







 本文是Datacamp上PyTorch深度学习课程的学习笔记,介绍了张量创建与运算、构建基本神经网络、PyTorch数据集处理、训练过程以及预测方法。内容涵盖张量的初始化、激活函数、损失函数、数据预处理和模型训练等关键概念。
本文是Datacamp上PyTorch深度学习课程的学习笔记,介绍了张量创建与运算、构建基本神经网络、PyTorch数据集处理、训练过程以及预测方法。内容涵盖张量的初始化、激活函数、损失函数、数据预处理和模型训练等关键概念。
内容简介
本文为针对Datacamp上的Introduction to deep learning by pytorch课程的学习总结。Datacamp(官网链接)内含许多python的专题知识讲解,以几分钟的视频教学加在线编程实操为主。笔者在下两个博客中将总结pytorch中的基本张量创建以及其在深度学习当中的一些应用,最终将实现Alexnet并完成从读取数据到训练评估的全过程。本博客先总结tensor的基本运算,而后实现基本的全连接神经网络,下个博客将介绍卷积神经网络相关操作,并实现AlexNet。
tensor创建与基本运算
创建一个tensor
tensor_1 = torch.tensor([2.,-4.])
创建一个m行n列的tensor 每一个元素为0-1随机 此随机分布为均匀分布
tensor_1=torch.rand(m,n)

创建一个m行n列的tensor 每一个元素为均值为0 方差为1的高斯分布
tensor_1=torch.randn(m,n)
对二维tansor的索引 高维也如此
print(tensor_1[1][2])
修改tensor中的数值 tensor中每一个元素的类别为 torch.tensor
tensor_1[1][2]=3
print(tensor_1[1][2])
创建一个m行n列全为1的二维tensor
tensor_1 = torch.ones(m,n)
创建一个m行n列全为0的二维tensor
tensor_1 = torch.zeros(m,n)
创建一个n1行n2列的单位tensor(n1=n2) 当n2>n1时 多出来的列会全为0
tensor_1 = torch.eye(n,n)
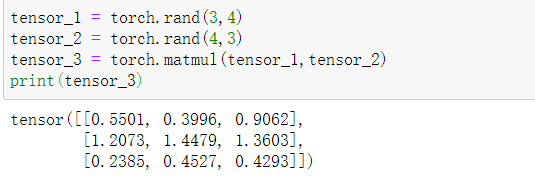
实现二维张量的点乘
tensor_3 = torch.matmul(tensor_1,tensor_2)
创建基本的神经网络 (PyTorch 风格)
当一个张量反向传播时需要求解梯度需要对张量进行如下说明
x = torch.tensor(4., requires_grad=True)
当我们希望数字4置换为上文提到的矩阵时,操作如下
tensor_1 = torch.rand(3,4)
tensor_1.requires_grad_(True)

一个简要的pytorch风格神经网络如下所示
import torch
import torch.nn as nn #torch.nn.Module 为所有模型的基类 此为继承关系
class Net(nn.Module): #继承基类
def __init__(self):
super 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









