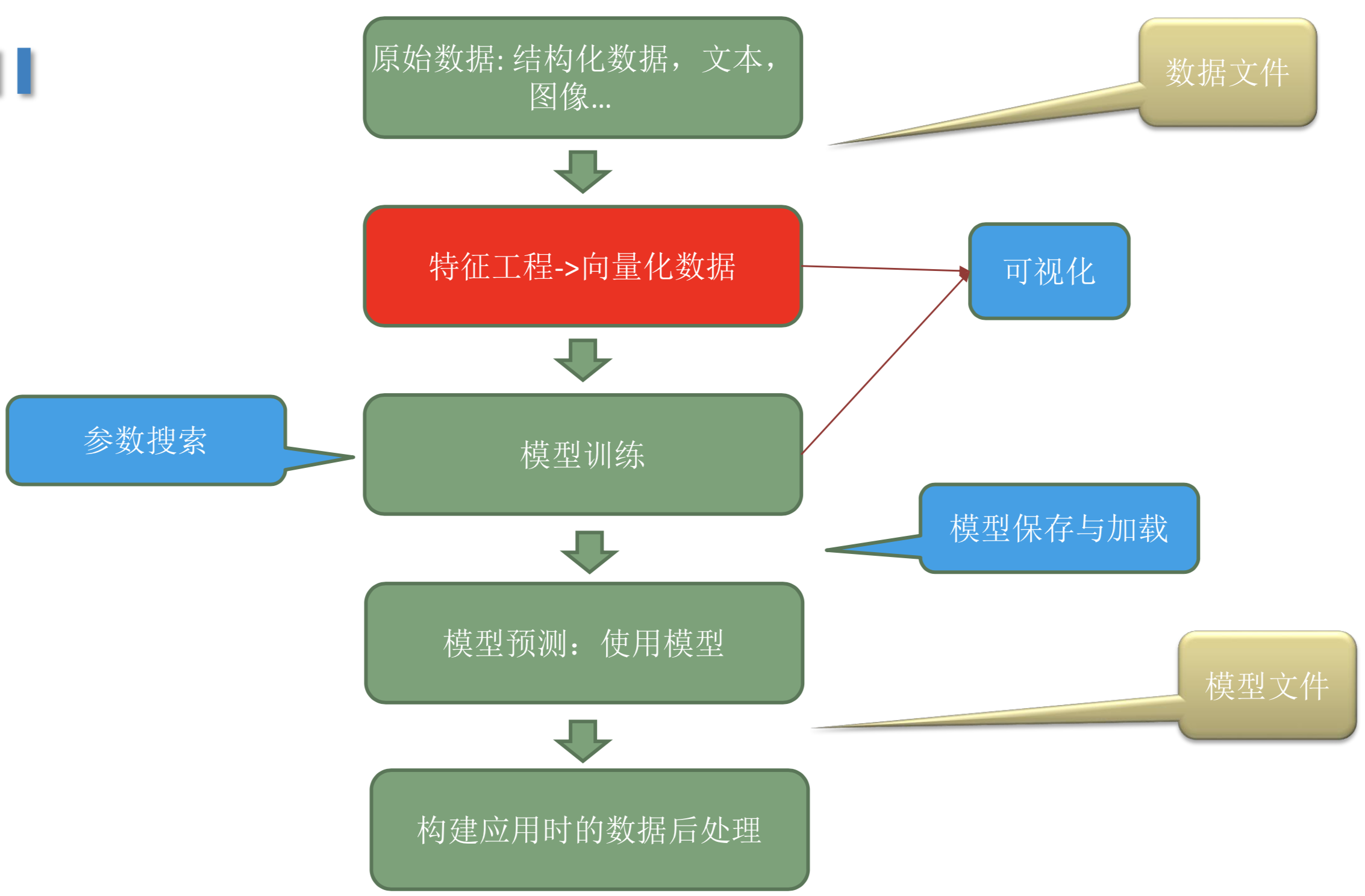
特征工程思考
- 为什么要做特征工程?
避免数据权重不一样带来的影响,直接比较两个特征权重是没有意义的。 - 做特征工程的好处
提升模型收敛速度
提升模型精度 - 探索
特征状况:类型,空值,分布(特征选择),异常点,量纲
标签状况:类型,分布 - 清洗/向量化
是否有空值、异常值
类别特征码转为向量:onehot
特征处理
对于不同的数据类型,有不同的处理方式,三种常见的数据类型:
- 数值型
- 类别型
- 时间类型
标准化(standardization)
对数值型数据的标准化主要有三种方法:Min-Max标准化、z-score标准化、robust标准化。
min-max标准化
- 特点
min-Max标准化,就是把数据按比例缩放,使之落入一个小的空间里。
同时不改变原有的正态分布,特征数据的取值范围并不在[ 0,1 ]之间,着点跟归一化不同。
如下其中X代表要转换的对象,[New_max,New_min]代表范围区间。 - 公式
y = X i − m i n m a x − m i n ∗ ( n e w m a x − n e w m i n ) + n e w m i n y= \frac {X_i-min}{max-min}*(new_{max} - new_{min})+new_{min} y=max−minXi−min∗(newmax−newmin)+newmin - 举例
收入范围最低收入12000,最高收入98000,标准化映射到[0,1]之间,现在要将一个人收入是73600进行标准化,应该如何进行映射?
73600 − 12000 = 61600 98000 − 12000 = 86000 ∗ ( 1 − 0 ) + 0 = 0.716 \frac{73600 - 12000=61600} {98000 - 12000=86000} *(1 - 0)+0 = 0.716 98000−12000=8600073600−12000=61600∗(1−0)+0=0.716
z-score标准化
- 特点
将原始数据经过处后的均值为0、标准差为1。假设原始特征的均值为mean 、标准差为\sigma - 公式
X ′ = x − m e a n σ X' = \frac{x-mean}{\sigma} X′=σx−mean
x为带入值,mean为均值、 σ \sigma σ为标准差 - 举例
假设一组指标1,2,3,4计算z-score标准化
m e a n ( 均 值 ) = 1 + 2 + 3 + 4 4 = 2.5 mean(均值) = \frac{1+2+3+4}{4} = 2.5 mean(均值)=41+2+3+4=2.5
σ ( 标 准 差 ) = m e a n 均 值 = ( 1 − 2.5 ) 2 + ( 2 − 2.5 ) 2 + ( 3 − 2.5 ) 2 + ( 4 − 2.5 ) 2 4 − 1 = 1.29 \sigma(标准差) = \sqrt {mean_{均值}} =\sqrt\frac{ (1-2.5)^2+(2-2.5)^2+(3-2.5)^2+(4-2.5)^2}{4-1}=1.29 σ(标准差)=mean均值=4−1(1−2.5)2+(2−2.5)2+(3−2.5)2+(4−2.5)2=1.29
X 第 一 个 指 标 ′ = 1 − 2.5 1.29 = 0.9 X_{第一个指标}'= \frac{1 - 2.5}{1.29}=0.9 X第一个指标′=1.291−2.5=0.9
归一化(normalization)
- 特点
经过归一化处理后,该特征的所有取值都将被压缩到[0,1]间的小数,主要是为了数据处理更加便捷。便于不同量级的指标能够进行比较和加权。
如下min是样本中最小值,max是样本中最大值,x为每一个特征的值 - 公式
y = X i − m i n m a x − m i n y= \frac {X_i-min}{max-min} y=max−minXi−min - 举例
| 代号 | 身高cm | 体重kg | 性别 |
|---|---|---|---|
| A | 175 | 80 | 男 |
| B | 182 | 86 | 男 |
| C | 158 | 49 | 女 |
| D | 163 | 51 | 女 |
| 代号 | 身高(归一化)cm | 体重(归一化)kg | 性别 |
|---|---|---|---|
| A | 0.71 | 0.83 | 男 |
| B | 1 | 1 | 男 |
| C | 0 | 0 | 女 |
| D | 0.20 | 0.05 | 女 |
缺失值处理
-
删除
样本的某一类别特征数据缺失值比例很高的情况,该特征失去意义,此时可以直接剔除该列特征 -
平均值
样本的某一类别特征数据缺失不多的情况下,可以使用中值、平均值方式将数据进行替代 -
预测值
在特征工程中使用机器学习的算法对当前缺失值进行预测插入,这样的好处可以构建相对完整的特征数据
特征选择
样本数据存在大量特征,这些特征中包含了高比例的无用特征,此时通过降纬可以降低特征数量的同时可以保留原始数据的大部分重要信息,降纬的常用方式,可以通过专家经验对数据特征进行干预,也可以通过机器学习的方式,选择方差接近0的,这种数据对区分样本并没有什么帮助。
特征选择
- Filter过滤法:对样本数据进行方差计算,方差越接近0,说明数据越稳定对区分数据越没有帮助,方差等于零说明数据没有区分。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征;
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是通过训练来确定特征的优劣。
最后
本人工作原因文章更新不及时或有错误可以私信我,另外有安全行业在尝试做机器学习的小伙伴可以一起交流,备注优快云。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









