







 本文通过使用PyTorch库实现了一个简单的线性回归模型,详细介绍了从数据准备到模型构建、训练及评估的全过程。通过实际代码演示了如何定义神经网络结构、设置损失函数和优化器,以及如何进行迭代训练并可视化训练过程。
本文通过使用PyTorch库实现了一个简单的线性回归模型,详细介绍了从数据准备到模型构建、训练及评估的全过程。通过实际代码演示了如何定义神经网络结构、设置损失函数和优化器,以及如何进行迭代训练并可视化训练过程。
pytorch实现简单线性回归
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
#引入变量
from torch.autograd import Variable
#linear regression
'''
生成数据x,y
'''
x = [3, 4, 5, 6, 7, 8, 9]
y = [6, 8, 10, 12, 14, 16, 18]
'''
x_用于绘图,因为下面将x转化为可求导的变量,在转化为numpy不能进行绘图
'''
x_ = np.array(x)
'''
转化为floattensor,若转为其他形式无法求导
x,y都要进行转化为变量,y不用可求导
'''
x = torch.FloatTensor(x)
x = x.view(-1,1) #注意此处x,y都要转为(-1,1)张量
x = Variable(x, requires_grad = True)
y = torch.FloatTensor(y)
y = Variable(y)
y = y.view(-1,1)
import matplotlib.pyplot as plt
%matplotlib inline
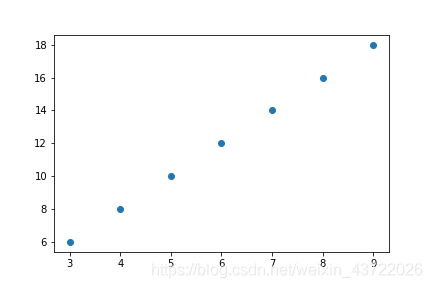
plt.scatter(x_, y.numpy())
#也可以 plt.scatter(x.data.numpy() ,y.numpy())
#绘图时不能用tensor,不能用有求导的tensor来转化
#可以使用x.data.numpy
# .data表示取出内部不求导的tensor
class LinearRegression(nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()
'''
线性回归
'''
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
'''
前向传播
'''
return self.linear(x)
input_size = 1
output_size = 1
model = LinearRegression(input_size, output_size)
mse = nn.MSELoss() #loss
'''
优化器
'''
learning_rate = 3e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
loss列表
训练轮数
'''
loss_list = []
iteration_number = 20000
'''
训练
'''
for iteration in range(iteration_number):
'''
optimizer.zero_grad()对应d_weights = [0] * n
即将梯度初始化为零(因为一个batch的loss关于weight的导数是所有 sampleloss关于weight的导数的累加和)
'''
optimizer.zero_grad()
'''
前向传播求出预测的值
'''
results = model(x) #返回为tensor
'''
计算loss
'''
loss = mse(results, y)
'''
反向传播求梯度
'''
loss.backward()
'''
weights = [weights[k] + alpha * d_weights[k] for k in range(n)]
更新所有参数
'''
optimizer.step()
'''
将loss加入loss列表
'''
loss_list.append(loss.data)
if(iteration % 1000 == 0 ):
print('epoch{}, loss {}'.format(iteration, loss.data))
plt.plot(range(iteration_number), loss_list)
'''
m1: [a x b], m2: [c x d]
m1 is [a x b] which is [batch size x in features]
m2 is [c x d] which is [in features x out features]
'''
'''
绘制预测值和真实值
'''
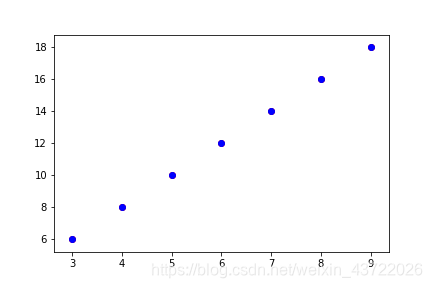
predict = model(x).data.numpy()
plt.scatter(x_, y, color='r')
plt.scatter(x_, predict, color='b')

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









