




计算
YOLOv8确实取消了置信度,
因此每个像素点需要预测的参数总数为类别数加上边界框的参数。具体来说:
假如有
类别:9个类别,需要9个参数来表示每个目标属于每个类别的概率。
位置:4个参数来表示目标的边界框(x, y, w, h)。
因此,每个像素点需要预测的参数总数为9(类别)+ 4(位置)= 13个参数。
假设输入图像的大小为640x640像素,那么输出的三个特征图的大小分别为80x80、40x40和20x20。因此,
YOLOv8-nano的输出大小为:
80x80x13
40x40x13
20x20x13
这些输出特征图包含了模型对输入图像中目标的检测结果,包括目标的类别和位置等信息.
如何推理
preprocess
代码解释
以下是对preprocess函数的详细解释,包括每一行代码的功能和作用:
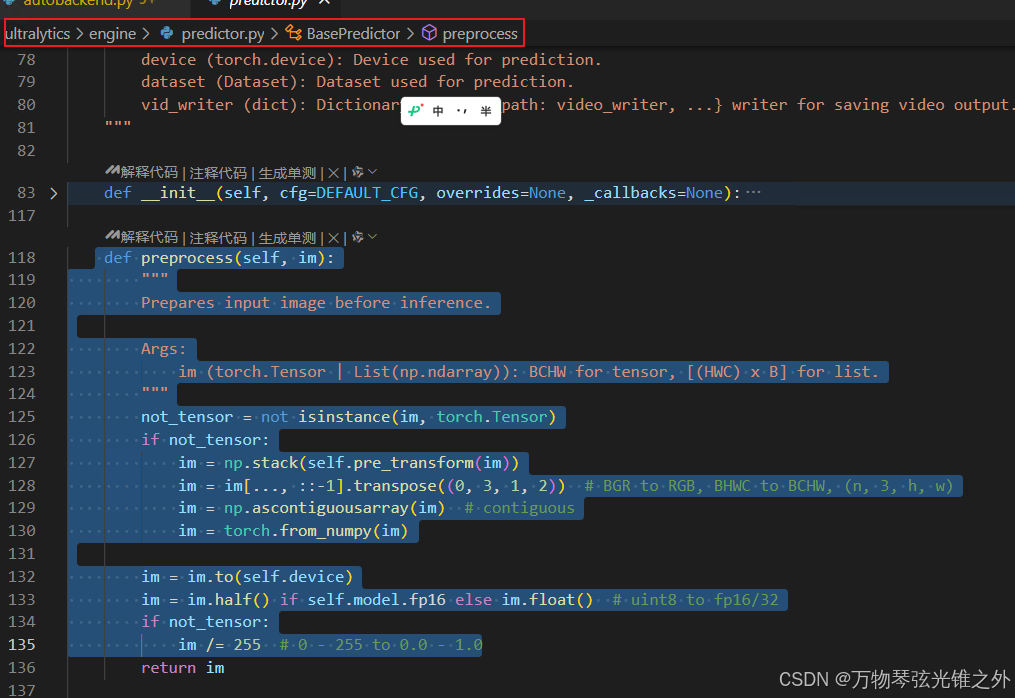
def preprocess(self, im)::定义preprocess方法,用于在推理前准备输入图像。not_tensor = not isinstance(im, torch.Tensor):检查输入图像是否为torch.Tensor类型。if not_tensor::如果输入图像不是torch.Tensor类型,则进行以下操作。im = np.stack(self.pre_transform(im)):将输入图像转换为NumPy数组并进行预处理。im = im[..., ::-1].transpose((0, 3, 1, 2)):将图像从BGR格式转换为RGB格式,并将维度从BHWC转换为BCHW。im = np.ascontiguousarray(im):确保图像数组是连续的。im = torch.from_numpy(im):将NumPy数组转换为torch.Tensor。
im = im.to(self.device)
im = im.half() if self.model.fp16 else im.float() # uint8 to fp16/32
if not_tensor:
im /= 255 # 0 - 255 to 0.0 - 1.0
return im
im = im.to(self.device):将图像数据移动到指定的设备(例如GPU)。im = im.half() if self.model.fp16 else im.float():如果模型使用FP16精度,则将图像数据转换为FP16,否则转换为FP32。if not_tensor::如果输入图像不是torch.Tensor类型,则进行以下操作。im /= 255
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











