







 该实验旨在利用Python的sklearn库实现线性回归模型,对data_singlevar.txt数据集进行训练和测试。首先,数据被读取并分割为训练集和测试集。接着,使用训练数据训练线性回归模型,并通过matplotlib可视化训练数据的拟合情况。最后,模型在测试集上进行预测,绘制预测结果,并计算均方误差以评估模型性能。
该实验旨在利用Python的sklearn库实现线性回归模型,对data_singlevar.txt数据集进行训练和测试。首先,数据被读取并分割为训练集和测试集。接着,使用训练数据训练线性回归模型,并通过matplotlib可视化训练数据的拟合情况。最后,模型在测试集上进行预测,绘制预测结果,并计算均方误差以评估模型性能。
实验内容
给定一个数据集合data_singlevar.txt。目标是找到一个线性模型可以将这些数据拟合。我们称之为线性回归,同时通过计算它的均方误差来评价拟合的好坏。
在命名时,singlevar表示y的值x确定,这里的x仅包含一个属性。
实验准备
源文件和数据集请前往百度网盘下载
链接:https://pan.baidu.com/s/1eXQvwhsr4E4CIpyy4qoPiQ
提取码:891j
复制这段内容后打开百度网盘手机App,操作更方便哦
实验步骤
- 使用Pycharm创建工程,将数据集data_singlevar.txt和源文件LinearRegressor.py放到同一个文件夹中。
这样做的好处有二:
(1)可以直接使用相对路径,缩短路径长度,同时如果移动项目文件夹,不需要修改源代码,具有更好的可移植性。
(2)使用Pycharm可以很好的定位到该数据集,可以检查出自己是不是写错了,如下图
- 主要代码及注释讲解
#创建线性回归器
import numpy as np
filename = r"data_singlevar.txt"
x = []
y = []
#读取数据集中的数据,并将自变量x和因变量y分开放到两个不同的列表中
with open(filename,'r') as f:
for line in f.readlines():
data = [float(i) for i in line.split(',')]
xt, yt = data[:-1],data[-1]
x.append(xt)
y.append(yt)
#将data分为两组,训练数据集,测试数据集
num_training = int(0.8*len(x)) #训练数据占80%
num_test = len(x) - num_training
#训练数据
x_train = np.array(x[:num_training])
y_train = np.array(y[:num_training])
#测试数据
x_test = np.array(x[num_training:])
y_test = np.array(y[num_training:])
#准备好训练数据和测试数据后,接下来创建一个回归器对象
from sklearn import linear_model
#创建线性回归对象
linear_regressor = linear_model.LinearRegression()
#用训练数据集训练模型,向fit方法中提供输入数据即可
linear_regressor.fit(x_train,y_train)
#进行拟合
import matplotlib.pyplot as plt
y_train_pred = linear_regressor.predict(x_train)
plt.figure()
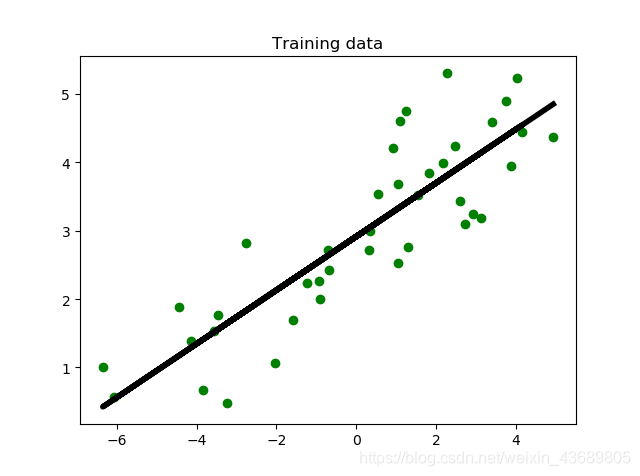
plt.scatter(x_train,y_train,color='green')
plt.plot(x_train, y_train_pred,color="black",linewidth=4)
plt.title("Training data")
plt.show()
#然后使用测试数据集进行预测,并画出来
y_test_pred = linear_regressor.predict(x_test)
plt.figure()
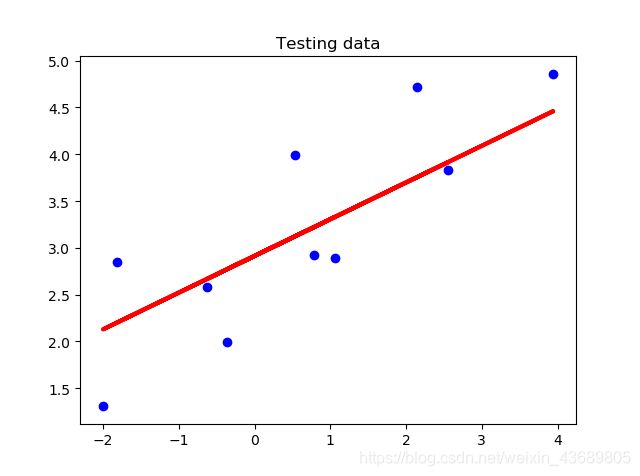
plt.scatter(x_test,y_test,color='blue')
plt.plot(x_test, y_test_pred, color = 'red',linewidth=3)
plt.title("Testing data")
plt.show()
#使用均方误差评价模型的抗扰动性
import sklearn.metrics as sm
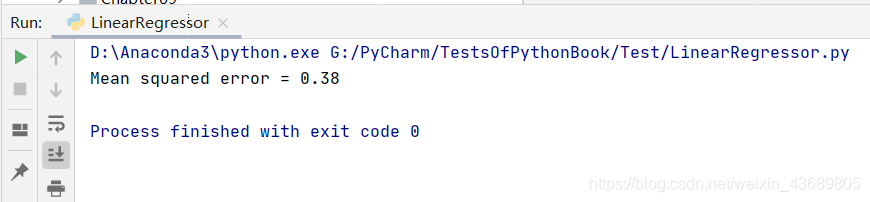
print("Mean squared error(均方误差) =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
步骤总结
- 导入数据集和相关包
- 读取数据将其放入numpy数组中
- 使用sklearn中的线性模型拟合数据,得到一个线性模型
- 使用matplotlib.pyplot画图
- 用测试集进行测试
- 使用均方误差等评价模型的好坏
答疑
- 得到的线性模型包含了所有的参数,例如y = ax + b中的a,b的值,所有的参数都在训练得到的线性模型对象中,我们没有必要必须知道它的数值
实验结果
使用训练集拟合到的线性模型
使用测试集进行测试
输出均方误差


















 1369
1369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











