







 本文深入解析Faster R-CNN算法,涵盖特征提取、候选区域生成、分类与回归等核心模块。阐述RPN网络作用及流程,探讨非极大值抑制技术,详细描述算法训练与测试过程。
本文深入解析Faster R-CNN算法,涵盖特征提取、候选区域生成、分类与回归等核心模块。阐述RPN网络作用及流程,探讨非极大值抑制技术,详细描述算法训练与测试过程。
转载,仅供自己学习,侵删。
一、 算法详解:
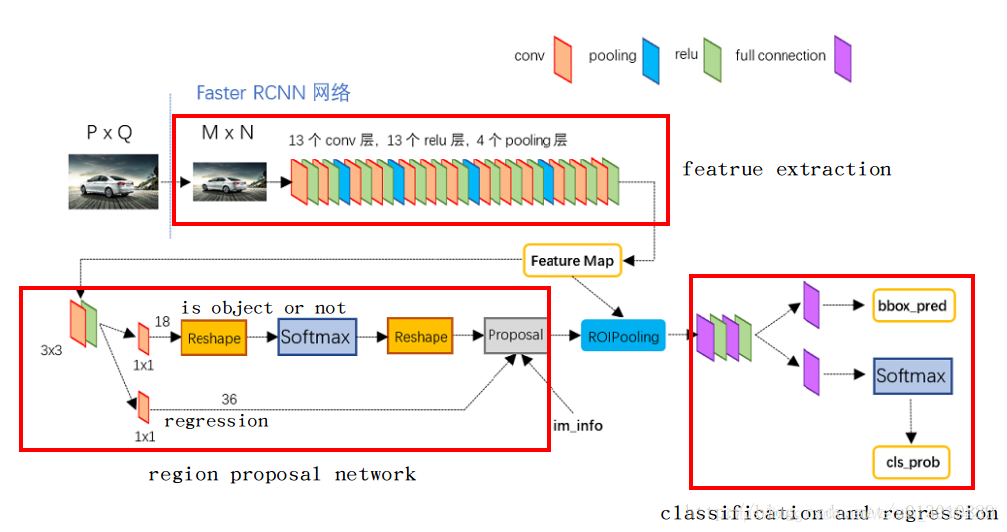
Faster-rcnn主要包括4个关键模块,特征提取网络、生成ROI、ROI分类、ROI回归。
- 特征提取网络:它用来从大量的图片中提取出一些不同目标的重要特征,通常由conv+relu+pool层构成,常用一些预训练好的网络(VGG、Inception、Resnet等),获得的结果叫做特征图feature map;
- 生成ROI(RPN):在获得的特征图的每一个点上(一共的点数时feature map的大小)做多个候选ROI(这里是9),然后利用分类器将这些ROI区分为背景和前景,同时利用回归器对这些ROI的位置进行初步的调整;
- ROI分类:在RPN阶段,用来区分前景(于真实目标重叠并且其重叠区域大于0.5)和背景(不与任何目标重叠或者其重叠区域小于0.1);在Fast-rcnn阶段,用于区分不同种类的目标(猫、狗、人等);
- ROI回归:在RPN阶段,进行初步调整;在Fast-rcnn阶段进行精确调整;
Faster-rcnn中的核心问题
• 1. 提出了“RPN”网络,在提高精度的同时提高了速度;
• 2. RPN网络和Fast-rcnn网络的特征共享与训练;
• 3. 使用了ROI Pooling技术 ;
• 4. 使用了NMS技术;
总之,其整体流程如下所示:
• 首先对输入的图片进行裁剪操作,并将裁剪后的图片送入预训练好的分类网络中获取该图像对应的特征图;
• 然后在特征图上的每一个锚点上取9个候选的ROI(3个不同尺度,3个不同长宽比),并根据相应的比例将其映射到原始图像中(因为特征提取网络一般有conv和pool组成,但是只有pool会改变特征图的大小,因此最终的特征图大小和pool的个数相关);
• 接着将这些候选的ROI输入到RPN网络中,RPN网络对这些ROI进行分类(即确定这些ROI是前景还是背景)同时对其进行初步回归(即计算这些前景ROI与真实目标之间的BB的偏差值,包括Δx、Δy、Δw、Δh),然后做NMS(非极大值抑制,即根据分类的得分对这些ROI进行排序,然后选择其中的前N个ROI);
• 接着对这些不同大小的ROI进行ROI Pooling操作(即将其映射为特定大小的feature_map,文中是7x7),输出固定大小的feature_map;
• 最后将其输入简单的检测网络中,然后利用1x1的卷积进行分类(区分不同的类别,N+1类,多余的一类是背景,用于删除不准确的ROI),同时进行BB回归(精确的调整预测的ROI和GT的ROI之间的偏差值),从而输出一个BB集合。
二、RPN网络
1.RPN的意义
RPN第一次出现在世人眼中是在Faster RCNN这个结构中,专门用来提取候选框,在RCNN和Fast RCNN等物体检测架构中,用来提取候选框的方法通常是Selective Search,是比较传统的方法,而且比较耗时,在CPU上要2s一张图。所以作者提出RPN,专门用来提取候选框,一方面RPN耗时少,另一方面RPN可以很容易结合到Fast RCNN中,称为一个整体。RPN的引入,可以说是真正意义上把物体检测整个流程融入到一个神经网络中,这个网络结构叫做Faster RCNN; Faster RCNN = RPN + Fast RCNN
2、基础
(1)锚点
即特征图上的最小单位点,比如原始图像的大小是256x256,特征提取网络中含有4个pool层,然后最终获得的特征图的大小为 256/16 x 256/16,即获得一个16x16的特征图,该图中的最小单位即是锚点,由于特征图和原始图像之间存在比例关系,在特征图上面密集的点对应到原始图像上面是有16个像素的间隔,也就是特征图上的一个点实际上对应原图中的一个框。如下图所示:
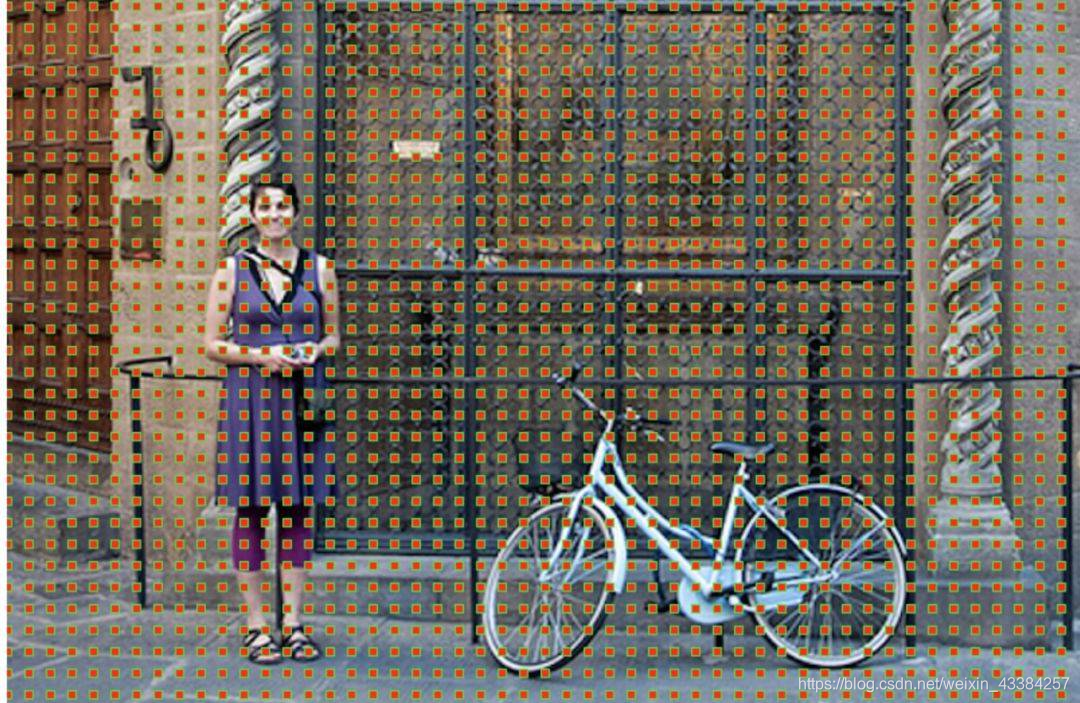
(2)候选的ROI
针对每一个锚点,然后根据不同的尺度(128、256、512pixel)和不同的长宽比(1:1、0.5:1、1:0.5)产生9个BB,如下图所示,对于16x16的特征图,最终产生16x16x9个候选的ROI。

左侧:锚点、中心:特征图空间单一锚点在原图中的表达,右侧:所有锚点在原图中的表达
假定输出特征图为13x13x256,然后在该特征图上进行3x3x256的卷积,默认进行了边界填充。
那么每一个特征图上一共有13x13=169个像素点,由于采用了边界填充,所以在进行3x3卷积的时候,每一个像素点都可以做一次3x3卷积核的中心点,那么整个卷积下来相当于是有169个卷积中心,这169个卷积中心在原始图像上会有169个对应的锚点,然后每个锚点会有9个默认大小的基本候选框,这样相当于原始图像中一共有169x9=1521个候选框,这1521个候选框有9种不同的尺度,中心又到处都分布,所以足以覆盖了整个原始图像上所有的区域,甚至还有大量的重复区域。
3、RPN具体
我们先来看看Faster RCNN原文中的图:
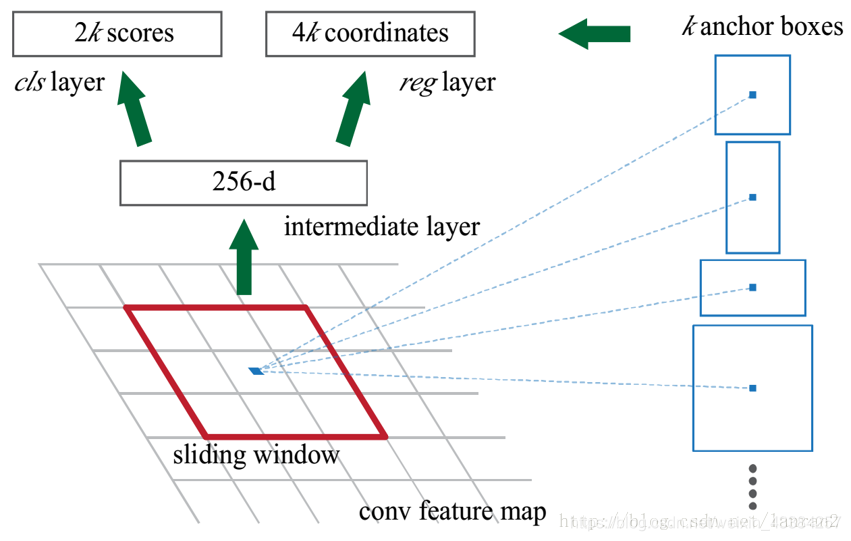
一个特征图经过sliding window处理,得到256维特征,然后通过两次全连接得到结果2k个分数和4k个坐标。
- RPN的input 特征图指的是哪个特征图?
RPN的输入特征图就是卷积得到的Feature Map。比如说如果用的基础网络是VGG16,那么输入的就是 14 ∗ 14 ∗ 512. 14*14*512. 14∗14∗512.
为什么是用sliding window?文中不是说用CNN么?
我们可以把3x3的sliding window看作是对特征图做了一次3x3的卷积操作,最后得到了一个channel数目是256的特征图,尺寸和公共特征图相同,我们假设是256 x (H x W);其实就是一次卷积,得到大小和feature map不变HxW大小的特征图256个。
256维特征向量如何获得的?
我们可以近似的把这个特征图看作有H x W个向量,每个向量是256维,那么图中的256维指的就是其中一个向量,然后我们要对每个特征向量做两次全连接操作,一个得到2个分数,一个得到4个坐标,由于我们要对每个向量做同样的全连接操作,等同于对整个特征图做两次1 x 1的卷积,得到一个2 x H x W和一个4 x H x W大小的特征图,换句话说,有H x W个结果,每个结果包含2个分数和4个坐标;
这里我们需要解释一下为何是2个分数,因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,那么就有两个分数,前景(物体)的分数,和背景的分数;损失函数参考博客
2k和4k中的k指的是什么?图右侧不同形状的矩形和Anchors又是如何得到的?
首先我们知道有H x W个结果,我们随机取一点,它跟原图肯定是有个一一映射关系的,由于原图和特征图大小不同,所以特征图上的一个点对应原图肯定是一个框,然而这个框很小,比如说8 x 8,这里8是指原图和特征图的比例,所以这个并不是我们想要的框,那我们不妨把框的左上角或者框的中心作为锚点(Anchor),然后想象出一堆框,(看基础部分锚点和候选ROI)具体多少,聪明的读者肯定已经猜到,K个,这也就是图中所说的K anchor boxes(由锚点产生的K个框);换句话说,H x W个点,每个点对应原图有K个框,那么就有H x W x k个框默默的在原图上,那RPN的结果其实就是判断这些框是不是物体以及他们的偏移;那么K个框到底有多大,长宽比是多少?这里是预先设定好的,共有9种组合,所以k等于9,最后我们的结果是针对这9种组合的,所以有H x W x 9个结果,也就是18个分数和36个坐标。18个分数表示是背景还是前景,36个坐标可以对固定产生的候选去进行调整,调整到和目标接近。
RPN整体流程
RPN的整个流程回顾
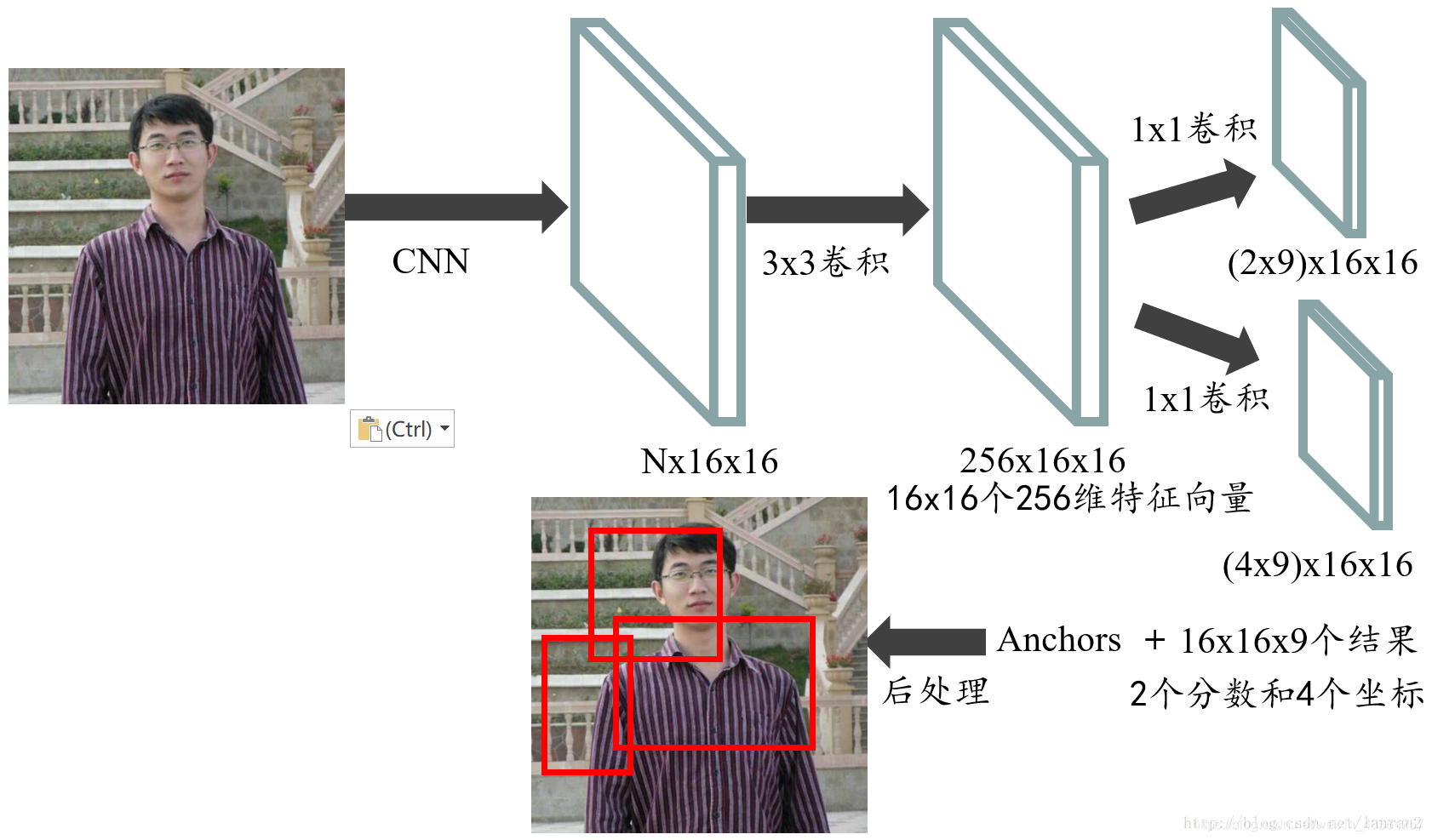
最后我们再把RPN整个流程走一遍,首先通过一系列卷积得到公共特征图,假设他的大小是N x 16 x 16,然后我们进入RPN阶段,首先经过一个3 x 3的卷积,得到一个256 x 16 x 16的特征图,也可以看作16 x 16个256维特征向量,然后经过两次1 x 1的卷积,分别得到一个18 x 16 x 16的特征图,和一个36 x 16 x 16的特征图,也就是16 x 16 x 9个结果,每个结果包含2个分数和4个坐标,再结合预先定义的Anchors,经过后处理,就得到候选框;
三、非极大值抑制
非极大抑制(Non-maximum suppression):由于锚点经常重叠,因此建议最终也会在同一个目标上重叠。为了解决重复建议的问题,我们使用一个简单的算法,称为非极大抑制(NMS)。NMS 获取按照分数排序的建议列表并对已排序的列表进行迭代,丢弃那些 IoU 值大于某个预定义阈值的建议,并提出一个具有更高分数的建议。
虽然这看起来很简单,但对 IoU 的阈值设定一定要非常小心。太低,你可能会丢失对目标的建议;太高,你可能会得到对同一个目标的很多建议。常用值是 0.6。
建议选择:应用 NMS 后,我们保留评分最高的 N 个建议。论文中使用 N=2000,但是将这个数字降低到 50 仍然可以得到相当好的结果。
四、训练
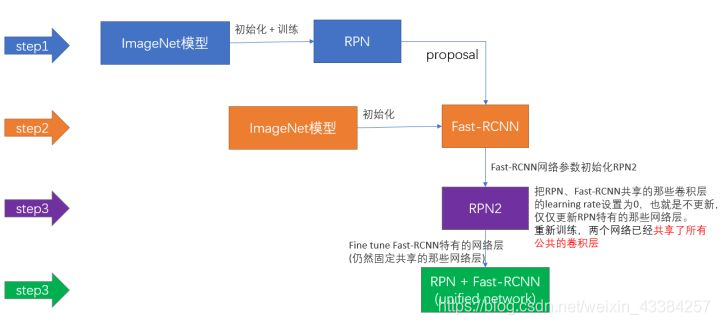
1、用ImageNet模型初始化,独立训练一个RPN网络。单独训练rpn(ImageNet-pre_train + fine-tune),得到rpn1,CNN1
那究竟RPN网络是如何进行训练的呢?
- 对每个标定的ground true box区域,与其重叠比例最大的anchor记为 正样本 (保证每个ground true 至少对应一个正样本anchor);
- 对1)剩余的anchor,如果其与某个标定区域重叠比例大于0.7,记为正样本(每个ground true box可能会对应多个正样本anchor。但每个正- 样本anchor 只可能对应一个grand true box);如果其与任意一个标定的重叠比例都小于0.3,记为负样本。
- 对上面两步剩余的anchor,弃去不用;
- 跨越图像边界的anchor弃去不用。
损失函数
有个问题:背景框在训练的时候作为背景框,是不是也产生了回归框呢
训练的时候,提前在所有anchor box中挑选出来了正负样本,正样本的时候,p* =1,有边框回归损失函数那一项,负样本时p*=0,没有损失函数那一项,然后把损失函数反向传递更新权重。所以在训练的时候,主要就是根据损失函数进行权重的学习。

2、仍然用ImageNet模型初始化,但是使用上一步RPN网络产生的proposal作为输入,训练一个Fast-RCNN网络,至此,两个网络每一层的参数完全不共享。单独训练fast rcnn(ImageNet-pre_train + fine-tune),结合第一步的region proposal,得到fast-rcnn1,CNN2
说明:第一和第二步,用同样的mode(ImageNet模型)l初始化RPN网络和Fast-rcnn网络,然后各自独立地进行训练,所以训练后,各自对model的更新一定是不一样的(论文中的different ways),因此就意味着model是不共享的(论文中的dont share convolution layers)。
3、使用第二步训练完成的model来初始化RPN网络,第二次训练RPN网络。但是这次要把model锁定,训练过程中,model始终保持不变,而RPN的unique会被改变。(把RPN、Fast-RCNN共享的那些卷积层的learning rate设置为0,也就是不更新,仅仅更新RPN特有的那些网络层,重新训练,)
说明:因为这一次的训练过程中,model始终保持和上一步Fast-rcnn中model一致,所以就称之为着共享。
仍然固定共享的那些网络层,把Fast-RCNN特有的网络层也加入进来,形成一个unified network,继续训练,fine tune Fast-RCNN特有的网络层(后面的softmax和分类等),此时,该网络已经实现我们设想的目标,即网络内部预测proposal并实现检测的功能。
4、仍然保持第三步的model不变,初始化Fast-rcnn,第二次训练Fast-rcnn网络。其实就是对其unique进行finetune,训练完毕,得到一个文中所说的unified network。
测试:
(1)对于每张图片,利用它的feature map, 计算 (H/16)× (W/16)×9 ==(大概20000)==个anchor属于前景的概率,以及对应的位置参数。
(2)选取概率较大的12000个anchor,利用回归的位置参数,修正这12000个anchor的位置,得到RoIs,利用非极大值((Non-maximum suppression, NMS)抑制,选出概率最大的2000个RoIs
注意:在inference的时候,为了提高处理速度,12000和2000分别变为6000和300.
RPN:
生成anchors -> softmax分类器提取fg anchors -> bbox reg回归fg anchors -> Proposal Layer生成proposals
这里Proposal Layer生成proposals的过程为:
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
- 生成anchors,利用坐标dx 、dy、dw、dh对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
- 按照输入的foreground softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的foreground anchors。
- 限定超出图像边界的foreground anchors为图像边界(防止后续roi pooling时proposal超出图像边界)
- 剔除非常小(width<threshold or height<threshold)的foreground anchors
- 进行nonmaximum suppression
- 再次按照nms后的foreground softmax scores由大到小排序fg anchors,提取前post_nms_topN(e.g. 300)结果作为proposal输出。
(3)进行fast rcnn 的步骤:
• 对得到的感兴趣区域进行ROI pooling(感兴趣区域池化):即通过坐标投影的方法,在特征图上得到输入图像中的感兴趣区域对应的特征区域,并对该区域进行最大值池化,这样就得到了感兴趣区域的特征,并且统一了特征大小,
• 对ROI pooling层的输出(及感兴趣区域对应的特征图最大值池化后的特征)作为每个感兴趣区域的特征向量;
• 将感兴趣区域的特征向量与全连接层相连,并定义了多任务损失函数,分别与softmax分类器和boxbounding回归器相连,分别得到当前感兴趣区域的类别及坐标包围框;
• 对所有得到的包围框进行非极大值抑制(NMS),得到最终的检测结果。
参考:
https://blog.youkuaiyun.com/qq_36269513/article/details/80422276
https://www.cnblogs.com/Terrypython/p/10584384.html
https://blog.youkuaiyun.com/qq_27825451/article/details/88843333
https://www.cnblogs.com/hotsnow/p/9951046.html
https://www.cnblogs.com/guoyaohua/p/9488119.html?utm_source=debugrun&utm_medium=referral
https://blog.youkuaiyun.com/weixin_40449426/article/details/78141635

















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









