







论文链接:https://arxiv.org/pdf/1511.06581.pdf
Dueling DQN 使用了一种新的神经网络结构。Dueling 网络有两个独立的估计量:
- 状态值函数的估计量
- 依赖状态的动作优势函数的估计量
这种分解的主要好处是在不改变底层强化学习算法的情况下,将学习泛化到多个动作。
定义了新的优势函数:
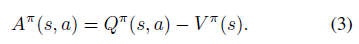
值函数 V 衡量的是特定状态 s 有多好,动作值函数 Q 衡量的是在这个状态下选择某一动作的值。优势函数是 Q 减去 V 的值,得到的是每个动作重要性的相对度量。
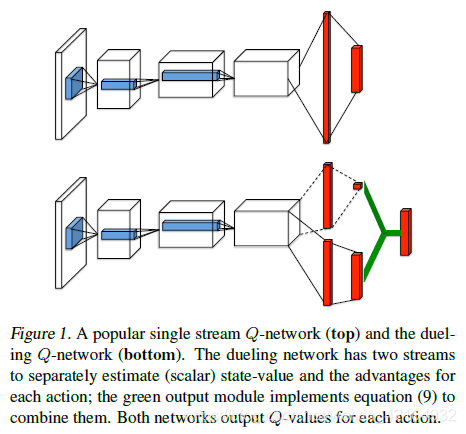
上图给出了 Dueling 网络的结构,可见,最后的全连接层是有两个分支组成(一支输出标量的 V 值,另一支输出向量 A),最后的输出是两者的相加。使用优势函数的定义,可以得到 Q 值的表示方式:
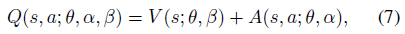
由于给定一个Q,无法给出一个唯一的 V 和 A 。强制使得优势函数估计器在选择的动作上具有零优势,公式修改为:
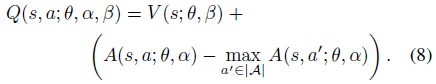
另外,可以使用均值替代 max 操作:
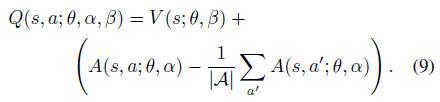


















 1169
1169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









