






RandLA-Net论文理解:大规模室外点云语义分割
概述
论文针对大规模室外点云语义分割提出两个想法:
1.分析了一些降采样方法,认为随机采样从效率和可行性上更适合大规模点云的采样
2.为了对抗随机采样带来的关键信息丢失问题,提出局部特征采样器
随机采样
最重要的是由于随机采样的计算复杂度为O(1),所以与输入点的总数无关。总的来说,FPS、IDIS和GS在计算上太昂贵,无法应用于大规模点云。CRS方法的内存占用过大,PGS 很难学习。相比之下,随机采样有两个优点:
1)它具有显著的计算效率,因为它与输入点的总数无关;
2)它不需要额外的内存来计算。
局部特征采样器
1.局部空间编码 (LocSE)
1)对每个中心采样点用KNN获取邻域点集合。
2)对某个中心点pi的每个邻域点 (共K个),基于(x,y,z)坐标通过MLP提取相对点位置特征得到:
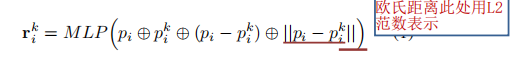
3)将1)得到的相对点位置特征和该点的点特征连接起来获得增强特征向量
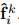
4)将2)中各邻域点增强特征组合起来就是LocSE单元的输出,即一组新的相邻特征:

2.Attentive pooling
1)计算每个邻域点的特征权重
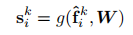
2)对中心点pi,聚合邻域特征-通过加权平均邻域点特征
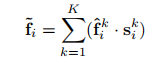
残差模块
参考 ResNet,用局部特征聚集和下采样搭建了残差模块。作者认为一个残差块中有两个由局部特征聚集和下采样组成的单元是合适的。

















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









