







一、安装Blast+
实验室的工作站安装的是Linux系统(Ubuntu 24.04 LTS),因此以下操作均是基于Linux系统展开,Windows系统还没实操过。最新版Blast+工具可以通过FTP方式获得,点击这里(不要开VPN!),可以看到有各种版本的Blast工具,找到Linux系统的版本右键复制下载链接。有博主建议将md5校验文件一起下载,因为谁都不知道下载过程中是否会出错,因此大的文件下载完以后需要验证一下文件完整性!
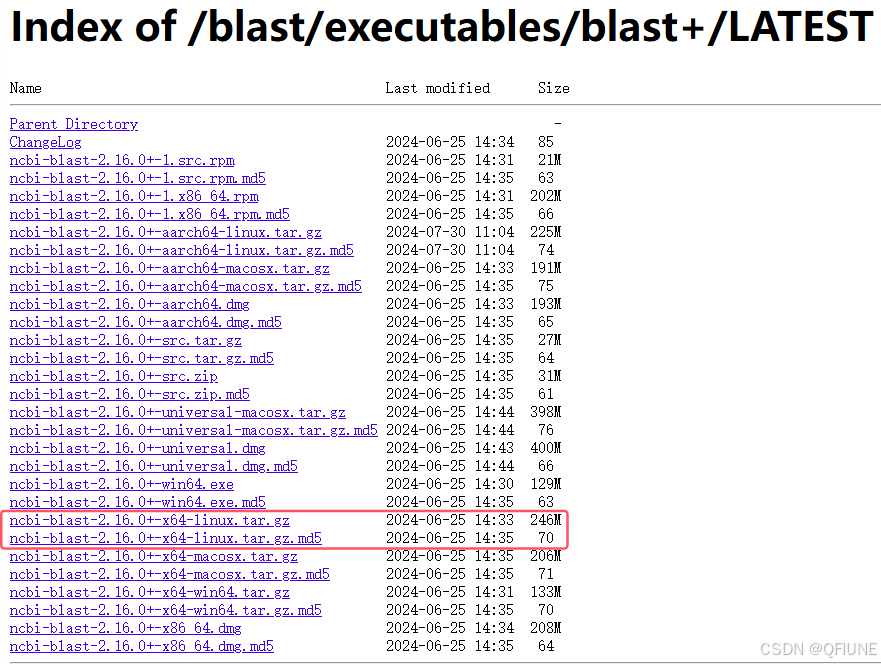
然后到终端运行,我的路径在 /home/software,确保你的路径有 “可读可写可执行” 权限:
wget https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/ncbi-blast-2.16.0+-x64-linux.tar.gz
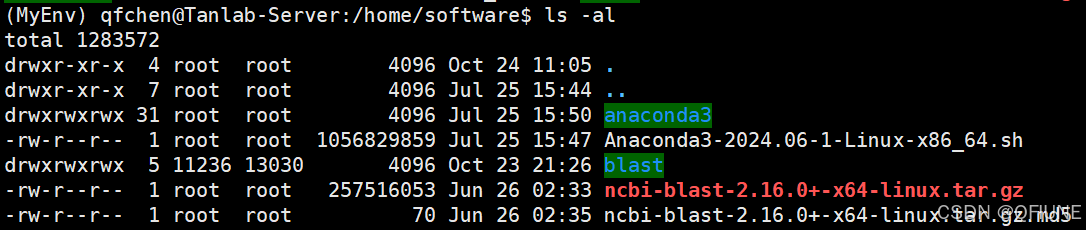
wget https://ftp.ncbi.nlm.nih.gov/blast/executables/blast+/LATEST/ncbi-blast-2.16.0+-x64-linux.tar.gz.md5如下图所示是下载好的文件:
首先在对应的目录下校验文件完整性:
md5sum -c ncbi-blast-2.16.0+-x64-linux.tar.gz.md5
ncbi-blast-2.16.0+-x64-linux.tar.gz: OK显示结果OK后,将tar包解压缩:
tar -zxvf ncbi-blast-2.16.0+-x64-linux.tar.gz得到解压之后的文件夹,发现文件夹名字太长了,重命名为blast:
mv ncbi-blast-2.16.0+ blast接下来配置环境变量。进入blast文件夹里面的 bin 目录。输入pwd ,查看并复制当前路径,在终端输入:
echo 'PATH=$PATH:/home/software/blast/bin/' >> ~/.bashrc
source ~/.bashrc或者,
export PATH="/home/software/blast/bin:$PATH" >> ~/.bashrc
source ~/.bashrc这样Blast+工具就装好了。
二、安装Aspera
blast/bin里面提供了一个脚本update_blastdb.pl 可以方便下载blast数据库,但是很慢,还老中断。所以最后还是得求助IBM的aspera加速器。这里我们先说一下怎么使用这个脚本吧。万一有网速不慢的朋友呢,是吧!

首先用以下命令查看有哪些数据库可供下载:
perl update_blastdb.pl --showall结果如下:
16S_ribosomal_RNA
ITS_RefSeq_Fungi
28S_fungal_sequences
Betacoronavirus
LSU_eukaryote_rRNA
ITS_eukaryote_sequences
LSU_prokaryote_rRNA
SSU_eukaryote_rRNA
env_nt
env_nr
human_genome
landmark
mito
mouse_genome
nr
nt_euk
nt
nt_others
nt_prok
pataa
nt_viruses
patnt
pdbaa
pdbnt
ref_euk_rep_genomes
ref_prok_rep_genomes
ref_viroids_rep_genomes
ref_viruses_rep_genomes
refseq_select_rna
refseq_select_prot
refseq_protein
refseq_rna
swissprot
tsa_nr
tsa_nt
taxdb
core_nt
18S_fungal_sequences
如要下载nr库,用以下命令(后台下载):
nohup perl update_blastdb.pl --decompress nr &> update.log &上面就是用blast自带的下载脚本下载数据的过程。
我们现在开始研究怎么下载aspera,有两种方式,①下载源码直接安装;②conda安装。
源码安装的话,找不到openssh文件,看了网上的解决方法,我实在太懒了,没走通,于是换了conda安装,点这里。
conda install hcc::aspera-cli但也有博主用下面的命令安装,都尝试一下吧:
conda install -y -c hcc aspera-cli查看是否安装成功,有输出表明安装成功了。
ascp -h查看aspera被conda安转在哪个地方:
which ascp
/home/qfchen/Software/anaconda3/envs/MyEnv/bin/ascp然后找到 asperaweb_id_dsa.openssh 所在的路径,例如我的是在 /home/qfchen/Software/anaconda3/envs/MyEnv/etc/ 路径下
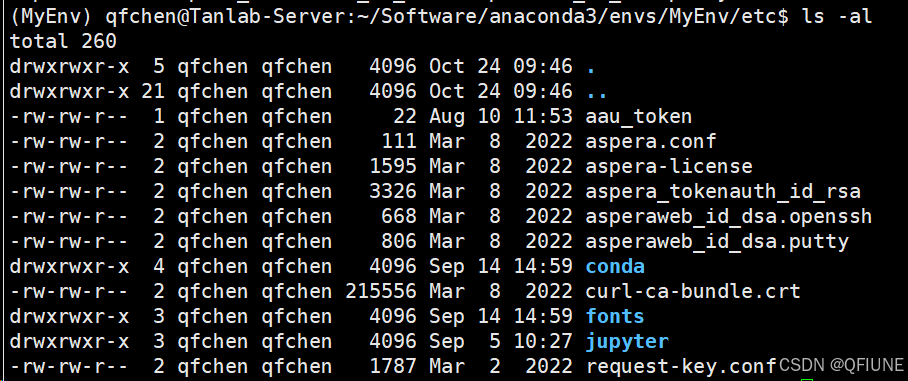
使用cd命令切换到数据保存的路径下使用下面的命令下载nr库,确保你对该文件夹具有可读可写可执行的权限,不然会报错。我的是在 /home/software/blast/database/ 路径下:
ascp -QTr -i /home/qfchen/Software/anaconda3/envs/MyEnv/etc/asperaweb_id_dsa.openssh -k1 -l 500m anonftp@ftp.ncbi.nlm.nih.gov:/blast/db/FASTA/nr.gz ./ 可以看到确实是加速了,但是还是会中断,我们只需要重新运行一下命令,然后就会从中断处重新开始下载。
可以看到确实是加速了,但是还是会中断,我们只需要重新运行一下命令,然后就会从中断处重新开始下载。
但是我还是觉得有点慢,我想直接下载到我的Windows上,然后上传到工作站,点这里 下载,nr数据库比较大,所以得准备一个硬盘,下载到硬盘里面。
下载到本地的速度还是蛮快的,四五个小时就下载完毕了 。经过我这次实验的对比:本地下载 > aspera > wget > update_blastdb.pl
等nr数据库下载完毕之后,再来研究怎么给库建索引以及使用blast。
下载完毕之后,用WinSCP工具将nr.gz上传到指定的路径:/home/software/blast/database
然后使用解压缩,注意该数据库非常之大,一定要保证内存充足。
gunzip -c nr.gz > nr解压是之后开始构建数据库索引,使用如下的命令:
/home/software/blast/bin/makeblastdb -in nr -parse_seqids -hash_index -dbtype prot
结果显示如下:
Building a new DB, current time: 10/25/2024 10:39:57
New DB name: /home/software/blast/database/nr
New DB title: nr
Sequence type: Protein
Keep MBits: T
Maximum file size: 3000000000B构建库的过程中,很漫长很漫长,耐心等待,但是很不幸的是,我的出现了 BLAST ran out of memory,这是一个悲伤的故事,想了想还是不用nr作为背景库来跑PSSM矩阵了,改用swissprot。
点这里下载swissprot,解压缩 gunzip -c swissprot.gz > swissprot,然后构建索引:
makeblastdb -in swissprot -dbtype prot -title “swissprot” -out swissprot用一个测试例子来测试一下是否成功,经测试能正常输出:
/home/software/blast/bin/psiblast -query /home/qfchen/ProteinDrugInter/datasets/DrugBank/DrugBank/fasta/O00141.fasta -db /home/software/blast/database/swissprot -evalue 0.001 -num_iterations 3 -out_ascii_pssm /home/qfchen/test.pssm

图中所示的就是一个具体的蛋白质序列生成的PSSM矩阵,通常来说我们只关注前二十列中的内容,后面的内容不做过多关注。前二十列的内容是一个L*20维的矩阵,L代表着蛋白质序列的长度(图中红色部分),20代表着20中氨基酸(图中蓝色部分)。
三、批量运行PSSM矩阵
import os
import subprocess
class PsiBlast():
def runBlast(self, fastapath, output_dir):
names = [name for name in os.listdir(fastapath) if os.path.isfile(os.path.join(fastapath + '//', name))]
tool_path = '/home/software/blast/bin/psiblast'
db_path = '/home/software/blast/database/swissprot'
evalue = 0.001
num_iterations = 3
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for each_item in names:
pdb_id = each_item.split('.')[0]
postfix = each_item.split('.')[1]
if postfix == 'fasta':
output_file = os.path.join(output_dir, pdb_id + '.pssm')
fasta_file = fastapath + '/' + each_item
# cmd = f'{tool_path} -query {fasta_file} -db {db_path} -evalue 0.001 -num_iterations 3 -out_ascii_pssm {output_file}'
# print(cmd)
# os.system(cmd)
command = [
tool_path,
'-query', fasta_file,
'-db', db_path,
'-evalue', str(evalue),
'-num_iterations', str(num_iterations),
'-out_ascii_pssm', output_file
]
try:
subprocess.run(command, check=True)
print(f'Successfully ran psiblast for {fasta_file}')
except subprocess.CalledProcessError as e:
print(f'Failed to run psiblast for {fasta_file}: {e}')
if __name__ == '__main__':
fastapath = '/home/qfchen/ProteinDrugInter/datasets/SNAP/fasta'
outpath = '/home/qfchen/ProteinDrugInter/datasets/SNAP/PSSM'
pb = PsiBlast()
pb.runBlast(fastapath, outpath)
四、解析PSSM矩阵
等我运行完事之后再来补充!!!!我来补充了!!!!
#!/usr/bin/env python
# Author : KerryChen
# File : parse_pssm.py
# Time : 2024/10/25 16:08
import os
import pandas as pd
pssmdir = '/home/qfchen/ProteinDrugInter/datasets/DrugBank/PSSM/'
savedir = '/home/qfchen/ProteinDrugInter/datasets/DrugBank/PSSM_Info/'
listfile = os.listdir(pssmdir)
for eachfile in listfile:
file_name = eachfile.split('.')[0]
pssm_file = pssmdir + '/' + eachfile
pssm = open(pssm_file)
filelines = pssm.readlines()
idxs = []
all_res = []
headers = ["A", "R", "N", "D", "C", "Q", "E", "G", "H", "I", "L", "K", "M", "F", "P", "S", "T", "W", "Y", "V"]
for pssm_line in filelines:
line_item = pssm_line.split()
if len(line_item) == 44:
idxs.append(line_item[1])
each_item = [float(item) for item in pssm_line.split()[2:22]]
all_res.append(each_item)
# 创建一个DataFrame
df = pd.DataFrame(all_res, index=idxs, columns=headers)
# 保存为CSV文件
csv_file_name = f"{file_name}.csv"
df.to_csv(savedir + csv_file_name)
print(f"{csv_file_name} 文件已生成!")
















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









