







 本文介绍了图的基础概念,包括无环无向图、三种图的表示方法:邻接矩阵、关联矩阵和邻接表。重点讲解了Python中实现广度优先搜索(BFS)和深度优先搜索(DFS)的算法,包括相关数据结构如栈和队列的实现,以及使用邻接表描述图。此外,还展示了BFS在求解最短路径问题上的应用。
本文介绍了图的基础概念,包括无环无向图、三种图的表示方法:邻接矩阵、关联矩阵和邻接表。重点讲解了Python中实现广度优先搜索(BFS)和深度优先搜索(DFS)的算法,包括相关数据结构如栈和队列的实现,以及使用邻接表描述图。此外,还展示了BFS在求解最短路径问题上的应用。
文章目录
一. 基础概念:
图的数学表述为 G = ( V , E ) G=(V,E) G=(V,E),即图是由一组顶点和一组边构成,例如:
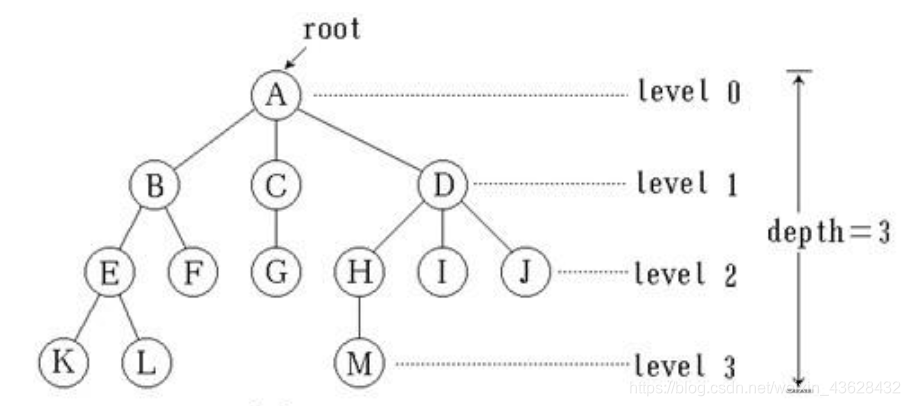
相关概念如下:
- 相邻节点;
- 度:相邻节点的个数;
- 路径:从某个节点到另一个节点的连续序列;
- 简单路径:无重复节点的路径;
- 无环的;
- 连通的:每两个节点之间都存在路径;
- 无向的;
- 有向的;
- 加权的;
- 未加权的;
- 强连通的:对于有向图,每两个顶点之间都存在双向的路径;
例如上面的例子中展现的就是一张无环的、无向的、未加权的、连通的图,这样的图里任意两个节点间都存在简单路径。
* 图的三种表示方法:
1. 邻接矩阵:
a r r a y [ i ] [ j ] = { 1 , i 与 j 为 相 邻 顶 点 ; 0 , i 与 j 不 相 邻 ; array[i][j] = \begin{cases} 1, & i与j为相邻顶点; \\ 0, & i与j不相邻; \end{cases} array[i][j]={ 1,0,i与j为相邻顶点;i与j不相邻;
容易得到对于邻接矩阵 M M M, M T = M M^T = M MT=M。
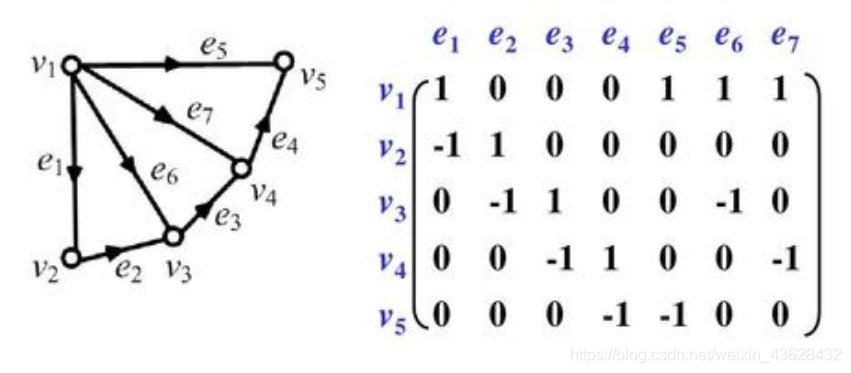
2. 关联矩阵:
a r r a y [ v ] [ e ] = { 1 , v 是 e 的 入 射 点 ; 0 , v 不 是 e 的 入 射 点 ; array[v][e] = \begin{cases} 1, & v是e的入射点; \\ 0, & v不是e的入射点; \end{cases} array[v][e]={ 1,0,v是e的入射点;v不是e的入射点;
对于有向图可稍作修改,例如
3. 邻接表:
邻接表最简单的描述方式是使用字典,以某顶点为键,以该顶点的相邻顶点为值即可。例如最开始的例子中的图可以表示为一个Python字典:
{
A:[B,C,D],
B:[A,E,F],
C:[A,G],
D:[A,H,I,J],
E:[B,K,L],
F:[B],
G:[C],
H:[D,M],
I:[D],
J:[D],
K:[E],
L:[E],
M:[H]
}
后面我们将采用这种方式实现图,进而使用BFS与DFS算法遍历图中的节点。
二. 广度优先搜索BFS:
广度优先搜索是一种对图进行遍历的算法,其遍历思想是“先宽后深”,优先访问同一层的节点;而深度优先搜索的遍历思想则是“先深后宽”,从指定顶点开始,沿着某条路径直到这条路径的最后一个节点,再原路退回,探索下一条路径。
对于这两种算法,我们其实只需要将队列应用到BFS中、将栈应用到DFS中,即可非常相似的实现两种算法。这一点我们后续可以更清楚的看到。那么首先让我们实现简单的栈和队列:
1. 实现栈和队列:
栈和队列的构建都很简单,我们使用Python提供的列表存储数据,然后遵守相应的“先进后出”、“先进先出”原则定义入栈/出栈、入队/出队的方法即可。最后,我们需要一个方法动态获取栈/队列的长度,将size定义为方法而不是属性可以简化代码、避免手动更新size属性。
代码如下:
class MyQueue(object):
'''
构建队列
'''
def __init__(self):
self.myQueue = []
def push(self,item):
self.myQueue.append(item)
return self.myQueue
def pop(self):
return self.myQueue.pop(0)
def size(self):
'''
将队列的大小动态定义为方法,其它方法中无需对其进行显示更新
'''
return len(self.myQueue)
class MyStack(object):
'''
构建栈
'''
def __init__(self):
self.myStack = []
def push(self,item):
self.myStack.append(item)
return self.myStack
def pop(self):
return self.myStack.pop(len(self.myStack) - 1) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2563
2563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









