






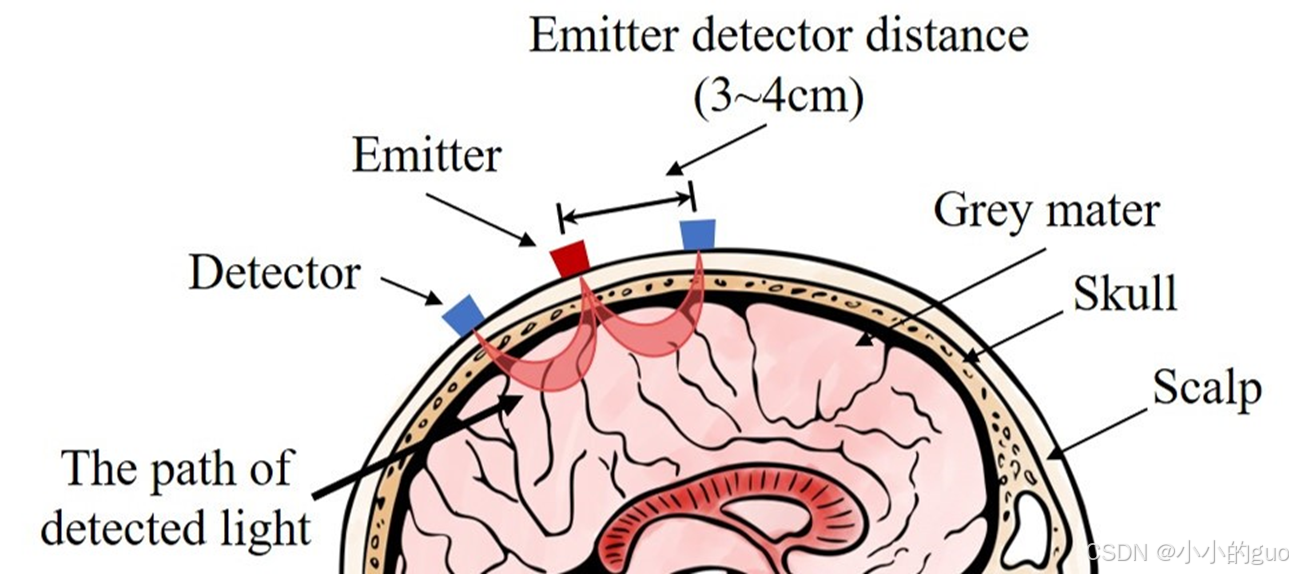
fNIRS(functional near-infrared spectroscopy)功能性近红外光谱成像也称近红外脑功能成像等。简单理解就是由一个发射器(光源)发出近红外光穿过头皮、颅骨等组织,然后被探测器(接收器)接收到,经过这一类似香蕉状的传输后,被吸收量用于计算大脑皮层血红蛋白浓度变化。
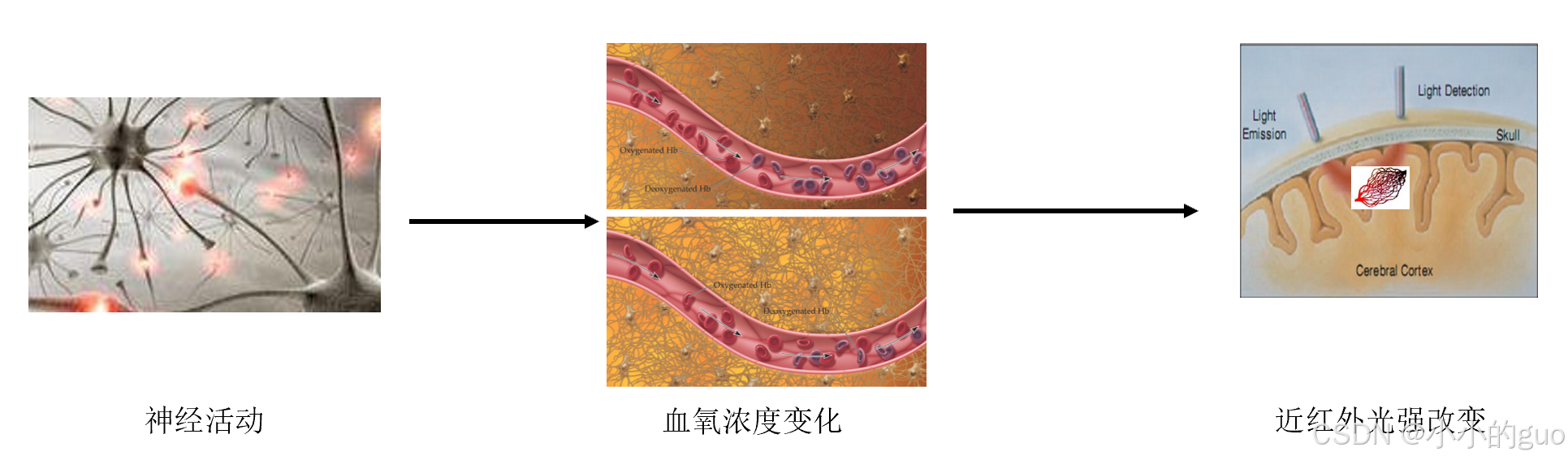
众所周知,氧气是我们身体组织所必须的,是一切生命活动的基础。人体器官中的所有细胞都对氧气有着持续但不稳定的需求。但人体对氧气的储存却微乎其微,是通过血液循环向组织持续供应充足的氧气。组织中氧运输的主要载体是血红蛋白,它由含氧血红蛋白(HbO)和脱氧血红戴白(HbR)组成。随着人体组织的有氧代谢,HbO和HbR的含量不断变化,因此组织中血氧含量的变化能够反映出人体生理状态、细胞活动变化以及各组织结构的功能情况。
fNIRS测量的对象并非是神经元活动本身,而是神经元活动相关的能量代谢产物。而神经元活动所需的能量几乎全部是葡糖糖有氧代谢实时供给,因此代谢所需的葡糖糖和氧气必须有血供系统不间断供给给大脑。基线条件下,大脑组织中HbO以一定的比率释放携带的氧气,并转换为HbR,其释放的氧气被细胞吸收用于基础代谢过程。当受到外界刺激时,神经元活动增加,对应区域的代谢活动也增加,血流会携带更多的氧,将超过局部神经元的耗氧量,造成激活区的脑血氧量大大增加,局部组织血液中的HbO过剩(也即过补偿效应)。经过这一系列变化,脑活动所引起的变化最后通常表现为血液中HbO增加,HbR减少。这种发生在局部脑组织中的神经活动继而引发的血供系统的变化过程称为神经血管耦合过程。
计算原理:
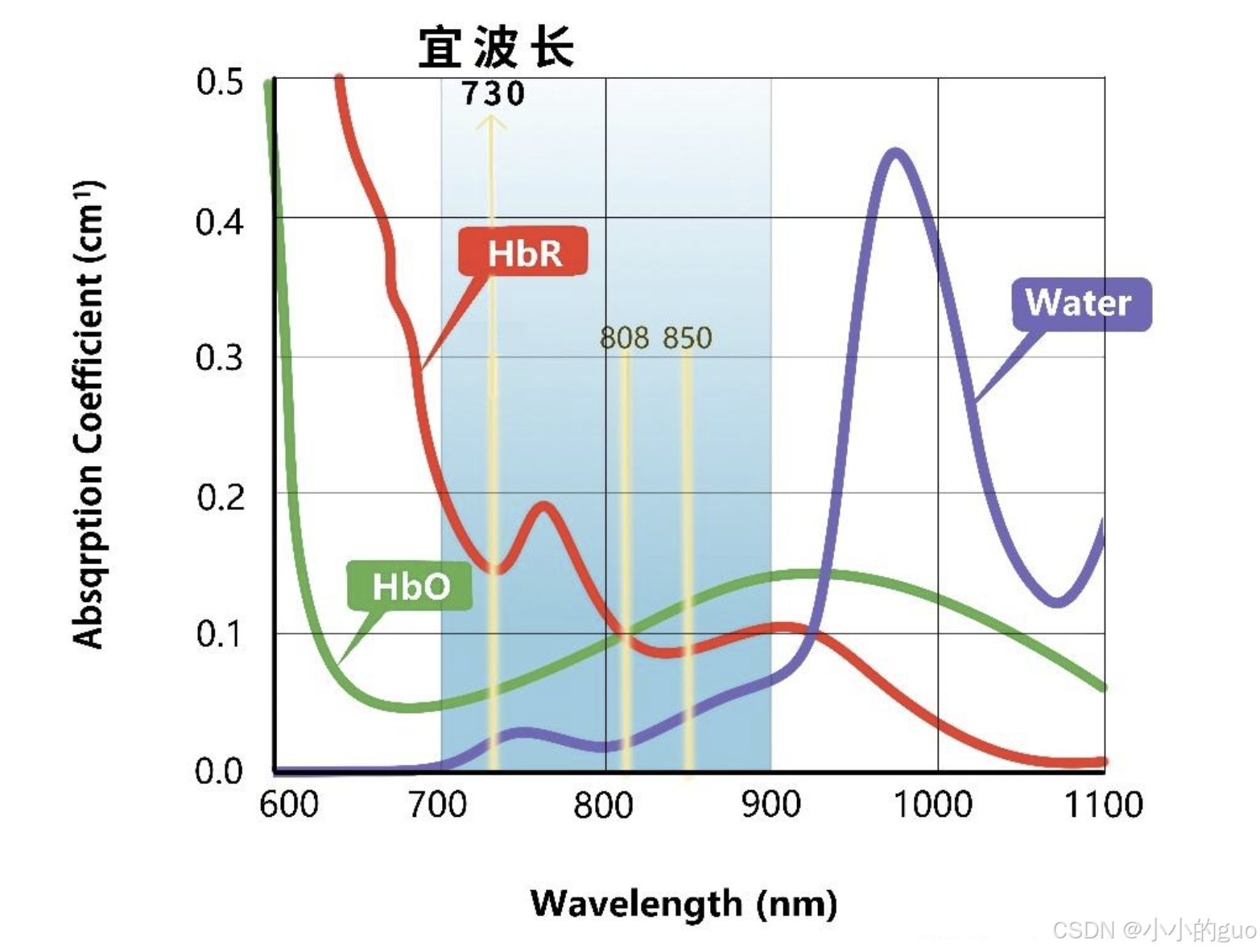
不同品牌的近红外设备选择的光波长略有不同,但无论如何选择,双波长设备都会在HbO和HbR等吸收点(约800nm)的两侧各选一个,如常见的(760nm和850nm,690nm和830等等)。
朗伯-比尔定量是描述光吸收的基本物理定律,描述了吸收率与物体厚度、吸光系数以及浓度之间的关系。人体组织不是均匀介质,光在传播过程中除了吸收还有散射作用。散射效应会使光在组织中穿行的路径发生变化,整体呈现香蕉型。因此,出现了修正后的朗伯-比尔定律:

对于修正的朗伯-比尔定律,G是一个未知量,我们可以列出两个时间点的方程,两式相减即可消除G,得到OD相对变化量:(式中,∆OD可以测出,ε、DPF、L已知)
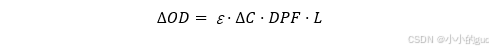
计算∆OD:

计算HbO和HbR浓度:
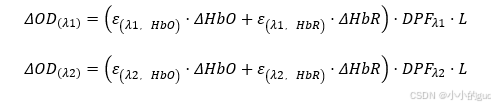
将2式ΔHbR代入1式,得出结果:
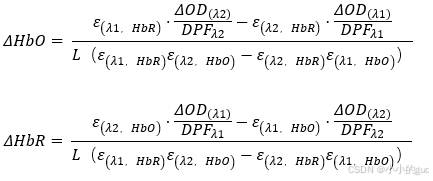

















 4050
4050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









