







 本文介绍了朴素贝叶斯算法(NB),它是应用广泛的分类算法,基于贝叶斯定义和特征条件独立假设,有坚实数学基础和稳定分类效率。还给出莺尾花数据集和模拟离散数据集的贝叶斯分类示例,最后分析了该算法优缺点,并提及改进方法。
本文介绍了朴素贝叶斯算法(NB),它是应用广泛的分类算法,基于贝叶斯定义和特征条件独立假设,有坚实数学基础和稳定分类效率。还给出莺尾花数据集和模拟离散数据集的贝叶斯分类示例,最后分析了该算法优缺点,并提及改进方法。
朴素贝叶斯算法(Naive Bayes, NB)
NB是应用最为广泛的分类算法之一。它是基于贝叶斯定义和特征条件独立假设的分类器方法。由于朴素贝叶斯法基于贝叶斯公式计算得到,有着坚实的数学基础,以及稳定的分类效率。NB模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。当年的垃圾邮件分类都是基于朴素贝叶斯分类器识别的。
莺尾花数据集–贝叶斯分类
Step1: 库函数导入
#导入高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
Step2: 数据导入&分析
Step3: 模型训练
Step4: 模型预测
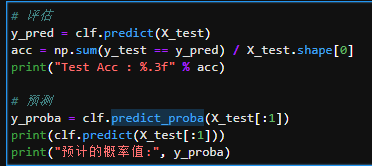
sklearn中predict()与predict_proba()用法区别
predict是训练后返回预测结果,是标签值。
predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
Step5: 原理简析
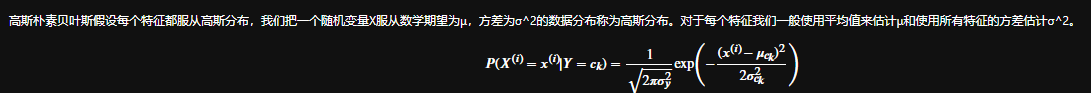
模拟离散数据集–贝叶斯分类
#使用基于类目特征的朴素贝叶斯
from sklearn.naive_bayes import CategoricalNB
朴素贝叶斯算法
朴素贝叶斯法 = 贝叶斯定理 + 特征条件独立。

朴素贝叶斯的优缺点
优点: 朴素贝叶斯算法主要基于经典的贝叶斯公式进行推倒,具有很好的数学原理。而且在数据量很小的时候表现良好,数据量很大的时候也可以进行增量计算。由于朴素贝叶斯使用先验概率估计后验概率具有很好的模型的可解释性。
缺点: 朴素贝叶斯模型与其他分类方法相比具有最小的理论误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进,例如为了计算量不至于太大,我们假定每个属性只依赖另外的一个。解决特征之间的相关性,我们还可以使用数据降维(PCA)的方法,去除特征相关性,再进行朴素贝叶斯计算。

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









