




 这篇博客详细介绍了ORB SLAM2中的Mono_kitti追踪流程,包括Tracking、ORBextractor的实例化、TrackMonocular函数的使用,特别是GrabImageMonocular和CurrentFrame的构造。在ORB特征提取过程中,文章探讨了ComputePyramid和ComputeKeyPointsOctTree的实现,以及如何通过四叉树结构确保关键点的均匀分布。
这篇博客详细介绍了ORB SLAM2中的Mono_kitti追踪流程,包括Tracking、ORBextractor的实例化、TrackMonocular函数的使用,特别是GrabImageMonocular和CurrentFrame的构造。在ORB特征提取过程中,文章探讨了ComputePyramid和ComputeKeyPointsOctTree的实现,以及如何通过四叉树结构确保关键点的均匀分布。
ORB SLAM2学习笔记之mono_kitti(三)
一、Tracking流程
大致流程如图所示,下面对细节进行展开说明。
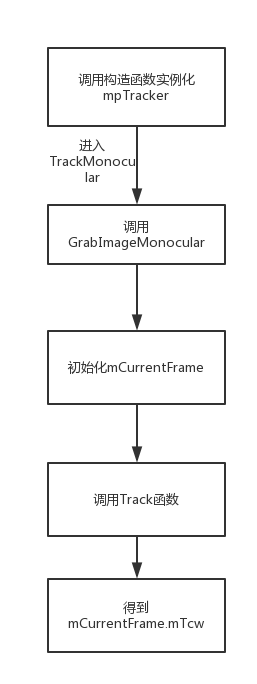
二、实例化mpTracker
在System构造函数中new一个Tracing对象指针mpTracker,方式如下所示:
//Initialize the Tracking thread
//(it will live in the main thread of execution, the one that called this constructor)
mpTracker = new Tracking(this, mpVocabulary, mpFrameDrawer, mpMapDrawer,
mpMap, mpKeyFrameDatabase, strSettingsFile, mSensor);
构造对象过程中,先进行了传参,如camera焦距,畸变系数,帧率等,然后读取配置文件里的有关提取特征方面的信息,比如每一帧需要提取的特征数(包括整个图像金字塔),金字塔层间尺度,金字塔层数,FAST关键点阈值等,最重要的是最后调用了ORBextractor构造一个ORB特征提取器。
mpIniORBextractor = new ORBextractor(2*nFeatures,fScaleFactor,nLevels,fIniThFAST,fMinThFAST);
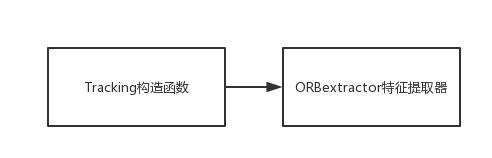
那构造特征提取器时都干了些什么呢,如下所示:
ORBextractor
第一步:算金字塔每层的尺度,然后根据尺度计算每层应该提取多少特征点,这里面涉及了一个等比数列,唤起高中的记忆,还挺有意思的。最后,保证提取总特征点数≥ nfeatures。
//参数:特征点多少,金字塔层与层之间的尺度(用于算每层提取关键点的数量),金字塔层级数量,FAST角点阈值,最小角点阈值
ORBextractor::ORBextractor(int _nfeatures, float _scaleFactor, int _nlevels,
int _iniThFAST, int _minThFAST):
nfeatures(_nfeatures), scaleFactor(_scaleFactor), nlevels(_nlevels),
iniThFAST(_iniThFAST), minThFAST(_minThFAST)
{
mvScaleFactor.resize(nlevels);
mvLevelSigma2.resize(nlevels);
mvScaleFactor[0]=1.0f;
mvLevelSigma2[0]=1.0f;
for(int i=1; i<nlevels; i++)
{
mvScaleFactor[i]=mvScaleFactor[i-1]*scaleFactor;
mvLevelSigma2[i]=mvScaleFactor[i]*mvScaleFactor[i];
}
mvInvScaleFactor.resize(nlevels);
mvInvLevelSigma2.resize(nlevels);
for(int i=0; i<nlevels; i++)
{
mvInvScaleFactor[i]=1.0f/mvScaleFactor[i];
mvInvLevelSigma2[i]=1.0f/mvLevelSigma2[i];
}
mvImagePyramid.resize(nlevels);//金字塔有几层
mnFeaturesPerLevel.resize(nlevels);
float factor = 1.0f / scaleFactor; //梯度q
//第一层特征点的数量 nfeatures是总特征点的数量 后面的式子是等比数列求和公式 nfeatures × (1-q)/(1 - q^n)
float nDesiredFeaturesPerScale = nfeatures*(1 - factor)/(1 - (float)pow((double)factor, (double)nlevels));
//依次算每层的特征点数量,加和,保证最后总的特征点数量 ≥ nfeatures
int sumFeatures = 0;
for( int level = 0; level < nlevels-1; level++ )
{
mnFeaturesPerLevel[level] = cvRound(nDesiredFeaturesPerScale);
sumFeatures += mnFeaturesPerLevel[level];
nDesiredFeaturesPerScale *= factor;
}
mnFeaturesPerLevel[nlevels-1] = std::max(nfeatures - sumFeatures, 0);
第二步:准备制作描述子,包括采用bit_pattern_31_模板,计算像素点半径什么的,有点opencv源码的知识,没太看懂,不能钻牛角尖。。。有大神看懂下面的代码能给我讲一哈吗,求带求带
/*!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!复制训练用的模板!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!*/
const int npoints = 512;//512个点,256对点,比较完会有一个256位的描述子
const Point* pattern0 = (const Point*)bit_pattern_31_;//??? bit_pattern_31_可能的意思是描述子的计算区域直径是 31 的模式
//std::copy(start, end, std::back_inserter(container)); 从 start 到 end 的迭代器复制完放入 container 的后面
std::copy(pattern0, pattern0 + npoints, std::back_inserter(pattern));
//This is for orientation
// pre-compute the end of a row in a circular patch
umax.resize(HALF_PATCH_SIZE + 1);
int v, v0, vmax = cvFloor(HALF_PATCH_SIZE * sqrt(2.f) / 2 + 1); //cvFloor含义是取不大于参数的最大整数值
int vmin = cvCeil(HALF_PATCH_SIZE * sqrt(2.f) / 2); //cvCeil含义是取不小于参数的最小整数值
//?????????????????????????????????????????????????????????????????????????????????????????????????
const double hp2 = HALF_PATCH_SIZE*HALF_PATCH_SIZE; //半径的平方
for (v = 0; v <= vmax; ++v)
umax[v] = cvRound(sqrt(hp2 - v * v));
// Make sure we are symmetric
for (v = HALF_PATCH_SIZE, v0 = 0; v >= vmin; --v)
{
while (umax[v0] == umax[v0 + 1])
++v0;
umax[v] = v0;
++v0;
}
三、TrackMonocular
如果忽略其他线程的构造,就继续回到main函数里,看得出main函数里很重要的就是这个TrackMonocular了,函数体如下所示:
cv::Mat System::TrackMonocular(const cv::Mat &im, const double ×tamp)
{
if(mSensor!=MONOCULAR)
{
cerr << "ERROR: you called TrackMonocular but input sensor was not set to Monocular." << endl;
exit(-1);
}
// Check mode change
{
unique_lock<mutex> lock(mMutexMode);
if(mbActivateLocalizationMode)
{
mpLocalMapper->RequestStop();
// Wait until Local Mapping has effectively stopped
while(!mpLocalMapper->isStopped())
{
usleep(1000);
}
mpTracker->InformOnlyTracking(true);
mbActivateLocalizationMode = false;
}
if(mbDeactivateLocalizationMode)
{
mpTracker->InformOnlyTracking(false);
mpLocalMapper->Release();
mbDeactivateLocalizationMode = false;
}
}
// Check reset
{
unique_lock<mutex> lock(mMutexReset);
if(mbReset)
{
mpTracker->Reset();
mbReset = false;
}
}
cv::Mat Tcw = mpTracker->GrabImageMonocular(im,timestamp);
unique_lock<mutex> lock2(mMutexState);
mTrackingState = mpTracker->mState;
mTrackedMapPoints = mpTracker->mCurrentFrame.mvpMapPoints;
mTrackedKeyPointsUn = mpTracker->mCurrentFrame.mvKeysUn;
return Tcw;
}
看得出这个函数调用完会返回一个Mat类的东西,就是Tcw位姿。函数刚开始先check了一下系统现在是不是LocalizationMode,有没有Reset,用了mutex大概是为了防止不同线程访问共享内存从而出错,并发编程这里还不是很懂,也没有什么具体资料,等学会以后会更新一下,还请大神走过路过赐教一下鸭…接下来进入GrabImageMonocular函数,计算都是在这里进行的。
GrabImageMonocular
函数需要两个参数:图片和对应的时间戳。先进行图片格式的转换,然后构造了CurrentFrame,最后进行Track。
cv::Mat Tracking::GrabImageMonocular(const cv::Mat &im, const double ×tamp)
{
mImGray = im;
//根据传入图片的不同情况转换图片格式
if(mImGray.channels()==3)
{
if(mbRGB)
cvtColor(mImGray,mImGray,CV_RGB2GRAY);
else
cvtColor(mImGray,mImGray,CV_BGR2GRAY);
}
else if(mImGray.channels()==4)
{
if(mbRGB)
cvtColor(mImGray,mImGray,CV_RGBA2GRAY);
else
cvtColor(mImGray,mImGray,CV_BGRA2GRAY);
}
if(mState==NOT_INITIALIZED || mState==NO_IMAGES_YET) //之前Tracking构造函数的时候,已经将mState初始化为NO_IMAGES_YET
mCurrentFrame = Frame(mImGray,timestamp,mpIniORBextractor,mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);
else
mCurrentFrame = Frame(mImGray,timestamp,mpORBextractorLeft,mpORBVocabulary,mK,mDistCoef,mbf,mThDepth);
Track();
return mCurrentFrame 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









