






DeepSeek 再探(二)
-
知识预备PG
策略模型参数 θ \theta θ 在给定观测值(
input_ids) 的条件下,自回归生成一段轨迹/句子trajectory: τ \tau τ
τ = { s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , . . . , s T , a T , r T } \tau = \{{s_1,a_1,r_1,s_2,a_2,r_2,...,s_T,a_T,r_T}\} τ={s1,a1,r1,s2,a2,r2,...,sT,aT,rT}
解释下:s i s_i si 表示当前观测状态,对应于策略模型(policy model)输入(
input_idsorimput_emdings);a i a_i ai 是动作,等同于策略模型输入
input_ids经forward得到的logits做sample操作,在vocab里选取next token; 由于sample具有随机性,相同的观测值未必采取相同的行动(即: 同一个问题上生成多条回答);r i r_i ri 是 冻结的 reward model 在给定状态-动作序列 ( s i < t s_{i<t} si<t, a i < t a_{i<t} ai<t) 后生成的即时奖励分数,表示当前时刻 的 r i r_i ri 的即时奖励。
当前时刻 i i i的整体奖励由即时奖励和未来奖励两部分组成,其数学表达式为:
R ( τ ) = ∑ i T r n R(\tau) = \sum_i^{T} r_{n} R(τ)=i∑Trn""" 在选择当前动作 $a_i$ token 时,未来奖励是无法直接获取的。为解决这个问题,还需要引入 `critic` 来估计未来奖励的期望值。 """目标:训练模型参数 θ \theta θ , 由 θ \theta θ 采样/生成每条轨迹/句子的奖励分数 R ( τ ) R(\tau) R(τ) 要高,因此,最大化目标函数:
o b j θ = ∑ τ R ( τ ) P ( τ ∣ θ ) obj_{\theta} = \sum_{\tau} R(\tau)P(\tau|\theta) objθ=τ∑R(τ)P(τ∣θ)
求解梯度:
∇ o b j θ = ∑ τ R ( τ ) ∇ P ( τ ∣ θ ) = ∑ τ R ( τ ) P ( τ ∣ θ ) ∇ l o g P ( τ ∣ θ ) = 1 N ∑ 1 N R ( τ ) ∇ l o g P ( τ ∣ θ ) \nabla obj_{\theta} = \sum_{\tau} R(\tau) \nabla P(\tau|\theta) \\ = \sum_{\tau} R(\tau)P(\tau|\theta) \nabla logP(\tau|\theta) \\ = \frac{1}{N} \sum^{N}_{1} R(\tau) \nabla logP(\tau|\theta) ∇objθ=τ∑R(τ)∇P(τ∣θ)=τ∑R(τ)P(τ∣θ)∇logP(τ∣θ)=N11∑NR(τ)∇logP(τ∣θ)
求 P ( τ ∣ θ ) P(\tau|\theta) P(τ∣θ)
P ( τ ∣ θ ) = p ( s 1 ) p ( a 1 ∣ s 1 , θ ) p ( r 1 , s 2 ∣ s 1 , a 1 ) p ( a 2 ∣ s 2 , θ ) p ( r 2 , s 3 ∣ s 2 , a 2 ) . . . P(\tau|\theta) = p(s_1)p(a_1|s_1,\theta)p(r_1,s_2|s_1,a_1)p(a_2|s_2,\theta)p(r_2,s_3|s_2,a_2) ... P(τ∣θ)=p(s1)p(a1∣s1,θ)p(r1,s2∣s1,a1)p(a2∣s2,θ)p(r2,s3∣s2,a2)...
只保留与 θ \theta θ 相关项
l o g P ( τ ∣ θ ) = ∑ t = 1 T p ( a t ∣ s t , θ ) logP(\tau|\theta) = \sum_{t=1}^{T} p(a_t|s_t,\theta) logP(τ∣θ)=t=1∑Tp(at∣st,θ)
最终梯度计算公式如下:
∇ o b j θ = 1 N ∑ n = 1 N R ( τ ) ∇ l o g P ( τ ∣ θ ) = 1 N ∑ n = 1 N ∑ t = 1 T R ( τ n ) ∇ l o g p ( a t ∣ s t , θ ) \nabla obj_{\theta} = \frac{1}{N} \sum^{N}_{n = 1} R(\tau) \nabla logP(\tau|\theta) \\ = \frac{1}{N} \sum^{N}_{n = 1} \sum^{T}_{t = 1} R(\tau^{n}) \nabla logp(a_t|s_t,\theta) ∇objθ=N1n=1∑NR(τ)∇logP(τ∣θ)=N1n=1∑Nt=1∑TR(τn)∇logp(at∣st,θ)
当 R ( τ ) R(\tau) R(τ) 始终为正值时,若采样(sample)数量不足,已采样到的动作 a i a_i ai 的概率会随着参数 θ \theta θ 的更新而逐渐提高;而未采样到的动作 a j a_j aj 的概率则会随着 θ \theta θ 的更新而逐渐降低。然而,在初始理想条件下,根据分布 p ( τ ∣ θ ) p(\tau|\theta) p(τ∣θ), a j a_j aj 可能产生的奖励实际上比 a i a_i ai 更高(由于 a j a_j aj 在初始时未被采样到,策略模型参数更新时会降低 a j a_j aj 的概率)。因此,为了避免这种偏差,需要引入一个基线值(baseline),使得 R ( τ ) R(\tau) R(τ) 不完全为正值。这就是引入优势概念的原因。
∇ o b j θ = 1 N ∑ n = 1 N ∑ t = 1 T R ( τ n − b ) ∇ l o g p ( a t ∣ s t , θ ) \nabla obj_{\theta} = \frac{1}{N} \sum^{N}_{n = 1} \sum^{T}_{t = 1} R(\tau^{n} -b ) \nabla logp(a_t|s_t,\theta) \\ ∇objθ=N1n=1∑Nt=1∑TR(τn−b)∇logp(at∣st,θ) -
知识预备RLHF
-
价值函数:
上文讨论奖励值时,仅考虑即时奖励显得有点短视,因为当前状态和动作会影响未来的状态和动作,进而影响整体收益。因此,更合理的设计是:t时刻总收益 = **即时收益 + 未来收益。**表达式如下:
V t = R t + γ V t + 1 V _ { t } = R _ { t } + \gamma V _ { t + 1 } Vt=Rt+γVt+1-
V
t
V_t
Vt: t时刻的实际期望总收益,包含即时和未来收益,由参数更新的
critic model预测。指的是对语言模型从“当前生成 token 开始,直到整个 response 生成结束”后的收益预估。由于语言模型尚未生成后续的 token,因此只能对其未来一系列动作的收益进行估计,故称为“期望总收益”。 -
R
t
R_t
Rt: t 时刻的即时收益, 由冻结的
reward model产生。 -
V
t
+
1
V_{t+1}
Vt+1: t+1时刻的总收益,代表未来收益,由参数更新的
critic model预测,同 V t V_t Vt 定义。 - γ \gamma γ: 折扣因子,决定未来收益对当前收益的影响程度。
-
V
t
V_t
Vt: t时刻的实际期望总收益,包含即时和未来收益,由参数更新的
-
四个角色:
- Actor Model,需要训练的策略模型,参数可训练。先喂给Actor一条prompt,让它生成对应的response。然后,再将“prompt + response"送入
带奖励weight的loss 计算体系中去算loss,用于更新actor 参数更新。 - Critic Model,作用是预估总收益 V t V_t Vt, 参数可训练。在 t t t 时刻,给不出客观存在的总收益 V t V_t Vt,只能训练一个模型去预测它,主要提升人类偏好量化判断能力。
- Reward Model,它的作用是计算即时收益 R t R_t Rt, 参数冻结。
- Reference Model,给Actor增加一些“约束”,防止Actor训歪,一般用SFT模型做初始化, 参数冻结。主要希望这两个模型的输出分布(log_prob)尽量相似。在
Actor模型中,给定一个prompt,它会生成response,每个token对应一个log_prob,记为log_probs。将prompt + response输入Reference 模型,得到每个token的ref_log_probs。两个模型输出分布的相似度可用KL散度计算衡量。即:ref_log_probs - log_probs, 该KL 散度将用于后续loss的计算。
- Actor Model,需要训练的策略模型,参数可训练。先喂给Actor一条prompt,让它生成对应的response。然后,再将“prompt + response"送入
-
Actor loss:
由上文推导,策略模型的损失函数如下表示。 N N N 表示同一
prompt, 生成 N N N 个response,T表示每条response有T个生成的token, 现在优化的目标:最大化下述目标函数。
o b j θ = 1 N ∑ n = 1 N ∑ t = 1 T R ( τ n − b ) ⋅ l o g p ( a t ∣ s t , θ ) obj_{\theta} = \frac{1}{N} \sum^{N}_{n = 1} \sum^{T}_{t = 1} R(\tau^{n} -b )·logp(a_t|s_t,\theta) \\ objθ=N1n=1∑Nt=1∑TR(τn−b)⋅logp(at∣st,θ)
变形1:$ R(\tau^{n})$ 是在句子级别上评估,表示
response级别的奖励优势,即response里所有token的奖励都一致,请仔细理解角标表示含义。现在用每个token的期望预估整体收益 V t V_t Vt 取代它,即response中生成的每个token分配的奖励不相同,虽然每个token整体收益不能直观获取,但是我可以用critic1模型去做收益期望估计呀?
o b j θ = 1 N ∑ n = 1 N ∑ t = 1 T V t ⋅ l o g p ( a t ∣ s t , θ ) obj_{\theta} = \frac{1}{N} \sum^{N}_{n = 1} \sum^{T}_{t = 1} V_{t}·logp(a_t|s_t,\theta) \\ objθ=N1n=1∑Nt=1∑TVt⋅logp(at∣st,θ)
当 V t > 0 V_t > 0 Vt>0 时,意味着Critic对Actor当前采取的动作给了正向反馈,因此就需要在训练迭代中提高 l o g p ( a t ∣ s t , θ ) logp(a_t|s_t,\theta) logp(at∣st,θ) .也就是:对 s t s_t st而言,如果采样 a t a_t at产生的收益较高,那就增大它出现的概率,否则降低它出现的概率。变形2:
为让 V t V_t Vt有正有负,上述奖励 ( R ( τ n ) − b R(\tau^{n}) -b R(τn)−b) 是减去一个base_line值。假设Critic对动作 a t a_t at的期望预测总收益为 V t V_t Vt,但实际总收益是 γ ∗ V t + 1 − V t \gamma * V_{t+1} - V_t γ∗Vt+1−Vt,那么期望预期总收益 V t V_t Vt 不就可以作为baseline了。即我希望当采用这个动作的奖励高于我的预期值。 即:定义优势如下:
A d v t = R t + γ ∗ V t + 1 − V t Adv_t = R_t + \gamma * V_{t+1} - V_t Advt=Rt+γ∗Vt+1−Vt
更新目标函数:
o b j θ = 1 N ∑ n = 1 N ∑ t = 1 T A d v t ⋅ l o g p ( a t ∣ s t , θ ) obj_{\theta} = \frac{1}{N} \sum^{N}_{n = 1} \sum^{T}_{t = 1}{Adv_t}·logp(a_t|s_t,\theta) \\ objθ=N1n=1∑Nt=1∑TAdvt⋅logp(at∣st,θ)
变形3:上文讲到需要将
Reference Model和Actor Model的KL散度纳入 loss 计算中,不至于模型训歪。怎么实现呢? 一个想法:相同状态 S t S_t St, 如果Actor Model采取的动作和Reference Model采取的动作一致,那我就增加一点奖励:(KL散度值),即修改即时收益: R t R_t Rt -> R t ′ R^{'}_{t} Rt′。
A d v t = R t ′ + γ ∗ V t + 1 − V t R t ′ = − k l − c t l ∗ ( l o g P ( A t ∣ S t ) P r e f ( A t ∣ S t ) ) + R t Adv_t = R^{'}_t + \gamma * V_{t+1} - V_t \\ R^{'}_t = -k l_- c t l * (log \frac{P(A_t|S_t)}{P_{ref}(A_t|S_t)}) + R_t Advt=Rt′+γ∗Vt+1−VtRt′=−kl−ctl∗(logPref(At∣St)P(At∣St))+Rt
到这里,恭喜您已经基本上学会PPO方法了,仔细理解下图,确保图的流程和上述公式能准确对上。
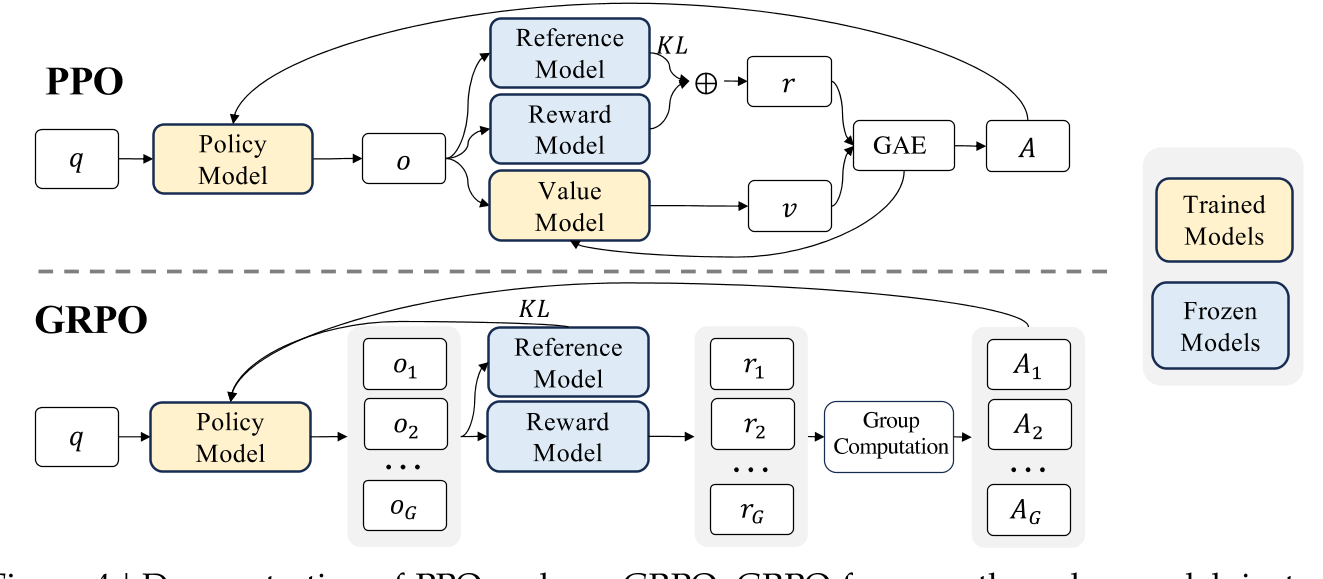
图中,显示
GAE算法,这么理解:对于收益 V t V_t Vt而言,分为即时 R t ′ R^{'}_{t} Rt′和未来 V t + 1 V_{t+1} Vt+1,那么对于优势而言,是不是也能引入对未来优势的考量呢?
A d v t = ( R t + γ ∗ V t + 1 − V t ) + γ ∗ λ ∗ A t + 1 \begin{align*}Adv_t = (R_t + \gamma * V_{t+1} - V_t) + \gamma * \lambda * A_{t+1}\end{align*} Advt=(Rt+γ∗Vt+1−Vt)+γ∗λ∗At+1
上述介绍了Policy model整体的损失函数设计,以及怎么变形到ppo算法的损失的。 -
Critic loss
常规
MSE损失函数:
C r i t i c _ l o s s = ( R t + γ ∗ V t + 1 − V t ) 2 Critic\_loss = (R_t + \gamma * V_{t+1} - V_t)^2 Critic_loss=(Rt+γ∗Vt+1−Vt)2
-
-
知识预备PPO算法
- 回顾一下整体流程:
- 生成Responses:将prompts批次输入Actor模型,生成相应的responses。在此过程中,可以设置不同的生成策略(如beam search、sampling等)以探索多样的输出。
- 计算 Responses 优势:将生成的"prompt + response"对输入Critic/Reward/Reference模型,评估每个response中每个token的奖励分数。
- 计算Loss:
- Actor Loss:基于Critic/Reward模型提供的奖励,计算策略梯度,以指导Actor模型的更新。
- Critic Loss:计算预测值与实际反馈值之间的差异,常用的方法包括均方误差(MSE)等,确保Critic模型能准确评估Actor的输出。
- 模型更新:使用计算出的actor和critic loss,通过反向传播算法更新Actor和Critic模型的参数。可以采用Adam、SGD等优化器,并适当调整学习率以稳定训练过程。
- 迭代优化:重复上述步骤,持续迭代优化模型。
-
off-policy:这部分强烈建议看下李宏毅的重要性采样的强化学习课程,怎么从
P(X)采样 转换为Q(X)分布采样的,并保证两者期望值一致。简单点介绍:引入另外一个策略 θ o l d \theta_{old} θold , 用 θ o l d \theta_{old} θold 收集到的数据去训练 θ \theta θ。假设我们可以用 θ o l d \theta_{old} θold收集到的数据去训练 θ \theta θ,意味着说可以把 θ o l d \theta_{old} θold收集到的数据用很多次,也就是可以执行梯度上升好几次,更新参数好几次。
∇ o b j θ = E τ ∈ θ o l d [ ( W e i g h t ) ⋅ R ( τ ) ∇ l o g P ( τ ∣ θ ) ] \nabla obj_{\theta} = E_{\tau \in \theta_{{old}}}[(Weight)· R(\tau) \nabla logP(\tau|\theta)] ∇objθ=Eτ∈θold[(Weight)⋅R(τ)∇logP(τ∣θ)]W e i g h t = p θ ( τ ) p θ o l d ( τ ) Weight = \frac{p_{\theta}(\tau)}{p_{\theta_{old}(\tau)}} Weight=pθold(τ)pθ(τ)
weight是重要性采样比 (Policy Ratio),衡量新旧策略之间的变化。 -
裁剪约束:
裁剪的目标函数:限制策略更新幅度,以避免剧烈变化导致模型崩溃。
a c t o r l o s s = − m i n ( A d v t ∗ P ( A t ∣ S t ) P o l d ( A t ∣ S t ) , A d v t ∗ c l i p ( P ( A t ∣ S t ) P o l d ( A t ∣ S t ) , 0.8 , 1.2 ) ) actor_{loss} = -min(Adv_t * \frac{P(A_t|S_t)}{P_{old}(A_t|S_t)}, Adv_t * clip(\frac{P(A_t|S_t)}{P_{old}(A_t|S_t)}, 0.8, 1.2)) actorloss=−min(Advt∗Pold(At∣St)P(At∣St),Advt∗clip(Pold(At∣St)P(At∣St),0.8,1.2))
GRPO算法
-
核心思想:群体相对策略优化 (GRPO,Group Relative Policy Optimization)。 通过在同一个问题上生成多条回答,评估彼此相关的响应组(彼此之间相互比较)来优化策略模型。
-
优点:
-
无Critic模型优化:GRPO 通过比较组内的响应消除了对
Critic模型的需求,从而显著减少了计算开销; -
相对评估:GRPO 不依赖外部评估者(
Critic模型),而是使用群体组来评估某个响应相对于同一批次中其他响应的表现如何。
-


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











