







内容简介
本文介绍torchvision当中有关数据增强方法的使用以及其在街景字符编码识别项目起到的效果。
基本方法总结如下表
| 方法 | 效果 |
|---|---|
| transforms.Resize((m,n)) | 将原始图像进行resize |
| transforms.RandomCrop((m,n)) | 将原始图像进行随机剪裁 |
| transforms.CenterCrop((m.n)) | 取图像中心处进行一定大小的剪裁 |
| transforms.ColorJitter(a,b,c,d) | 调整原始图像有关颜色对比度等参数 |
| transforms.Grayscale(num_output_channels) | 将原始图像变为灰度图 |
| transforms.RandomHorizontalFlip(p) | 对原始图像进行随机水平翻转 |
| transforms.RandomVerticalFlip(p) | 对原始图像进行随机竖直翻转 |
| transforms.RandomRotation(a) | 随机使图像旋转一定的角度 |
| transforms.RandomErasing(p,scale,ratio,value,inplace) | 对原始图像进行仿射变换 |
| transforms.Pad(padding,fill,padding_mode) | 对原始图像周围进行元素补充 |
以下是对上述方法针对本次项目的应用,同时包含对函数中参数设置的详细说明。
应用效果
选取一张图片并进行读取
im = Image.open('D:/dawhale_cv1/input/train/000011.png')

对一张图片进行resize操作 输入参数为一个tuple 代表resize之后的图片大小
im_resize = transforms.Resize((100,100))(im) #resize

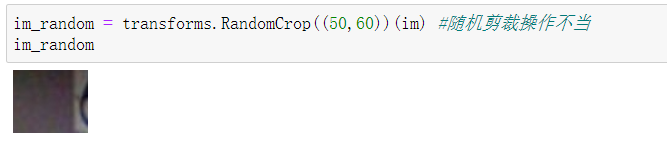
对一张图片进行随机剪裁操作,输入参数同上。当随机剪裁得当的时候,为下图效果
im_random = transforms.RandomCrop((60,100))(im)

可以看到如果选择一个较为准确得size来对原始图像进行剪裁,则能够获得较为突出的特征,这样有助于网络进行特征提取。如果选取的size出现的过小,则可能会导致获得的图片不足以让网络获得正确的含有数字的图片信息。如下图所示:
以一张图片的中心为基准,截取一定size的图片。输入变量同上。
im_center = transforms.CenterCrop((60.60)) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









