









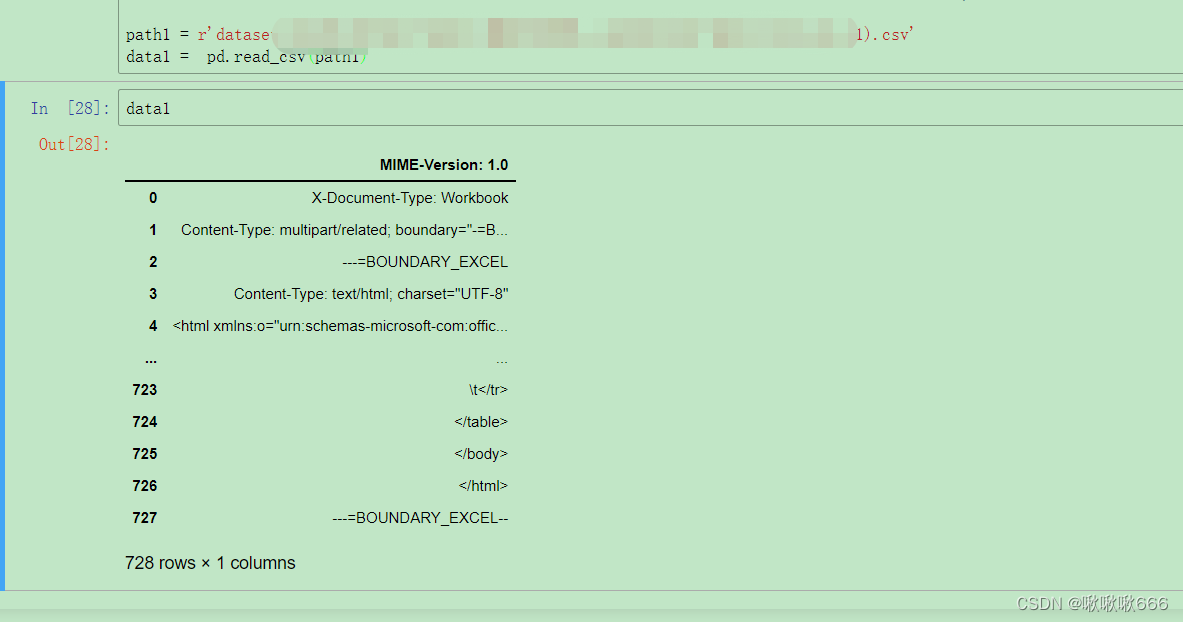
解决方式:
1、将xls文件后缀转换为csv文件,再进行读取。
这种方式虽然读取后程序不再报错,但文件格式会发生改变,影响操作。
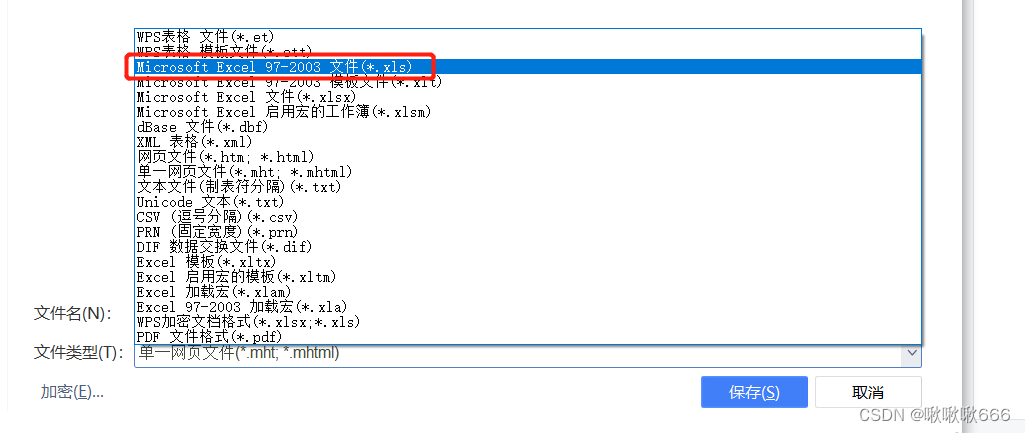
2、 将xls文件另存为xlsx文件
如果读取的文件不多,对于每个文件,以次打开,另存为Microsoft Excel 97-2003文件(*.xls) ,再对另存的.xls文件进行读取即可
如果读取的文件有很多个,需要批量转换为xlsx文件。批量转换方法:
#encoding: utf-8
from ctypes import *
import time
import win32com.client as win32
import os
def transform(parent_path,out_path):
fileList = os.listdir(parent_path) #文件夹下面所有的文件
num = len(fileList)
for i in range(num):
file_Name = os.path.splitext(fileList[i]) #文件和格式分开
print(file_Name)
if file_Name[1] == '.xls':
print(file_Name[0])
transfile1 = parent_path+'/'+fileList[i] #要转换的excel
print(transfile1)
transfile2 = out_path+'/'+file_Name[0] #转换出来excel
excel=win32.gencache.EnsureDispatch('excel.application')
pro=excel.Workbooks.Open(transfile1) #打开要转换的excel
pro.SaveAs(transfile2 + ".xlsx", FileFormat=51) # 另存为xlsx格式
pro.Close()
excel.Application.Quit()
if __name__=='__main__':
# 注意:这里要写绝对路径。否则会报错:pywintypes.com_error: (-2147352567, '发生意外。', (0, 'Microsoft Excel', '抱歉,无法找到 *.xlsx。是否可能被移动、重命名或删除?', 'xlmain11.chm', 0, -2146827284), None)
path1=r"E:\practice\jupyternotebook\DaDong\dataset/2021年1月大东厂进水口" #待转换文件所在目录
path2=r"E:\practice\jupyternotebook\DaDong\dataset/111" #转换文件存放目录
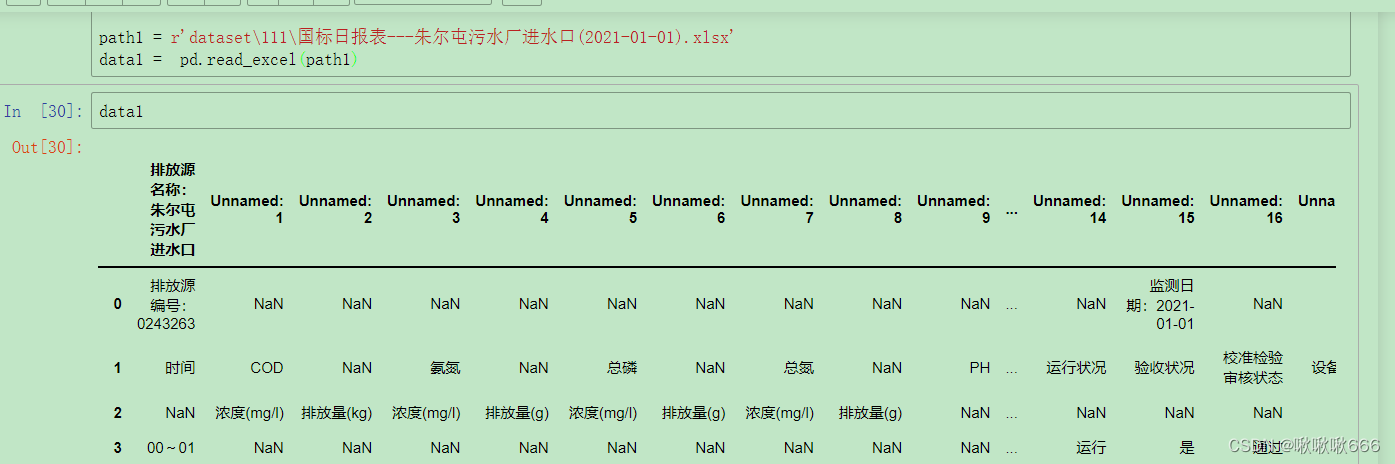
transform(path1, path2)转换后再读取.xlsx文件就可以了

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









