






参考
- LLaMA-Factory官网https://llamafactory.readthedocs.io/zh-cn/latest/#
- LLaMA-Factory+Ollama操作流程 https://zhuanlan.zhihu.com/p/991206079
微调和搭建知识库的区别
- rag需要载体(类似向量数据库,文档等)去承载知识库。
- 微调直接将功能加入到模型当中。
- 针对场景而定,结合知识库比较灵活,节省训练的算力。微调简单粗暴,有模型即可进行推理。
部署
默认cuda安装都已经完成,网上很多教程,不在这里多说。
运行以下指令以安装 LLaMA-Factory 及其依赖:
# 获取项目
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入项目
cd LLaMA-Factory
# 创建环境
conda create -n llama_factory python=3.10
# 激活环境
conda activate llama_factory
# 安装依赖
pip install -e ".[torch,metrics]"
完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功。
如果能成功看到类似 “Welcome to LLaMA Factory, version ······” 的字样,说明安装成功。

启动
进入webui
llamafactory-cli webui
打开链接即可看到训练平台。

使用训练平台
WebUI 主要分为四个界面:训练、评估与预测、对话、导出。
1.训练
需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
比如说,我选择的就是Baichuan-7B-Base的中文对话模型,数据集也选择的是alpaca的中文数据集。
随后,可以点击 开始 按钮开始训练模型。
注!!!若使用CPU训练可能会报Warning,如果本身就用cpu,忽略即可,如果要用gpu,应该是torch没下载配套cuda,重新安装torch即可解决问题
# 卸载 重新下载
pip uninstall torch
pip install torch
# python执行
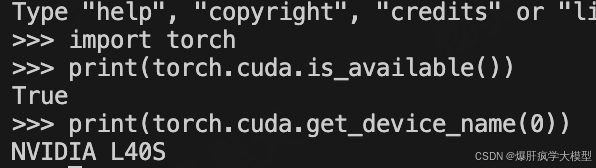
import torch
# 是否有gpu
print(torch.cuda.is_available())
# gpu型号
print(torch.cuda.get_device_name(0))

2.评估预测与对话
模型训练完毕后,通过在评估与预测界面通过指定 模型 及 适配器 的路径在指定数据集上进行评估。
也可以通过在对话界面指定 模型、 适配器 及 推理引擎 后输入对话内容与模型进行对话观察效果。
3.导出
在导出界面通过指定 模型、 适配器、 分块大小、 导出量化等级及校准数据集、 导出设备、 导出目录 等参数后,点击 导出 按钮导出模型。
(如果需要部署到Ollama上,请一定记得把模型导出)
示例:微调中文对话大模型
使用alpaca_zh_demo数据集微调Llama-3-8B-Chinese-Chat模型
训练过程的Loss曲线如下:
导出模型:

4.利用自己的数据进行微调
添加数据集信息
路径地址:/root/scratch/LLaMA-Factory/data

在dataset_info.json中加入自己的数据集名称和位置。custom_data为数据集的名称,test.json为位置,位置路径默认为在/root/scratch/LLaMA-Factory/data/test.json这个位置。
weiui同步可以显示名称

添加自己的数据
/root/scratch/LLaMA-Factory/data/test.json在这里添加数据
模型转换
模型导出
llama_factory中导出,比如导出文件夹地址为/root/scratch/LLaMA-Factory/saves/test
转换工具安装
git地址:https://github.com/ggml-org/llama.cpp
cd /root/scratch/LLaMA-Factory
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
python convert_hf_to_gguf.py /root/scratch/LLaMA-Factory/saves/test \
--outfile /root/scratch/LLaMA-Factory/saves/output-100.gguf --outtype q8_0
注!!地址一定要选择导出的地址
导入ollama
- 创建Modelfile.txt
空的就可以 地址在/root/scratch/LLaMA-Factory/saves/test_ollama/Modelfile.txt - 文件中写入转换后的gguf地址
FROM /root/scratch/LLaMA-Factory/saves/output-100.gguf - 导入
ollama create model_name -f /root/scratch/LLaMA-Factory/saves/test_ollama/Modelfile.txt
模型转向量
作用:
如果服务器没有可以使用大模型的条件,可以用这个方法转换为向量,利用向量作分类算法或者存储的向量数据库中做查重,能够利用到大模型的一点功能。
# 查看拥有的模型
ollama list
# 返回
NAME ID SIZE MODIFIED
deepseek-r1:14b ea35dfe18182 9.0 GB 5 days ago
model_name:latest 4060b56febd6 1.6 GB 2 minutes ago
# 激活环境
conda activate llama_factory
# 安装包
pip install langchain_ollama
# 执行脚本
from langchain_ollama import OllamaEmbeddings
# 使用 Ollama Embeddings 模型
embeddings = OllamaEmbeddings(model="deepseek-r1:14b")
# 嵌入查询文本
result = embeddings.embed_query("My query to look up")
print(result)
后续工作
可以参考openwebui与ollama的结合

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









