






理论介绍
广义的随机森林(Causal Tree):广义随机森林算法随机森林是一种通过集成学习思想将多棵树集成在一起的算法,其基本单元是决策树。随机森林是广义的随机森林的特例(经典的随机森林只能去估计label Y,不能用于估计复杂的目标)。
ATE(Average Treatment Effect)指标是一种用于衡量处理效应大小的统计指标
因果关系讲解(基础掌握)
参考因果发现和因果推断,比较基础,这里不做更多解释。
置信区间
置信区间是指在统计学中,由样本统计量构造的总体参数的估计区间。它表示总体参数的真实值有一定概率落在该测量结果周围的程度,即给出被测量参数的测量值的可信程度。
置信区间的定义和计算方法

置信区间的应用场景
在统计分析中,置信区间主要用于描述对总体参数估计的不确定性。它可以帮助我们进行总体参数的推断和比较。例如,如果两个总体参数的置信区间不重叠,可以认为这两个总体参数有显著差异;如果置信区间包含了某个特定值,可以认为该总体参数与该特定值没有显著差异。
置信水平
置信水平是指置信区间包含总体参数真实值的概率,通常取值为95%或99%。例如,95%的置信水平意味着在长期重复抽样中,大约有95%的置信区间会包含总体参数的真实值。
Causal Tress
随机森林算法与因果推断相结合的同时,给出了估计量的渐进分布和构造置信区间的方法。
-
通俗理解构建一颗Causal Tree的过程:首先将训练集划分为tr和est两部分,用tr来训练生成一颗决策树,训练的目标函数同时考虑了实验效应(最大)和方差(最小)。然后用est来估计CATE作为该叶子结点的CATE,对于新样本将会用该CATE作为预测值。笔者认为Causal Tree和PSM本质上是一样的,都是要找到与实验组人群的替身然后计算ATT,只不过Causal Tree是用建树的方式而PSM是计算样本之间的相似性。
其中,CATE 是在处理效果在不同子群体中不同的情况下的常见指标。 -
方法
2.1 节点切割方法(详解相关论文讲解)
Honest approach,传统决策树使用全部训练集样本来生成树,而Causal Tree先将样本集划分为tr(train)和est(honest)两部分,其中tr用来划分叶子结点,生成训练模型,est用来计算每个叶子节点的CATE。
2.2 评价指标(目标函数)
Causal Tree针对MSE进行了两点改动:
(1)修改了MSE的表达式,更聚焦于Treatment Effect
(2)修改了均方误差的计算方法,split出test set 和 estimate set分别进行Partitioning和Estimate Effect 两个任务(honest approach)
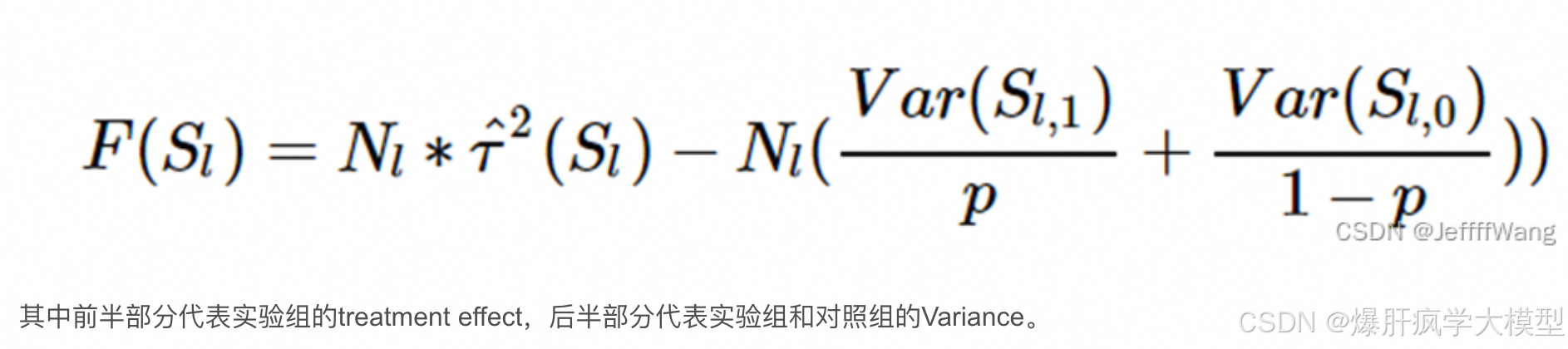
Treatment effect之所以比通常的预测问题要更难解决,因为Groud-truth在现实中是无法直接观测到的,一个人在同一时刻要么吃药要不么吃药,没有平行宇宙让我们去从上帝视角观察吃药与否带来的变化。因为个体的treatment effect无法估计,只能去估计群体的treatment effect- ATE (Average treatment effect),当出现个体效果差异时ATE无法反应局部效果,估计相似群体的treatment effect-CATE(Conditional average treatment effect)[详见因果关系讲解]
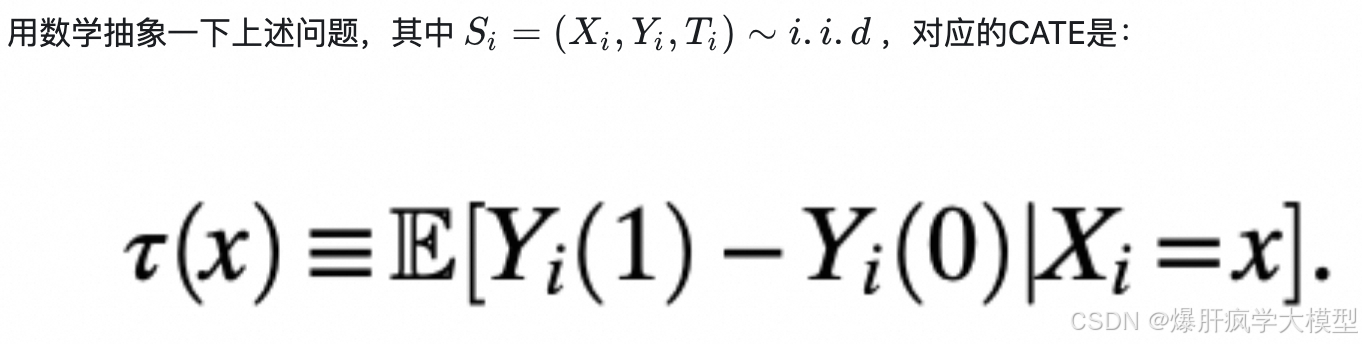
其中Y表示outcome,X表示feature,T表示Treatment -
整体方法介绍
参考基于树模型的异质因果效应估计
相关理论推导篇
环境[动手实验]
# 创建环境
# conda create --name causalforest python=3.8
# 激活环境
conda activate causalforest
# 前往地址
# /root/test_yang/CausalForest
/root/test_yang/CausalForest/test/causalforest2.py


















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









