







 本文深入剖析了LinkedHashMap的数据结构和知识要点,包括accessOrder参数的作用、数据节点的双向链表结构以及put和get操作。同时,文章介绍了如何利用LinkedHashMap实现LRU缓存,包括线程安全的实现、设置过期时间和Guava Cache的实现方式,讨论了Guava Cache的优化策略,如AccessQueue、WriteQueue和RecentQueue的设计。
本文深入剖析了LinkedHashMap的数据结构和知识要点,包括accessOrder参数的作用、数据节点的双向链表结构以及put和get操作。同时,文章介绍了如何利用LinkedHashMap实现LRU缓存,包括线程安全的实现、设置过期时间和Guava Cache的实现方式,讨论了Guava Cache的优化策略,如AccessQueue、WriteQueue和RecentQueue的设计。
文章目录
1、LinkedHashMap数据结构
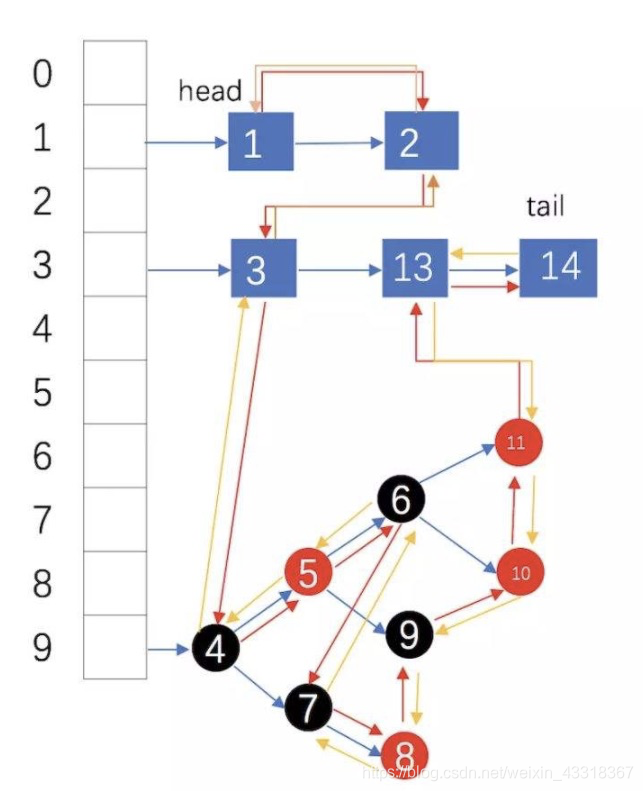
一图便知原理:
- LinkedHashMap 是HashMap + LinkedList 双结构
- 即保留了HashMap的高效存取能力
- 又具备了按预期顺序遍历的能力
2、LinkedHashMap知识要点
2.1、LinkedHashMap构造方法的accessOrder参数
LinkedHashMap是有排序能力的HashMap。其排序策略有2种,取决于accessOrder的设置
- accessOrder = false 所有Entry按照插入排序
- accessOrder = true 所有Entry按照访问排序
LRU实现时,accessOrder要在构造方法里设置为true
2.2、LinkedHashMap在HashMap基础上额外维护一个双向链表
结构如上图所示
LinkedHashMap 的数据节点类型
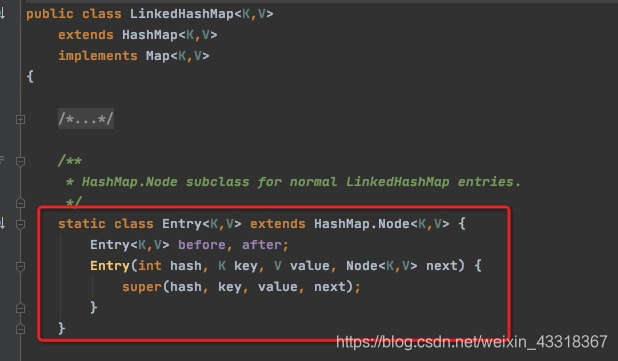
在HashMap.Node基础上,包装了一个Entry。这个Entry实现双向链表的能力。
2.3、put(key, value)新增数据时
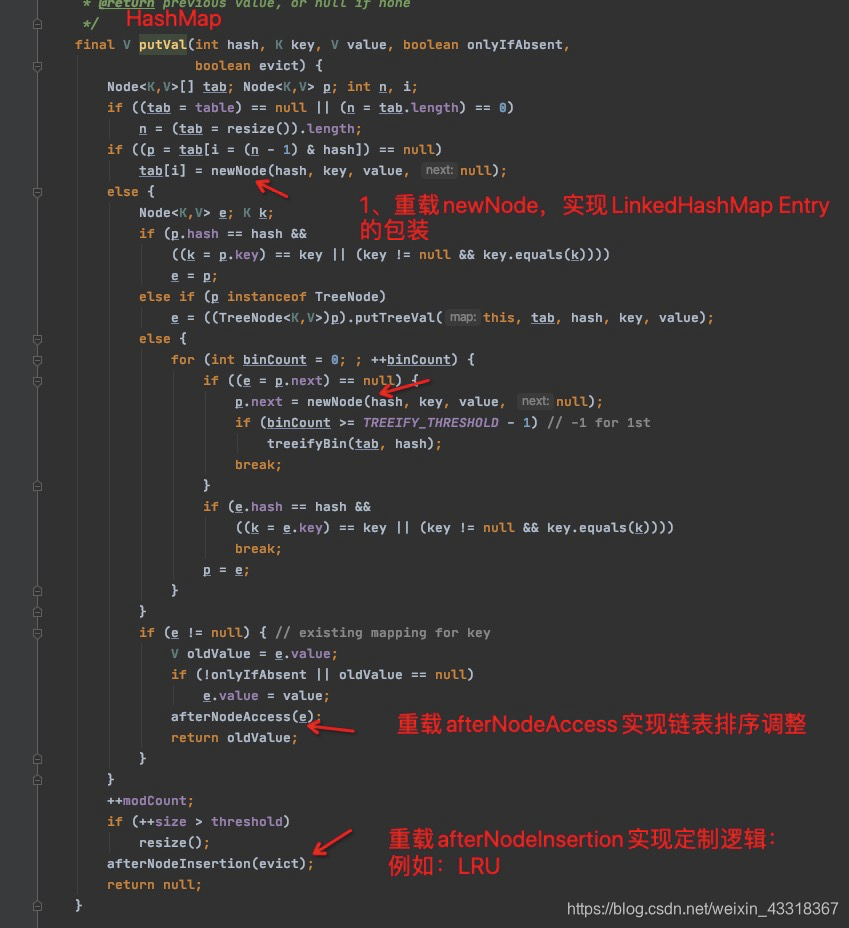
- 为什么put()方法中也要afterNodeAccess? 覆写数据也算一次访问。
2.4、get(key)访问数据时
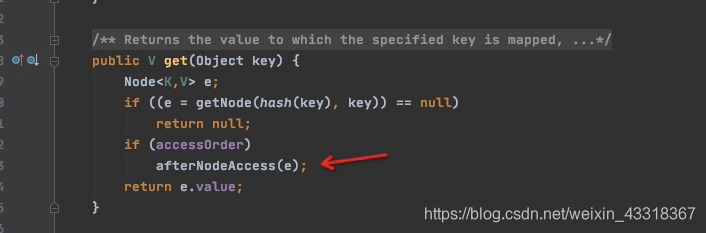
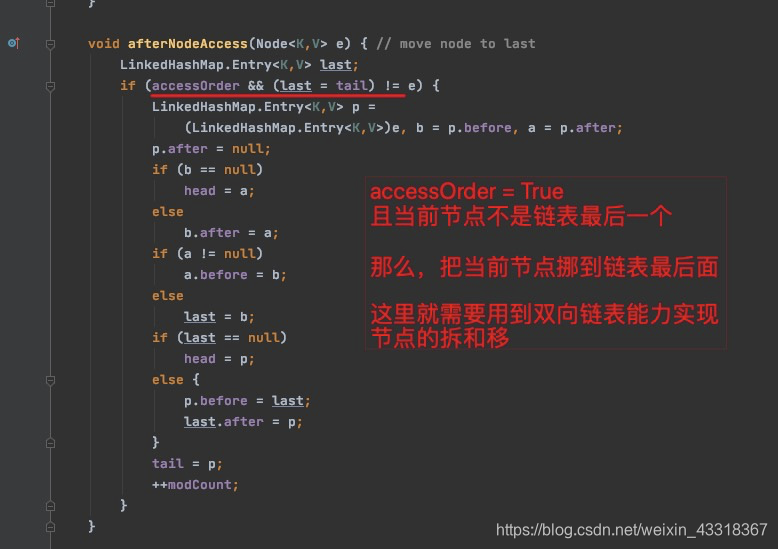
3、实现一个LRU
3.1、LinkedHashMap是天生的LRU
只需要做几个事:
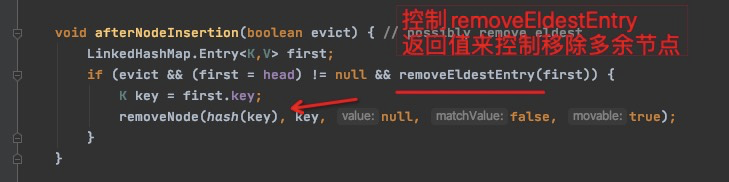
1、构造时设置accessOrder = true 。按双向链表按访问排序。
2、重载 removeEldestEntry
注:最近访问的在链表尾部。淘汰链表头部的。
详细代码:
public class LRUCache<K,V> extends LinkedHashMap<K,V> {
private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
//true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的的放在尾部
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
//当map中的数据量大于制定的缓存个数的时候,就自动删除最老的数据
return size() > CACHE_SIZE;
}
}
测试:
@Test
public void testLRU(){
LRUCache lruCache = new LRUCache(10);
for (int i = 1; i <= 10; i++){
lruCache.put(String.valueOf(i), String.valueOf(i));
}
System.out.println("初始化后:");
lruCache.forEach((k,v) -> {
System.out.println("key = " + k + " value = " + v);});
lruCache.get("5");
lruCache.get("1");
lruCache.get("8");
System.out.println("几次访问后:");
lruCache.forEach((k,v) -> {
System.out.println("key = " + k + " value = " + v);});
lruCache.put("first","first");
lruCache.put("second","second");
System.out.println("超量设置后:");
lruCache.forEach((k,v) -> {
System.out.println("key = " + k + " value = " + v);});
}
结果:
初始化后:
key = 1 value = 1
key = 2 value = 2
key = 3 value  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









