









 本文详细解析了进程与线程的概念差异,包括资源分配、上下文切换和执行特性。并通过Python代码示例,展示了如何利用多进程加速程序执行,特别是在多核环境下提升效率。
本文详细解析了进程与线程的概念差异,包括资源分配、上下文切换和执行特性。并通过Python代码示例,展示了如何利用多进程加速程序执行,特别是在多核环境下提升效率。
- 线程与进程的区别
- 进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
- 每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
- 在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
- 系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
Python的多线程实际上并不能真正利用多核,所以如果使用多线程实际上还是在一个核上做并发处理。不过,如果使用多进程就可以真正利用多核,因为各进程之间是相互独立的,不共享资源,可以在不同的核上执行不同的进程,达到并行的效果
参考链接:
https://blog.youkuaiyun.com/u011361880/article/details/77923162
https://blog.youkuaiyun.com/kuangsonghan/article/details/80674777
其实说白了就是,在单个cpu上
- 在python上,开辟多个进程,每个进程的任务会齐头并进,不会相互影响;比如,一个任务需要5秒钟,5个进程跑5个任务,即每个进程跑一个任务的话,5秒钟计算机可以同时跑完这5个任务;(前提是保证你的cpu可以开辟多个线程)
- 默认开辟一个进程,在这一个进程里面跑5个线程的时候,没办法同时进行,需要一个线程结束后才能跑下一个线程,因此需要25秒钟。
因此,多进程可以节省很多时间。
那么什么情况下可以使用多线程提高运行速度呢? 当存在多个CPU时候
3.

参考链接:
https://blog.youkuaiyun.com/zollty/article/details/53944539
- 代码示例
import multiprocessing
import time
def func(i):
time.sleep(5) #休眠5秒钟,然后继续执行下面的代码
print(i)
if __name__ == "__main__":
start=time.time()
pool = multiprocessing.Pool(processes=4) # 通过Pool创建4个进程
for i in range(4):
pool.apply_async(func, (i, )) #传递函数,和函数参数,函数参数用元组表示
pool.close() # 关闭进程池,表示不能在往进程池中添加进程
pool.join() # 等待进程池中的所有进程执行完毕,必须在close()之后调用
print('total cost time:', time.time()-start)
运行结果如下:调用四次函数,每次调用需要5秒钟,4个任务完成只需要5秒钟左右。
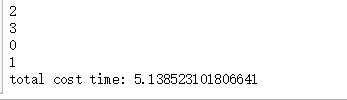
另外需要注意:
上面代码在 Jupyter notebook上运行的时候,可以输出 0 1 2 3,即函数内部的结果可以直接输出在屏幕上;
但是在spyder上运行该程序时,上面的0 1 2 3 4,似乎并没有输出结果。这是因为可能在spyder上只支持返回程序运行结果的值,而不支持直接输出;
如下图:无输出结果。
import multiprocessing
import time
def func(i):
time.sleep(4) #休眠4秒钟
i=i*3
return i
if __name__ == "__main__": #需要注意,windows系统下的多进程需要在 __name__=='__main__':下运行
'''
偶尔会出现报错信息:AttributeError: module '__main__' has no attribute '__spec__'
这个时候记得在 if __name__=='__main__': 下面加上一行:
__spec__ = "ModuleSpec(name='builtins', loader=<class '_frozen_importlib.BuiltinImporter'>)"
'''
#__spec__ = "ModuleSpec(name='builtins', loader=<class '_frozen_importlib.BuiltinImporter'>)"
start=time.time()
results=[]
pool = multiprocessing.Pool(processes=4) # 创建4个进程
for i in range(4):
results.append(pool.apply_async(func, (i, ))) #将每个进程的运行结果添加到列表中
pool.close() # 关闭进程池,表示不能在往进程池中添加进程
pool.join() # 等待进程池中的所有进程执行完毕,必须在close()之后调用
# print ("Sub-process(es) done.")
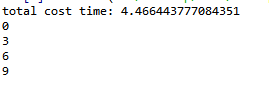
print('total cost time:', time.time()-start)
for res in results: #输出函数运行结果
print(res.get())
运行结果如下:
在平时进行大量的循环的时候,可以尝试将循环拆分成为多个进程来跑,这样可以成倍的减少时间。
更多的用法可以参考以下链接:
https://blog.youkuaiyun.com/jinping_shi/article/details/52433867
https://www.cnblogs.com/kaituorensheng/p/4445418.html
另外,除了multiprocessing.Pool外,multiprocessing.Process模块也能实现多进程,可参考下面链接:
https://blog.youkuaiyun.com/qq_29750277/article/details/81031468
https://www.cnblogs.com/kaituorensheng/p/4445418.html
2019.09.30 -----更新
假如你要以同样的方式处理10个文件,并且在处理每个文件的时候,都需要另一个共同的文件A的参与。
这个时候,在进行多进程:
pool.apply_async(func, (i, A )) 的时候
不能先把文件A读取进来,再传入func中,这样会导致读取进来的文件A分身乏术。没办法进行多进程。
而是应该直接把文件A的路径传入func中,在func中进行读取。也就是说,每次调用一个func的时候,都再读取一次文件A。
这是泪的教训!

















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









