







系列文章目录
第五章 MobileNet
目录
参考文献
前言
在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型是难以被应用的。首先是模型过于庞大,面临着内存不足的问题;其次这些场景要求低延迟,或者说响应速度要快。所以研究小而高效的CNN模型在这些场景至关重要。目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。
本文的主角MobileNet属于后者,其是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。下面对MobileNet做详细的介绍。
一、MobileNet
1.基本模块
1.1 Depthwise separable convolution
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution)。深度级可分离卷积其实是一种可分解卷积操作(factorized convolutions),将正常卷积分解为两个更小的操作:逐层卷积depthwise convolution和逐点卷积pointwise convolution。对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积;然后采用pointwise convolution将上面的输出再进行结合(pointwise convolution相当于标准的卷积核为1*1的卷积)。这样其整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
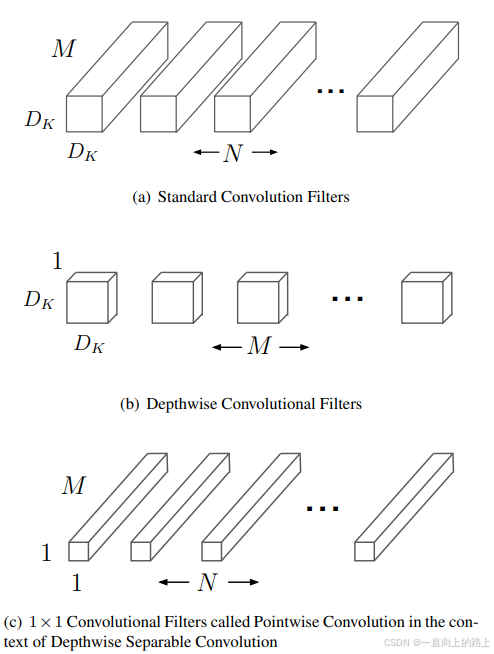
假定输入特征图大小是H×W×M,而输出特征图大小是H×W×N,卷积核大小为DK×DK。正常卷积的计算量将是:DK×DK×H×W×M×N。
而对于depthwise convolution,其输入和输出通道数相同,等效一个M组分组卷积。即输入的一个通道经过一个DK×DK大小的单卷积核完全确定输出一个通道。其计算量为DK×DK×M×H×W 。
pointwise convolution为1×1卷积,输入通道数等于depthwise convolution的输出M,输出通道数为N。其计算量是:M×N×H×W。
depthwise separable convolution的计算量为标准卷积的1/N+1/DK2。如果采用3x3卷积核的话,depthwise separable convolutionde的计算量约为标准卷积的1/9,后参数量也会减少很多。
1.2 Depthwise separable convolution模块
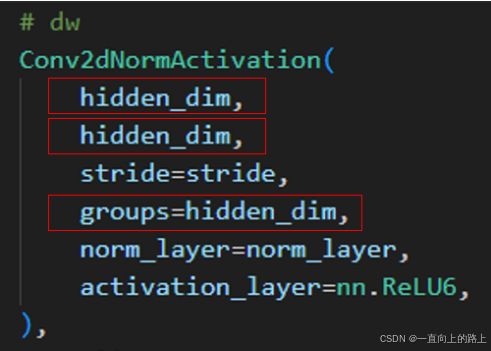
标准的卷积层之后都会添加batchnorm和ReLU,所以构造的Depthwise separable convolution模块的逐层卷积核逐点卷积层之后都有BN和ReLU层:
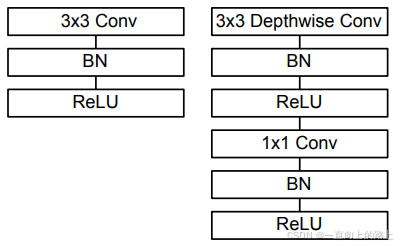
MobileNet中的ReLU是ReLU6(x) = min(max(0, x), 6),也就是限制最大输出为6。
2.MobileNet的网络结构
MobileNet包含:1个标准卷积层,13个Depthwise separable convolution模块,1个Avg Pool和1个全连接层。
除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是利用stride=2来下采样,此法已经成为主流。
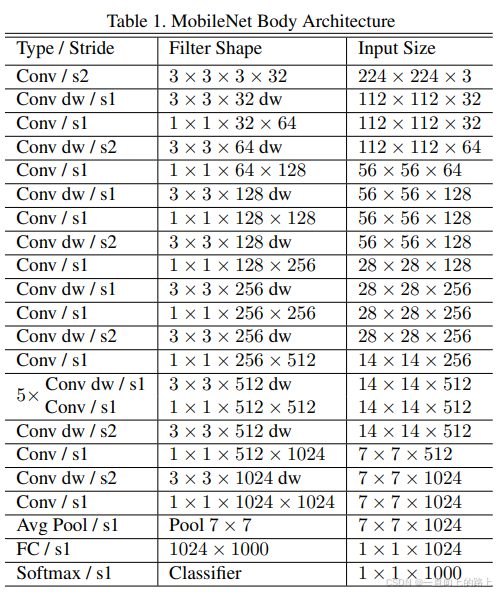
(最后一个Conv dw / s2应修改为Conv dw / s1)
MobileNet花费了95%的时间在逐点卷积层的计算,逐点卷积的参数量占整个模型的75%。
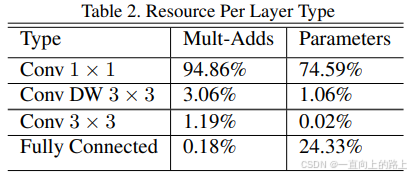
MobileNet中的Depthwise separable convolution模块可以在保证精度的情况下,大幅降低模型大小和计算量。

二、MobileNet v2
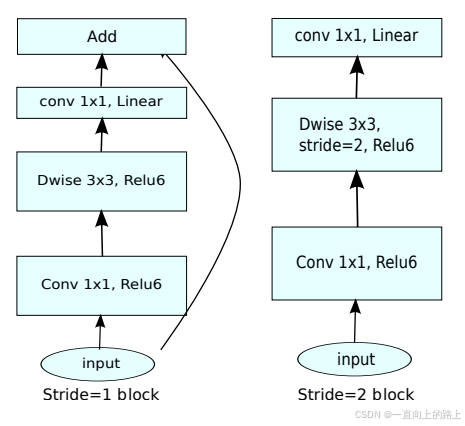
MobileNet v2借鉴了ResNet的残差模块Shortcut结构。
1.基本模块
ResNet的Bottleneck结构是先使用1*1卷积降低通道数,在3*3卷积完成后再次使用1*1卷积恢复通道数,以此降低计算量。
因为使用ReLU激活函数,深度神经网络仅在输出域的非零区域具有线性分类能力。经过ReLU之后,不可避免的会丢失通道的一些信息。仅当通道数目比较多的时候,一个通道修饰的信息可能在另一个通道中还保留。
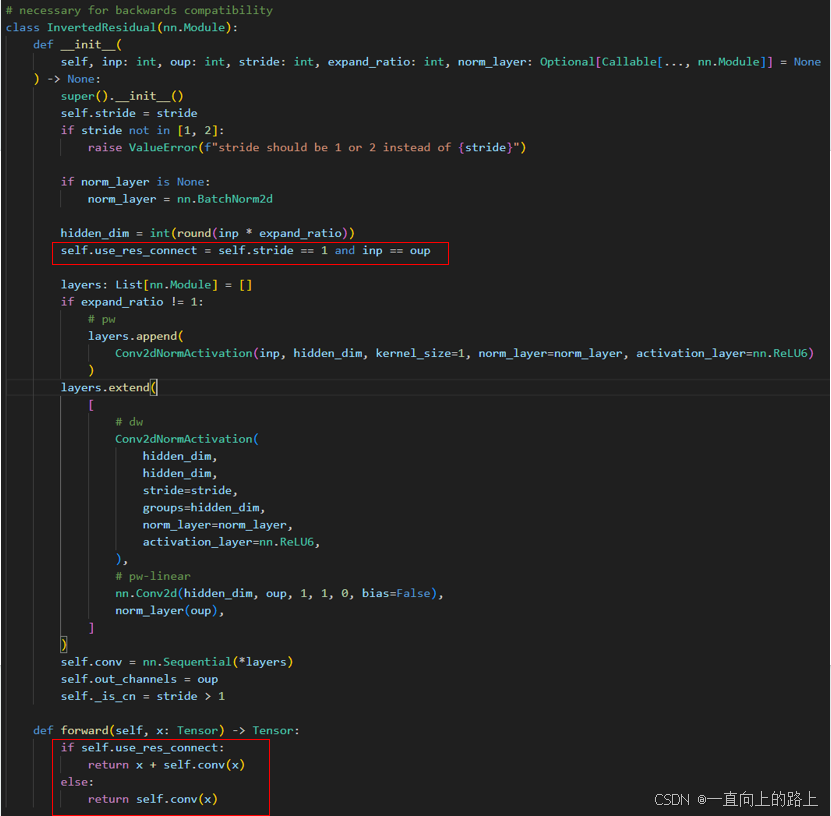
所以MobileNet v2使用了Inverted residuals模块,先扩张通道数。同时去除紧跟在执行通道数降低的卷积层后面的ReLU激活函数。
1.1 Inverted residuals模块

假定输入特征图大小是H×W×M,先使用1*1的卷积扩张通道数。假定通道扩充因子为t,则输出特征图大小为H×W×tM。
第二层为depthwise convolution,其输入和输出通道数相同,等效一个M组分组卷积。输出特征图大小为H/s×W/s×tM,s为卷积的stride。
最后使用1*1的卷积降低通道数。
仅当逐层卷积的stride为1,且Inverted residuals模块的输入通道数等于输出通道数的时候,shortcut才生效。否则,不使用shortcut。
2.MobileNet v2的网络结构
MobileNet v2包含:1个标准卷积层,17个Inverted residuals模块,1个1*1卷积+1个Avg Pool+1个1*1卷积(全连接)。
MobileNet v2的第一个标准卷积层和MobileNet完全一样。MobileNet v2第一个Inverted residuals模块(一层逐层卷积+一层1*1卷积)的输出通道数为16,MobileNet的第一个1*1卷积的输出通道为64。所以MobileNet v2的参数量和计算量小于MobileNet。
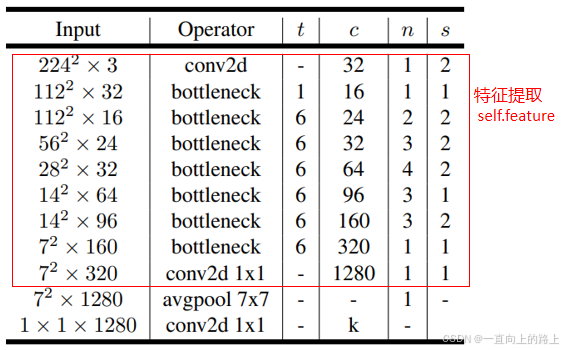
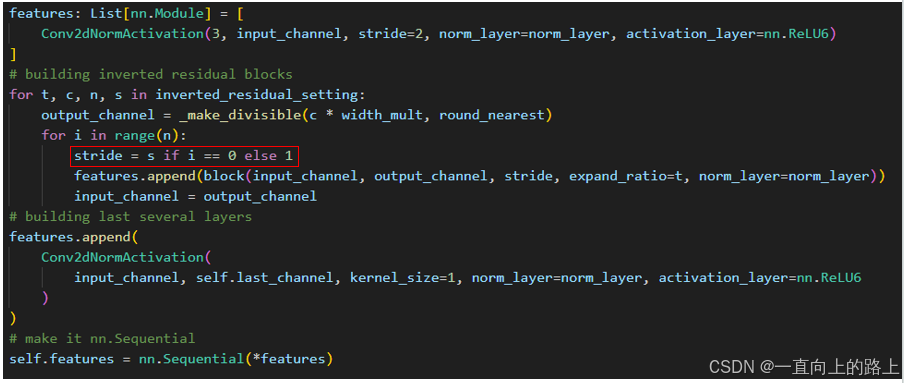
MobileNet v2的特征提取部分分为9级。如果其中一级的输入分辨率不等于输出,则这一级中的第一个Inverted residuals模块的stride等于这一级的stride,其他Inverted residuals模块的stride等于1。
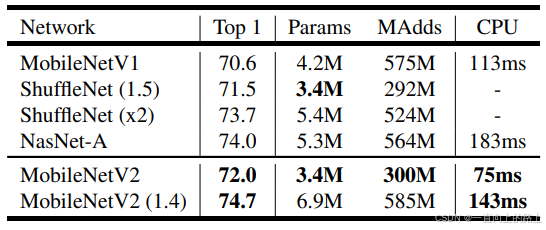
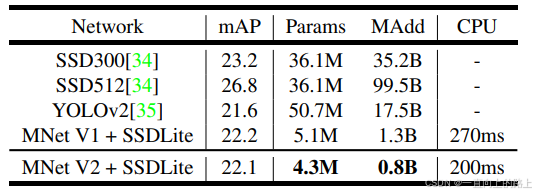
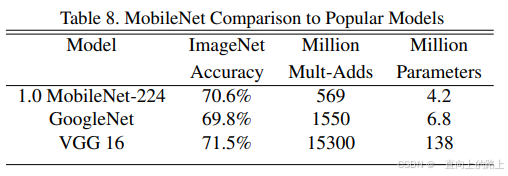
在参数量小于MobileNet的情况下,MobileNet v2的准确度比MobileNet更高。
三、MobileNet v3
MobileNet v3加入了SE模块,选用了新的激活函数。MobileNet v3还结合硬件感知网络架构搜索NAS来搜索网络的配置和参数。
1. SE模块
SE模块可以插入到任何模型中实现通道注意力。通过学习来自动获取到每个特征通道的重要程度,然后依照这一结果去提升有用的特征并抑制对当前任务用处不大的特征。
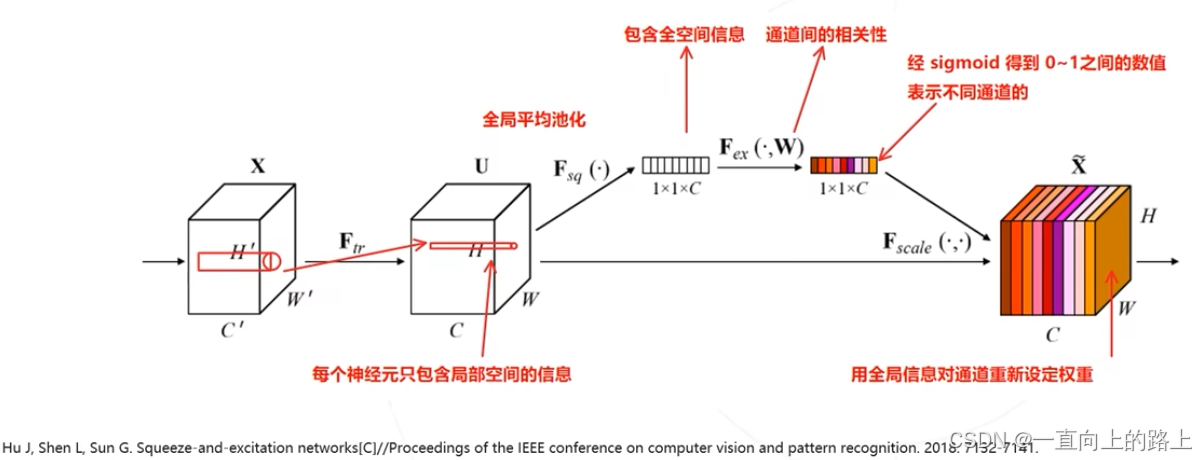
MobileNet v3中的SE模块是根据需要添加在Inverted residuals模块的逐层卷积之后,实现逐层卷积的通道注意力。
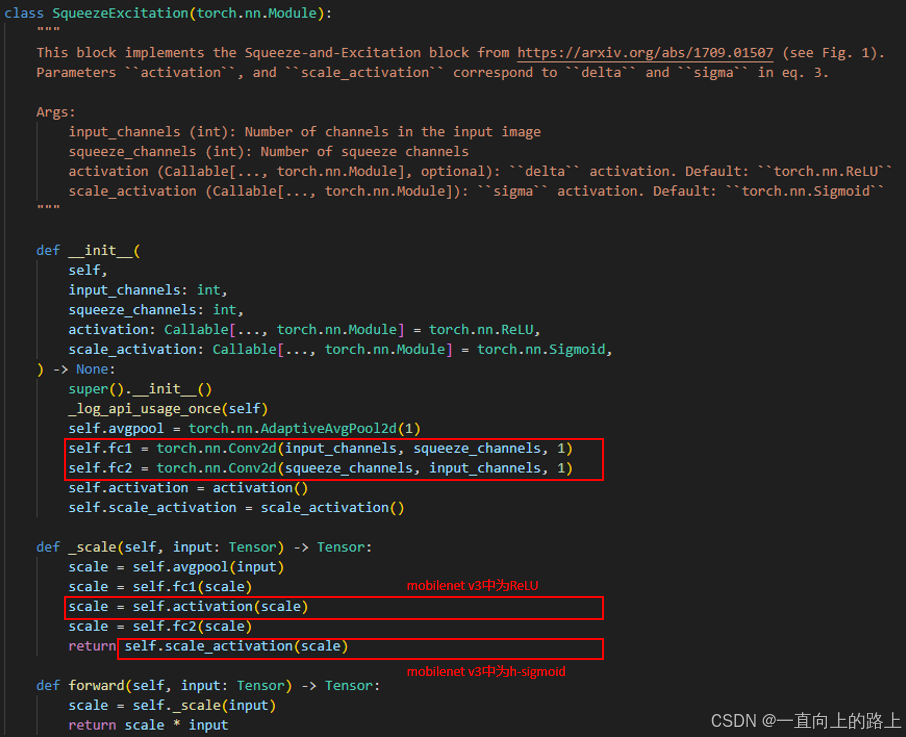
为什么使用两层全连接计算通道权重呢?一是为权重的计算添加非线性,作者选用了ReLU激活函数放在第一层全连接后面,而权重计算最后需要经过Sigmoid函数归一化到0-1区间,为了将ReLU和Sigmoid隔开,作者添加了第二层全连接。二是为了减少计算量,第一个全连接层把C个通道压缩成了C/r个通道来降低计算量,第二个全连接层将通道数恢复回为C个通道。
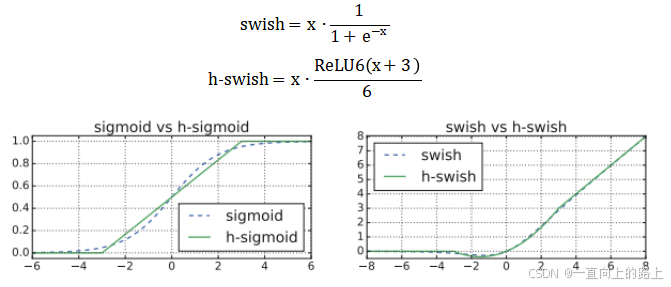
2.h-swish激活函数
swish激活函数可以替代ReLU提高神经网络的精度,但是计算复杂。MobileNet v3使用分段线性模拟sigmod激活函数,提出swish的简化版本h-swish:
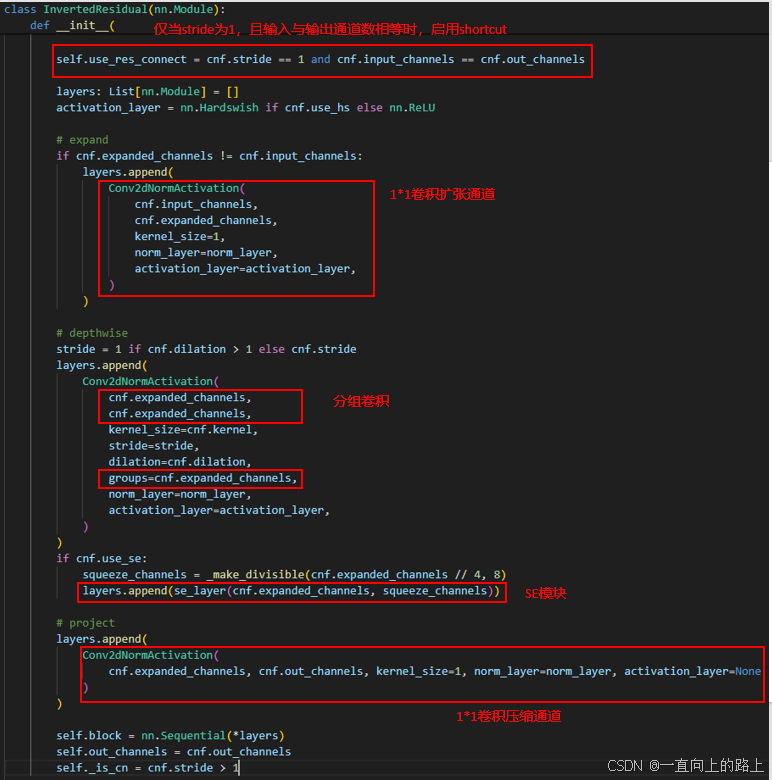
3.Inverted residuals模块
4.网络搜索
网络搜索对于网络结构设计和优化是非常有用的。MobileNet v3使用NAS通过优化每一个网络模块的方式搜索全局网络结构,然后使用NetAdapt算法确定每一层的过滤器数目。这些技术可以结合使用,来确定一个给定硬件平台的最优模型。
4.1 NAS
定义一个优化函数,在模型准确率、模型运行延迟等多个优化指标之间找到最优的均衡结果。
将模型细分为block>layer>operation,使用强化学习进行搜索。
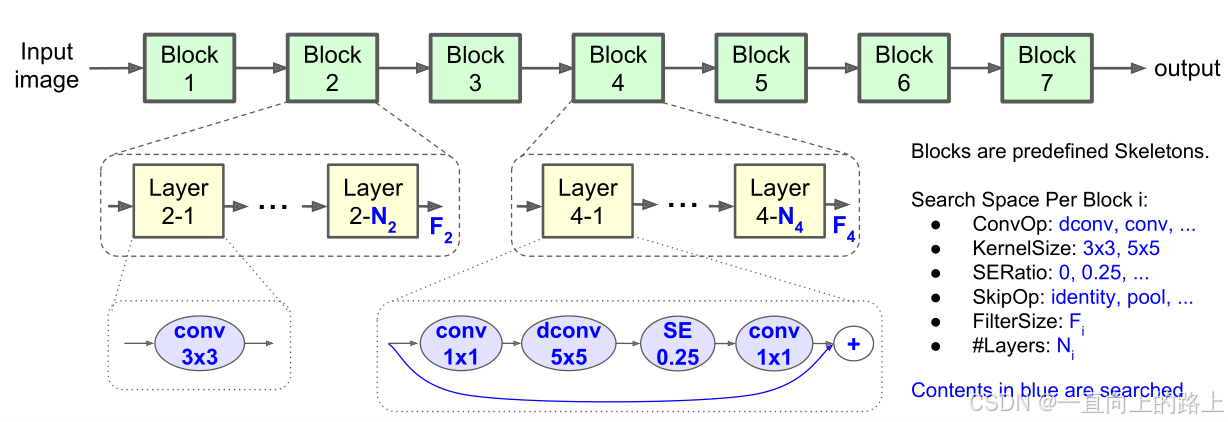
4.2 NetAdapt
已NAS找到的网络结构作为种子,以连续的方式对各个层进行微调:
- 生成一系列的候选结构
- 使用前一步的预训练模型初始化候选结构,对于预训练模型不存在的结构使用随机初始化。对每个候选结构,微调T个epoch,获得候选结构的粗略评估。
- 通过实验矩阵选取最佳提案。
5.MobileNet v3的网络结构
MobileNet v3有MobileNet v3-Large和MobileNet v3-Small两种模型,用于在不同性能的设备上运行。MobileNet v3-Large和MobileNet v3-Small都是通过网络搜索确定的最优结构。
第一层为标准的卷积+BN+h-swish激活,输入通道数为3,输出通道数为16,stride为2.
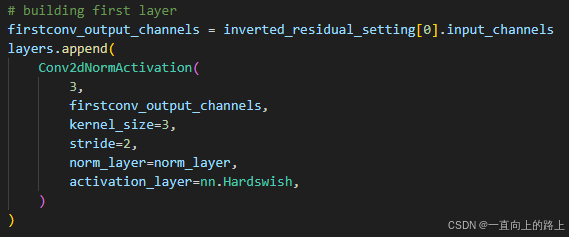
最后四层分别为:标准的卷积+BN+h-swish激活,7*7的平均池化,全连接+h-swish激活+Dropout,全连接。
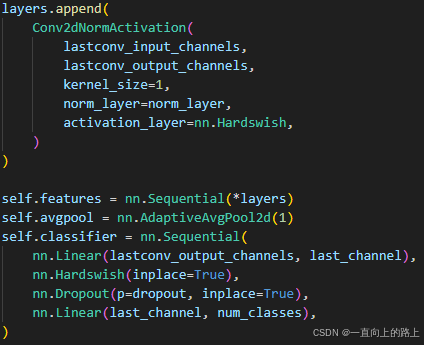
中间为堆叠的inverted residual模块。
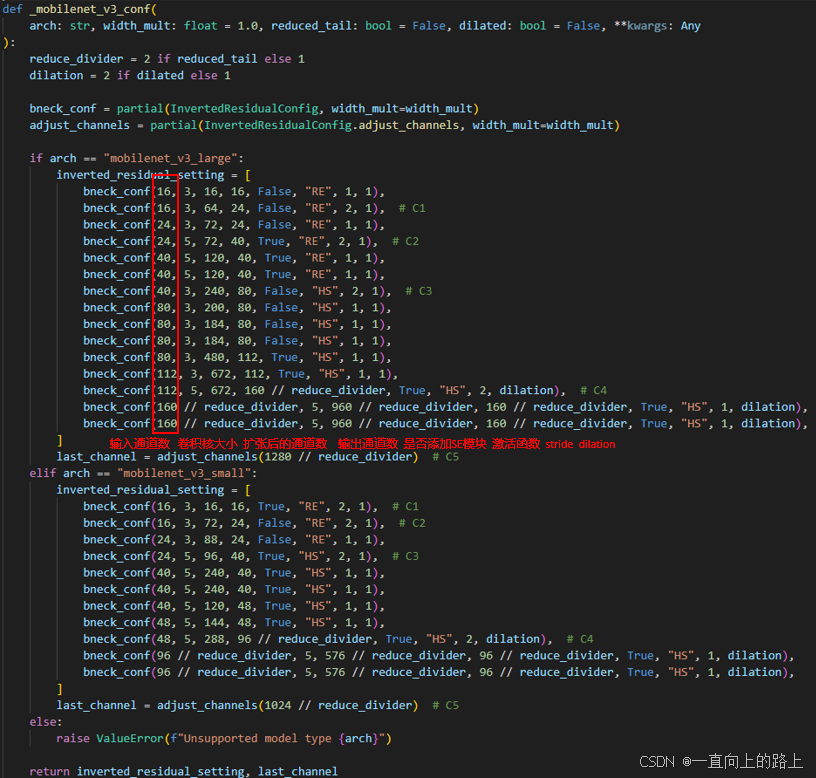
其中第一层、倒数第四层以及中间的inverted residual模块构成了MobileNet v3的backbone特征提取器。
5.1 MobileNet v3-Large
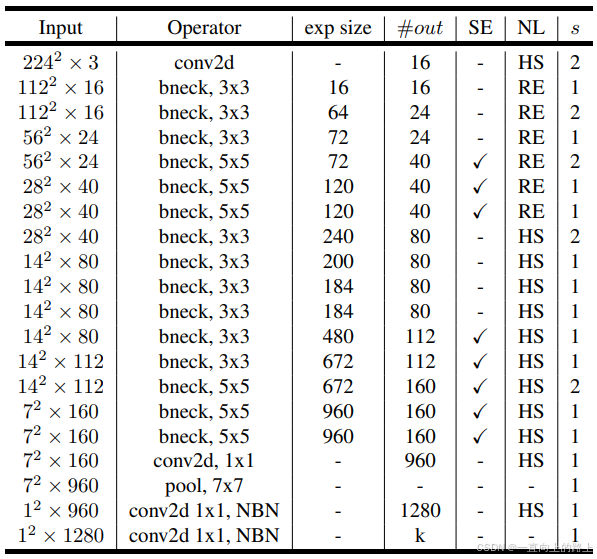
5.2 MobileNet v3-Small
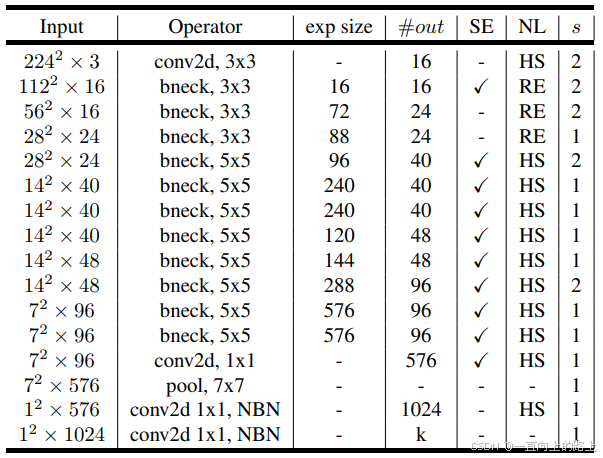
5.3 网络精度
MobileNet v3相比于MobileNet v2在精度和时间性能上都有明显提升。
1)浮点模型分类测试结果:
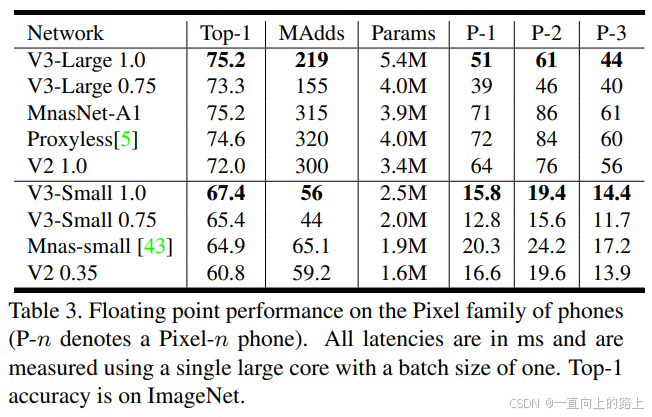
2)量化模型分类测试结果:
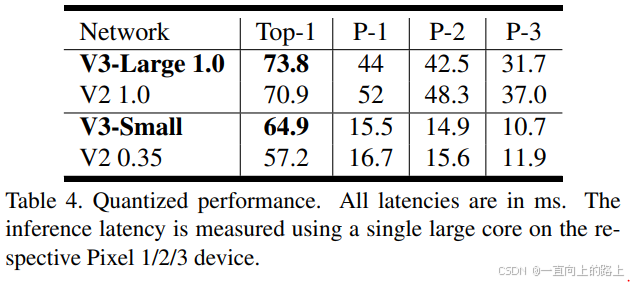
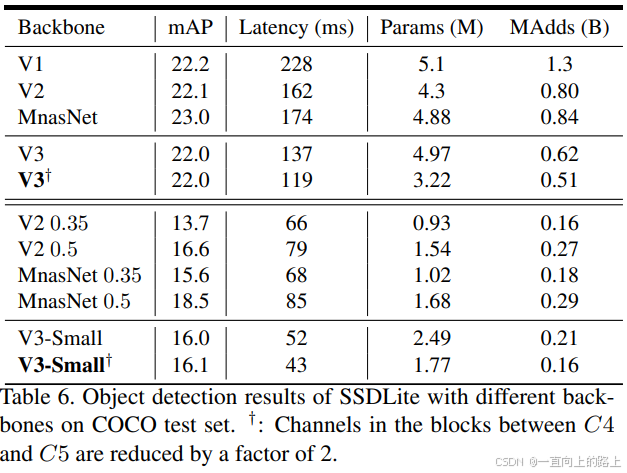
3)目标检测任务测试结果:
选用不同的网络模型作为SSDLite的backbone特征提取器,在COCO数据集上对比。
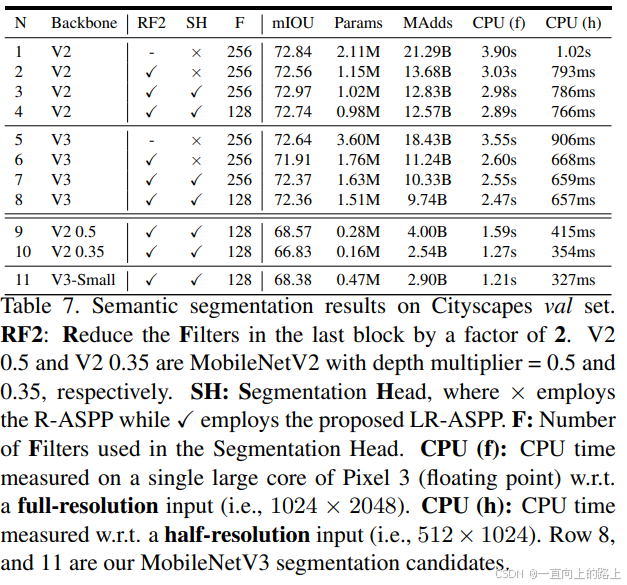
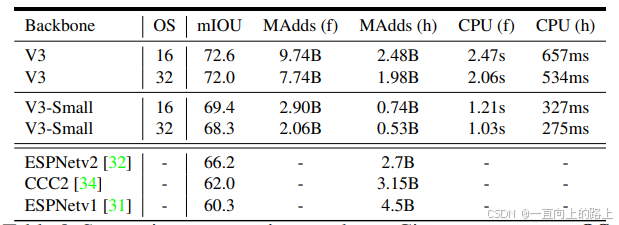
4)分割任务测试结果:
参考文献
https://arxiv.org/pdf/1905.02244
https://arxiv.org/pdf/1807.11626


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









