









arXiv'24
论文原文下载地址:论文原文
1 引言
1.1 Motivation:
- 尽管科学文献和专门的生物医学数据库可以提供丰富的AD(阿尔茨海默病)知识,由于信息量巨大,人工审查相关信息不现实。
- 虽然 LLMs 在许多一般任务中表现出了良好的性能,但最近的研究却揭示了 LLMs 在长尾知识和特定领域知识方面的局限性,从而极大地阻碍了它们在 AD 等垂直领域的适应性。
- 为解决这一问题,最常见的策略是检索增强生成(RAG)和特定领域 LLMs 训练。但会遇到以下问题:
- 数据质量:科学文献构成了 AD 领域最大的公开可用语料库。然而,科学文献的密集性和信息过载性与自动检索方法相结合,可能会导致检索到不相关和有噪声的信息。以往的研究表明,嘈杂和不相关的语料会严重影响 LLM 的性能
- 效率和规模问题:AD知识正随着科学进步以惊人的速度和规模迅速发展。然而,重新训练特定领域的 LLM 或更新其中的某些知识需要大量的计算资源。这一效率问题也会限制特定领域LLM的大小,从而影响其性能。
1.2 本文提出DALK(LLM 和 KG 的动态协同增强框架):
- 解决数据质量难题:利用 LLM 从 AD 相关科学文献中提取更多结构化和更准确的知识,并构建一个不断演化的 AD 特定知识图谱 (KG)。构建方法:
- 成对构建(Carta等人,2023年;Wadhwa等人,2023年)
- 生成构建(Han等人,2023年;Bi等人,2024年)
- 进一步解决数据质量和效率问题:利用一种从粗到细的抽样方法和一种新颖的自我感知知识检索方法,从 KG 中选择适当的知识来增强 LLM 的推理能力。
1.3 评估部分:
- 从现有的普通医疗质量保证数据集中推导出了AD问题解答(ADQA)基准
- 包含数百万个经策划的关键词列表和 LLM 自采样过滤的样本。
- 在ADQA基准上进行的实验结果证明了 DALK 的有效性。
DALK有助于:在大规模和基于 API 的语言模型中的应用(OpenAI,2022 年)。
代码和数据:https://github.com/David-Li0406/DALK
2 方法框架
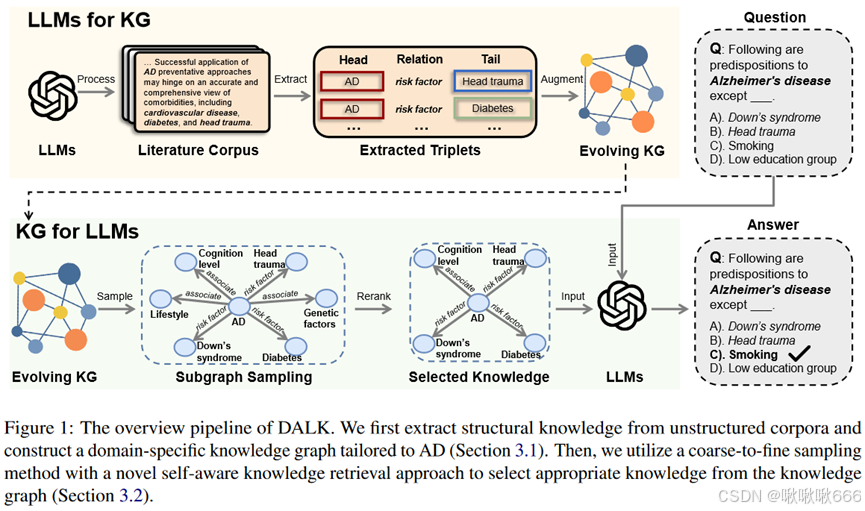
2.1 LLM4KG
语料库收集:
墨尔本大学的Colin Masters教授发现淀粉样蛋白是导致注意力缺失症的潜在原因,该语料库基于他广泛的代表性 AD 相关论文的书目,包括从 1977 年到 2021 年超过 16K 篇 PMID(PubMed ID)索引文章。在本文的研究中,本文重点研究了 2011 年以来的论文,这些论文反映了该领域的最新知识,共获得了 9,764 篇文章。
实体识别:
为了在适当的粒度水平上识别AD知识,用由NCBI开发并持续维护的PubTator Central(PTC)(Wei等人,2013年)从语料库中提取相关实体。
- PTC :一种广泛使用的工具,可为 PubMed 摘要和全文文章提供最先进的生物医学概念注释,它支持六种生物概念类型,包括基因、疾病、化学物质、突变、物种和细胞系。将 PTC 应用于所有 AD 论文的摘要,并获得相关命名实体,这些实体将作为知识图谱中的节点。
关系提取:
目前使用 LLM 的方法分为两大类(图 2):
(a).成对关系提取:旨在促使 LLMs 描述一段文本中任意两个实体之间的关系
(b).生成关系提取:LLM 直接输出所有相关实体对及其相应关系
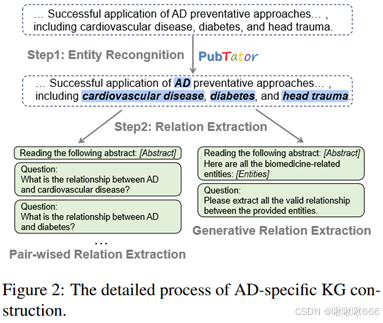
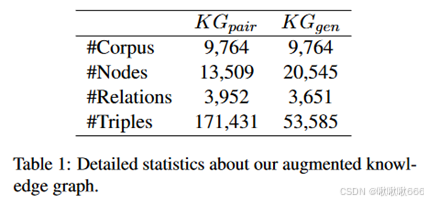
将这两种关系提取方法都纳入了知识图谱增强过程,以便对它们进行全面比较。将这两种方法得出的知识图谱分别称为 KGpair 和 KGgen


3.1 KG4LLM
粗粒度知识样本:
给定一个问题查询 Q
- 构建一个提示,要求 LLM 从Q中提取所有特定领域的实体 E = {e1, e2, ...}。
- 实体链接(基于相似性),将 E 中的所有实体连接到知识图谱 G 中的实体结构。(参考Wen 等人(2023 年)提出的方法,)
- 将 G 和 E 中的所有实体编码为密集嵌入,分别记为 HG 和 HE(利用语义相似性模型(Reimers 和 Gurevych,2019 年))。
- 在 E 中的每个实体与其在 G 中的最近邻实体之间建立联系(利用余弦相似性)。
- 建立证据子图以促进 LLMs 的推理过程,( Wen 等人,2023 年),并考虑在 AD-KG 中进行以下两种探索:
- 基于路径的探索。从 G 中提取一个子图,以包含 EG 中的所有实体。
- 基于邻域的探索。努力增加 GQ 中与查询相关的证据。

- 在得到两个子图之后进行后处理,进一步剪除子图中的冗余信息,并促使 LLM 描述每个子图的结构。
自我意识知识检索:
用上述方法采样的粗粒度知识:
- 缺点:仍然包含冗余和不相关的信息。
- 挑战:
- 是自动构建KG时经常遇到的难题。
- 最近研究都证明 LLMs 会受到此类噪声信息的影响。
- 本文:提出了一种自感知知识检索方法,利用 LLMs 的排序能力来过滤噪声信息。
- 总体思路:直接提示 LLM 对采样知识进行重新排序,并只检索前 k 个三元组,以便在最后一轮推理中提供给自己。
- 过程:
- 给定:问题 Q、基于路径或基于邻居的子图 GQ
- 通过填写预定义模板来创建提示语
- 输入提示语,提示 LLM 获取自我检索的知识
- 将问题 Q 和细粒度知识 Gself Q 提供给 LLM 进行推理,并分两步得到预测答案 a



















 3621
3621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









