







相比于原版的DQN,改进在于输出。
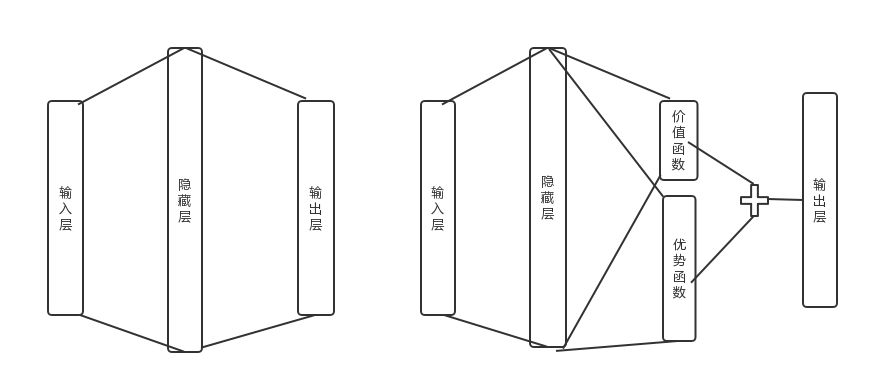
原本的DQN只在输出的时候按照动作数量,进行输出。
dueling DQN从常识出发,将输出分为价值函数和动作函数,价值函数输出一个实数,表示对当前局势的价值量,动作函数输出每个动作的价值。
这个改进并没有理论上的解释,就是单纯凑出来好用。
原版DQN网络的输出:
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
x = self.hidden(x)
x = self.out(x)
return x在输出端的改进,代码对比:
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
adv = self.hidden_adv(x)
val = self.hidden_val(x)
adv = self.adv(adv)
val = self.val(val).expand(x.size(0), self.num_actions)
x = val + adv - adv.mean(1).unsqueeze(1).expand(x.size(0), self.num_actions)
return x

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









