






 文章描述了在Ubuntu虚拟机中使用PyCharm连接Oracle19C执行Python脚本时遇到的问题。当尝试调用存储过程时,出现DPI-1047错误,原因是缺少64位Oracle客户端库。解决方案包括下载OracleInstantClient,上传到Linux,解压,修改配置文件,然后执行相关命令解决问题。最后,文章展示了如何使用Python查询Oracle数据库并展示数据。
文章描述了在Ubuntu虚拟机中使用PyCharm连接Oracle19C执行Python脚本时遇到的问题。当尝试调用存储过程时,出现DPI-1047错误,原因是缺少64位Oracle客户端库。解决方案包括下载OracleInstantClient,上传到Linux,解压,修改配置文件,然后执行相关命令解决问题。最后,文章展示了如何使用Python查询Oracle数据库并展示数据。
1.运行环境
客户端1:pycharm :ubuntu虚拟机 --连接oracle客户端执行python脚本
客户端2:oracle19C客户端:centos虚拟机
2.运行脚本、报错处理
2.1 安装cx_oracle包
PIP直接安装即可,或者在pycharm界面搜索安装
2.2 oracle客户端执行存储过程
用windows--plsql客户端、或者Navicat等能连接oracle执行sql的工具,执行存储过程。如下:
创建表,有相同表名删除,没有相同表名直接创建,最后按传入参数写入数据
create or replace procedure p_test_123(tname varchar2,
xingming varchar2,
vline int) as
v_tname varchar2(50) := tname;
v_xingming varchar2(20) := xingming;
v_vline int := vline + 1;
v_cnt int := 10;
v_sql varchar(200);
a int := 1;
v_insert_sql varchar(200);
begin
DBMS_OUTPUT.ENABLE(buffer_size => null);
select count(1)
into v_cnt
from user_tables
where table_name = upper(v_tname);
if v_cnt = 0 then
dbms_output.put_line('没有 ' || v_tname || ' 这张表,需要创建。');
v_sql := 'create table ' || v_tname ||
'(id int , name varchar2(20), email varchar2(30))';
dbms_output.put_line(v_sql);
execute immediate v_sql;
dbms_output.put_line('建表成功。');
else
dbms_output.put_line('有 ' || v_tname || ' 这张表,删除后重建。');
execute immediate 'drop table ' || v_tname;
dbms_output.put_line('删除成功。新建表。');
v_sql := 'create table ' || v_tname ||
'(id int , name varchar2(20), email varchar2(30))';
execute immediate v_sql;
end if;
dbms_output.put_line('开始给 ' || v_tname || ' 表写入数据。');
while a < v_vline loop
v_insert_sql := 'insert into ' || v_tname || ' values(' || a || ',' || '''' ||
v_xingming || a || '''' || ',' || '''' || v_xingming || a ||
'@126.com' || '''' || ')';
dbms_output.put_line(v_insert_sql);
execute immediate v_insert_sql;
--dbms_output.put_line(a || '次成功写入。');
a := a + 1;
end loop;
commit;
end;2.3 python-pycharm客户端 执行python脚本调用存储过程
代码如下:
import cx_Oracle as cx
import pandas as pd
# address = "用户名/密码@IP:端口/实例名"
# conn = cx.connect(address, encoding='UTF-8')
# 创建连接信息
dsn = cx.makedsn('192.168.0.160', '1521', 'ORCL19C')
# 创建连接用户
conn = cx.connect('c##bing', '123456', dsn)
cur = conn.cursor()
# 调用有参数的存储过程
# cur.callproc('p_test_123', ['test_a', 'theshy', 10000])
print(cur.callproc('p_test_123', ['test_a', 'theshy', 10000]))这里执行报错:
cx_Oracle.DatabaseError: DPI-1047: Cannot locate a 64-bit Oracle Client library: "libclntsh.so: cannot open shared object file: No such file or directory". See https://cx-oracle.readthedocs.io/en/latest/user_guide/installation.html for help
意思是说本地没有64位的libclntsh.so库,需要安装。
2.3.1 报错分析解决
就像windows客户端软件(plsql、navicate、dbeaver等)连接oracle服务端时候需要安装客户端插件一样,linux上运行python连接oracle也需要安装插件。
2.3.2 下载插件
下载地址:Instant Client for Linux x86-64 (64-bit) (oracle.com)
2.3.3 上传、解压
windows上传 :win+R cmd打开命令窗口
### 转到sftp命令行
sftp host_username@hostip:/home/python
### put命令传输windows指定文件
put C:\Users\xxx\Downloads\instantclient-basic-linux.x64-21.10.0.0.0dbru.ziplinux解压
sudo unzip -d /opt/oracle ./instantclient-basic-linux.x64-21.10.0.0.0dbru.zip2.3.4 修改文件、执行命令
sudo vim /etc/ld.so.conf添加一行 /opt/oracle/instantclient_21_10
再执行
sudo ldconfig
ldd /opt/oracle/instantclient_21_10/libclntsh.so执行结果如下:
linux-vdso.so.1 (0x00007ffd61898000)
libnnz21.so => /opt/oracle/instantclient_21_10/libnnz21.so (0x00007f4f61b16000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f4f61b10000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f4f619c1000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f4f6199e000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f4f61994000)
libaio.so.1 => /lib/x86_64-linux-gnu/libaio.so.1 (0x00007f4f6198f000)
libresolv.so.2 => /lib/x86_64-linux-gnu/libresolv.so.2 (0x00007f4f61971000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f4f6177f000)
/lib64/ld-linux-x86-64.so.2 (0x00007f4f66590000)
libclntshcore.so.21.1 => /opt/oracle/instantclient_21_10/libclntshcore.so.21.1 (0x00007f4f611cf000)
没有错误,安装完成。
重新执行python代码,结果如下:
['test_a', 'theshy', 10000]
进程已结束,退出代码0
报错解决。
3. python查询数据
3.1 查询表后10行数据
这里id 10000-9991是对的
# 查询表后10行数据 这里id 10000-9991是对的
select_sql = 'select id,name,email from (select id,name,email,row_number()over(order by id desc) as px from test_a) where px <=10'
cur.execute(select_sql)
lines = cur.fetchall()
for i in lines:
print(i)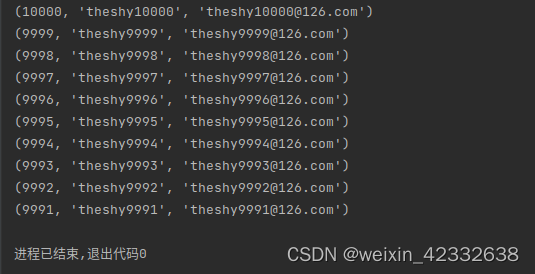
ok
3.2 将查询结果展示成Dataframe
# 将查询数据转换dataframe
# 游标数据是列表嵌套元组,在dataframe中,元组无法添加,需要转换成列表
df_data = list()
for x in lines:
df_data.append(list(x))
# print(df_data)
# 游标的description 是列名和相应的属性:字符类型等
titles = cur.description
# print(titles)
# 取列表每个元组的索引[0]为一个新的列表,即字段名 赋值给dataframe
row = list()
for y in range(len(titles)):
row.append(titles[y][0])
# print(row)
result = pd.DataFrame(df_data, columns=row)
print(result)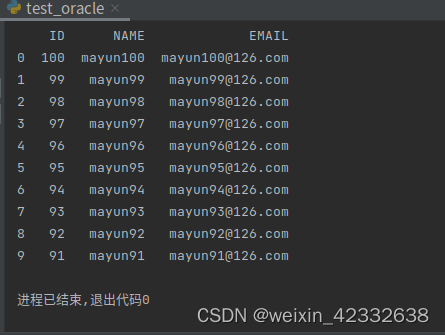
改了存储过程中2,3参数,结果如上。OK
完~

















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









