






 本文详细指导如何在虚拟机上安装JDK,配置Hadoop 3.2.1集群,包括设置固定IP、hostname,修改配置文件,实现SSH免密登录,并完成HDFS和YARN的初始化。
本文详细指导如何在虚拟机上安装JDK,配置Hadoop 3.2.1集群,包括设置固定IP、hostname,修改配置文件,实现SSH免密登录,并完成HDFS和YARN的初始化。
目录
8.3 master公钥scp 复制给slave1,slave2
1.文件准备
ubuntu-20.04.4-desktop-amd64.iso ISO安装包
hadoop-3.2.1.tar.gz
jdk-8u321-linux-x64.tar.gz
2.创建虚拟机
选择物理桥接网络,推荐配置,内存4G。
用户名hadoop
3.安装jdk
3.1 文件复制
jdk-8u321-linux-x64.tar.gz 文件复制到虚拟机~目录下
3.2 解压
目标目录创建文件夹,解压
sudo mkdir /usr/lib/jdk
sudo tar -zxvf ~/jdk-8u321-linux-x64.tar.gz -C /usr/lib/jdk3.3 添加环境变量
编辑~/.bashrc
sudo gedit ~/.bashrc
# 末尾追加如下代码
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_321
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/binsource ~/.bashrc#使配置文件生效
测试:
java
java -version 能正常返回值 说明jdk安装正常
4. 复制虚拟机
虚拟机关机 ,重命名虚拟机名称为master
VM界面虚拟机--管理--克隆 ,复制2份备份,命名为slave1,slave2
开启 3台虚拟机
5. 修改hostname
以master为例:
sudo gedit /etc/hostname将原主机名修改为master
save&exit;
slave1,slave2 同样执行上述操作
6. 修改固定ip
查看网卡信息 ,以master为例:
ifconfig # 报错则需要apt安装net-tool
sudo apt-get install net-toolsens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.5 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 240e:36a:141e:600:db57:dd90:6371:9f2e prefixlen 64 scopeid 0x0<global>
inet6 fe80::38a5:3201:f026:f414 prefixlen 64 scopeid 0x20<link>
inet6 240e:36a:141e:600:df5e:846e:ea64:b1a prefixlen 64 scopeid 0x0<global>
ether 00:0c:29:52:00:86 txqueuelen 1000 (Ethernet)
RX packets 1906 bytes 246781 (246.7 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 726 bytes 80999 (80.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 428 bytes 35933 (35.9 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 428 bytes 35933 (35.9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
当前ip地址为192.168.1.5
修改配置文件
Ubuntu从17.10开始,取消在 /etc/network/interface 配置网卡,改为在/etc/netplan/XX-installer-config.yaml的yaml文件中配置IP地址。
cd /etc/netplansudo cp 01-network-manager-all.yaml ./01-network-manager-all.yaml.back备份并且修改
sudo gedit 01-network-manager-all.yaml
替换输入以下字符:
network:
ethernets:
ens33:
dhcp4: false
addresses: [192.168.1.210/24]
gateway4: 192.168.1.1
nameservers:
addresses: [192.168.1.1,8.8.8.8]
version: 2
更新配置
sudo netplan applycheck:
ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.210 netmask 255.255.255.0 broadcast 192.168.1.255
ether 00:0c:29:52:00:86 txqueuelen 1000 (Ethernet)
RX packets 4585 bytes 1649116 (1.6 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1972 bytes 196533 (196.5 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 779 bytes 65649 (65.6 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 779 bytes 65649 (65.6 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ip为配置文件预设ip,修改生效
另:桌面版ubuntu可以直接在网络设置处配置静态IP
slave1,slave2 同样执行上述操作
slave1 192.168.1.211
slave2 192.168.1.212
7.修改hosts文件
ubuntuhosts文件在 /etc/hosts
sudo gedit /etc/hosts 127.0.0.1 localhost
# 127.0.1.1 ubuntu# 注释掉127.0.1.1 ubuntu
# 添加如下 :
192.168.1.210 master
192.168.1.211 slave1
192.168.1.212 slave2
slave1,slave2 同样执行上述操作
8.ssh免密登录
8.1 查看ssh服务
ps -e | grep ssh只有ssh-agent没有sshd 的服务,则需要安装 openssh-server
sudo apt-get install openssh-server
check:
ps -e | grep ssh
#有 sshd
ok
8.2 master 主机生成公钥 :
ssh-keygen -t rsa按3次回车即可。
ls ~/.ssh/ 有这些文件 (id_rsa ,id_rsa.pub,known_host)
将id_rsa.pub(公钥) 写入到 ~/.ssh/authorized_keys 中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysssh localhost
#第一次输入yes ,成功连接 ,退出
ssh master
# 不需要密码
8.3 master公钥scp 复制给slave1,slave2
scp ~/.ssh/id_dsa.pub hadoop@slave1:~/
scp ~/.ssh/id_dsa.pub hadoop@slave2:~/ 在slave1,slave2执行:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys测试免密连接 :
在master主机输入:
ssh slave1
ssh slave2
#不用输入密码 ,ok
如有异常:
删除三台机器 authorized_keys文件内容后,重新在master执行 ssh-keygen 命令生成pub秘钥,再scp到集群主机,追加到authorized_keys
9. 安装hadoop集群,修改配置文件
master主机先安装并配置好hadoop,再传递hadoop文件到slave集群。
9.1 安装包解压
执行以下命令:
sudo tar -zxvf ~/hadoop-3.2.1.tar.gz -C /usr/local/#文件解压到 /usr/local/
#hadoop-3.2.1文件夹重命名为hadoop
sudo mv /usr/local/hadoop-3.2.1 /usr/local/hadoophadoop文件目录,由于是外源解压来,用户和用户组可能是1001,1001
修改用户和用户组,为当前用户
sudo chown -R hadoop /usr/local/hadoop
sudo chgrp -R hadoop /usr/local/hadoop各个用户组,授权读写
sudo chmod -R 775 /usr/local/hadoop9.2 修改配置文件
Hadoop 的各个组件均用XML文件进行配置, 配置文件都放在 /usr/local/hadoop/etc/hadoop 目录中:
- core-site.xml:配置通用属性,例如HDFS和MapReduce常用的I/O设置等
- hdfs-site.xml:Hadoop守护进程配置,包括namenode、辅助namenode和datanode等
- mapred-site.xml:MapReduce守护进程配置
- yarn-site.xml:资源调度相关配置
- workers : hadoop工作主机
9.2.1 修改 core-site.xml
cd /usr/local/hadoop/etc/hadoop
sudo gedit ./core-site.xml新增
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property></configuration>
参数说明:
- fs.defaultFS:默认文件系统,HDFS的客户端访问HDFS需要此参数
- hadoop.tmp.dir:指定Hadoop数据存储的临时目录,其它目录会基于此路径, 建议设置到一个足够空间的地方,而不是默认的/tmp下
- hadoop.proxyuser.用户名.hosts /hadoop.proxyuser.用户名.groups ,分别为允许代理的超级用户名和允许的主机地址(hosts文件中映射的主机名)。(hive等其它组件要用到hdfs和yarn需要配置用户代理,如果只启动集群,此项可以暂时忽略)
note:
如没有配置
hadoop.tmp.dir参数,系统使用默认的临时目录:/tmp/hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
9.2.2 修改 hdfs-site.xml
复制保存如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode, owner or group of files or directories.
</description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
</configuration>
参数说明:
- dfs.replication:默认datanode备份文件个数
- dfs.name.dir:指定Hadoop数据namenode文件存储目录
- dfs.data.dir:指定Hadoop数据datanode文件存储目录
9.2.3 修改 mapred-site.xml
复制保存如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
9.2.4 修改 yarn-site.xml
复制保存如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
<description>default value is 1024</description>
</property></configuration>
9.2.5 修改workers
master
slave1
slave2
如果输入master,slave1,slave2 ,则master节点也有datanode进程
输入slave1,slave2 ,则master不参与DataNode,且没有secondarynamenode
9.3 复制到slave集群
master主机打包目录
tar -zcvf hadoop.tar.gz /usr/local/hadoop发送到slave
scp hadoop.tar.gz hadoop@slave1:~/
scp hadoop.tar.gz hadoop@slave2:~/解压
tar -zxvf ~/hadoop.tar.gz /usr/local/--注意文件路径 可能解压到其它目录需要移动
同 9.1 ,给文件授权。
9.4 添加hadoop环境变量
sudo vi ~/.bashrc# 配置文件末尾添加
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
9.5 启动集群
9.5.1 master 首次 HDFS格式化
hadoop namenode -format
控制台出现INFO,没有ERROR , 表示格式化成功
9.5.2 启动集群
cd /usr/local/hadoop
./sbin/start-all.shhadoop@master-msi:/usr/local/hadoop$ ./sbin/start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [master-msi]
Starting datanodes
slave1-msi: WARNING: /usr/local/hadoop/logs does not exist. Creating.
Starting secondary namenodes [master-msi]
Starting resourcemanager
Starting nodemanagers
hadoop@master:/usr/local/hadoop$ j
异常处理 :
ERROR: JAVA_HOME is not set and could not be found.
修改$HADOOP_PATH 目录下 /etc/hadoop/ hadoop-evn.sh 文件,找到 #export JAVA_HOME ,取消注释,输入
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_321
也可单独启动sbin目录下 start-dfs.sh 和 start-yarn.sh
可在浏览器访问:http://master:9870 HDFSweb
可在浏览器访问:http://master:8088 YARNweb
10. 访问测试
10.1 命令行测试HDFS
hadoop@master:~$ hadoop fs -mkdir /aaa
hadoop@master:~$ hadoop fs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2022-03-07 00:51 /aaa#文件权限为755
10.2 hadoop HDFSweb总览页面
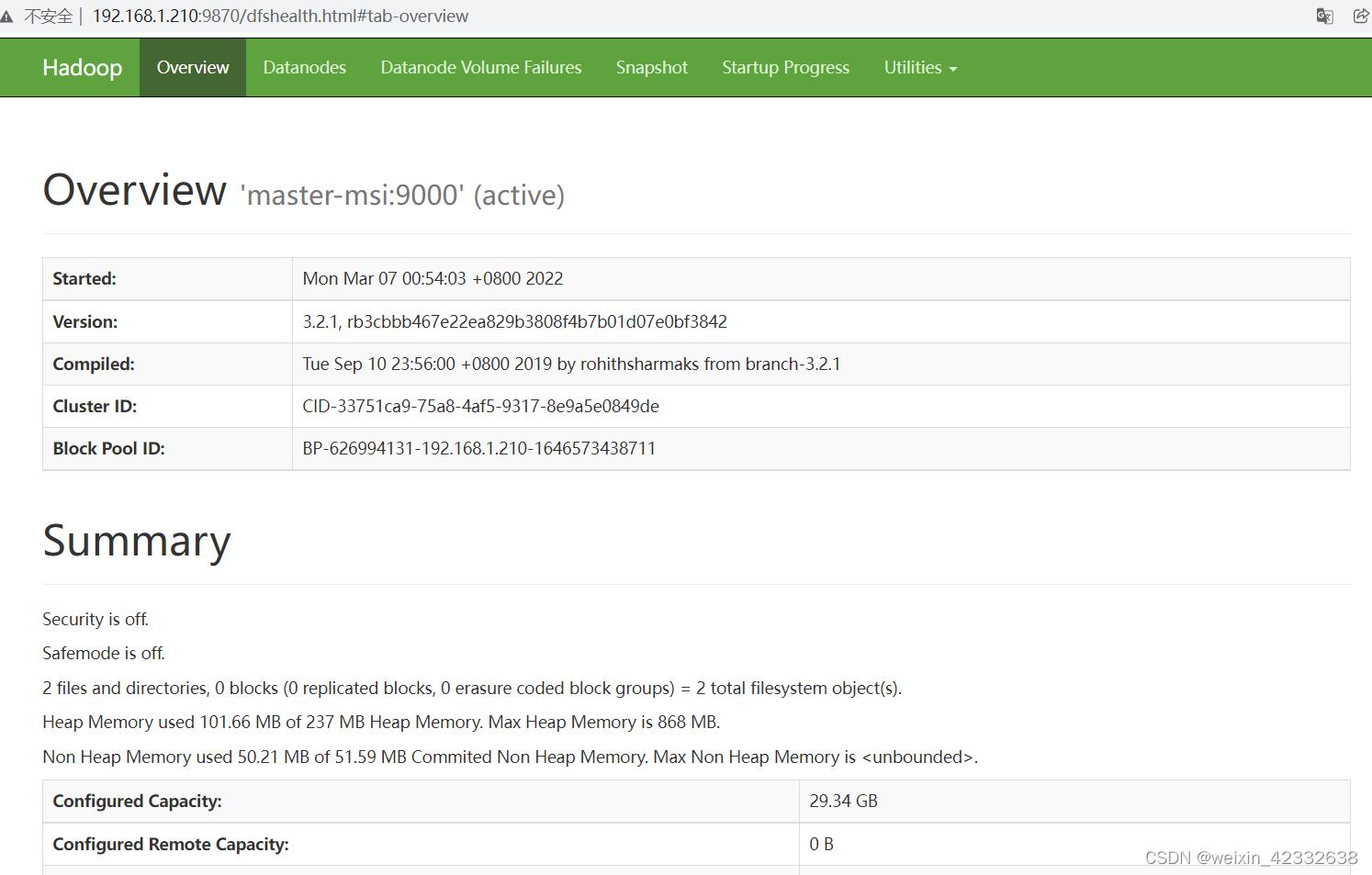
10.3 WEB端文件索引页面:
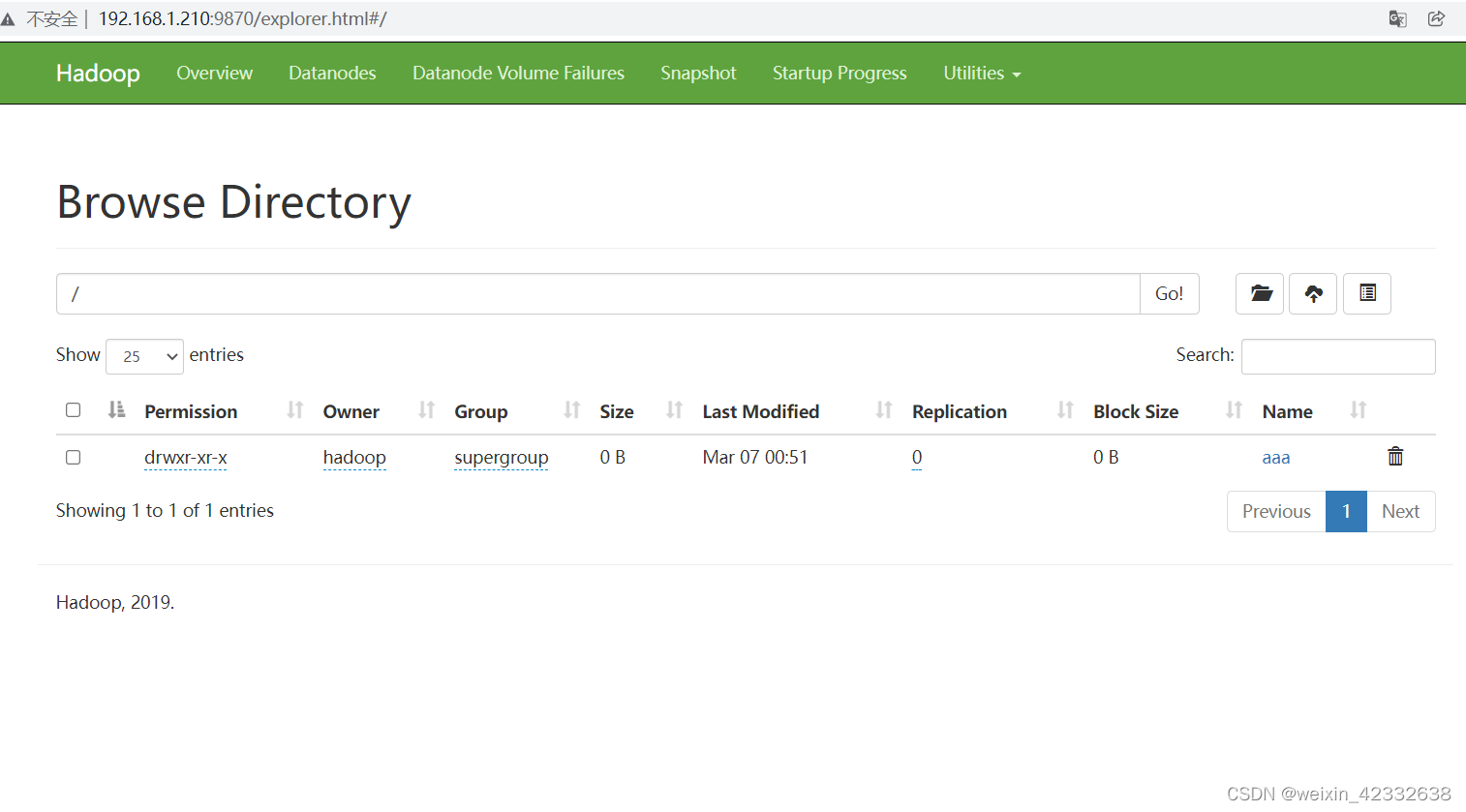
10.4 yarn的WEB页面:
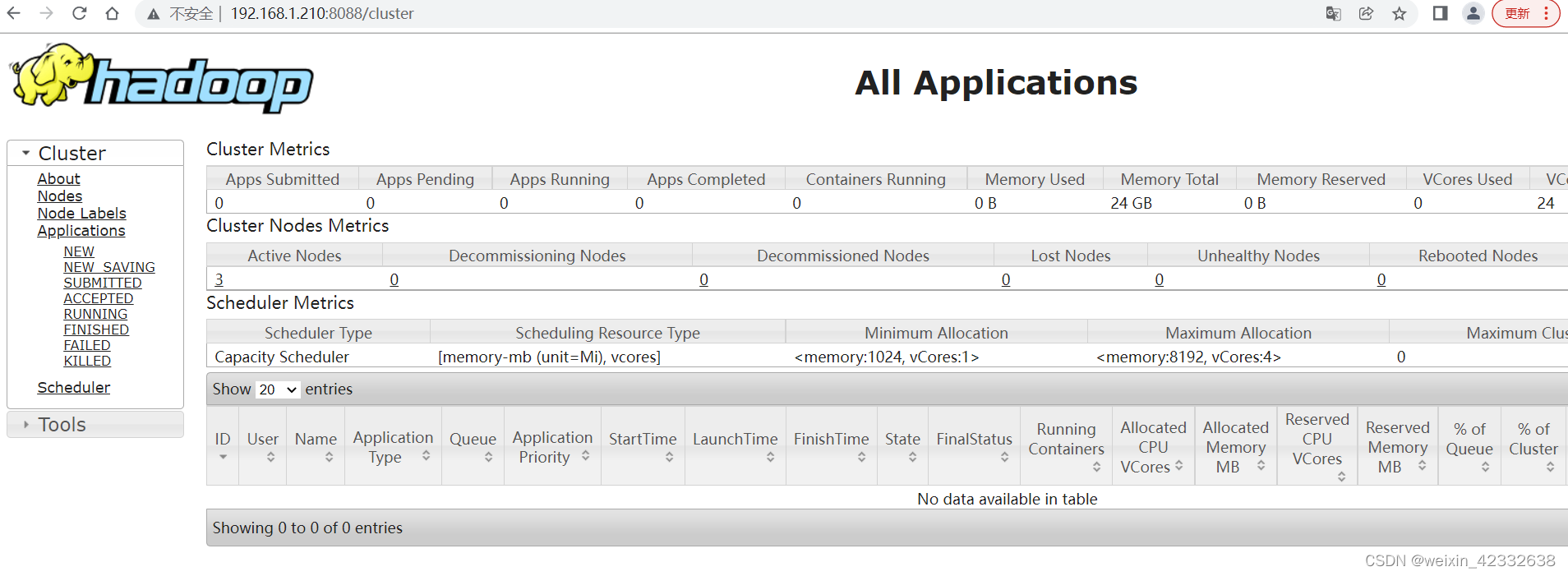
hadoop3.0端口已有50070改为9870
完结~

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









