






1.安装labelme
打开conda prompt 输入以下代码创建虚拟环境,打开虚拟环境,安装lelme。
conda create -n labelme python=3.6 //创建虚拟环境
conda activate labelme //打开虚拟环境
pip install labelme //安装labelme
2.标注数据
安装labelme后再环境下输入labelme,回车打开labelme如图
选择opendir打开要标注文件所在的文件夹,开始进行标注。在图片区域点击右键,如下图,如果是目标检测的话就点击Create Rectangle标注目标所在的目标框,若果是分割的话就点击Create Polygons。标注完成以后加上标签,别忘了保存。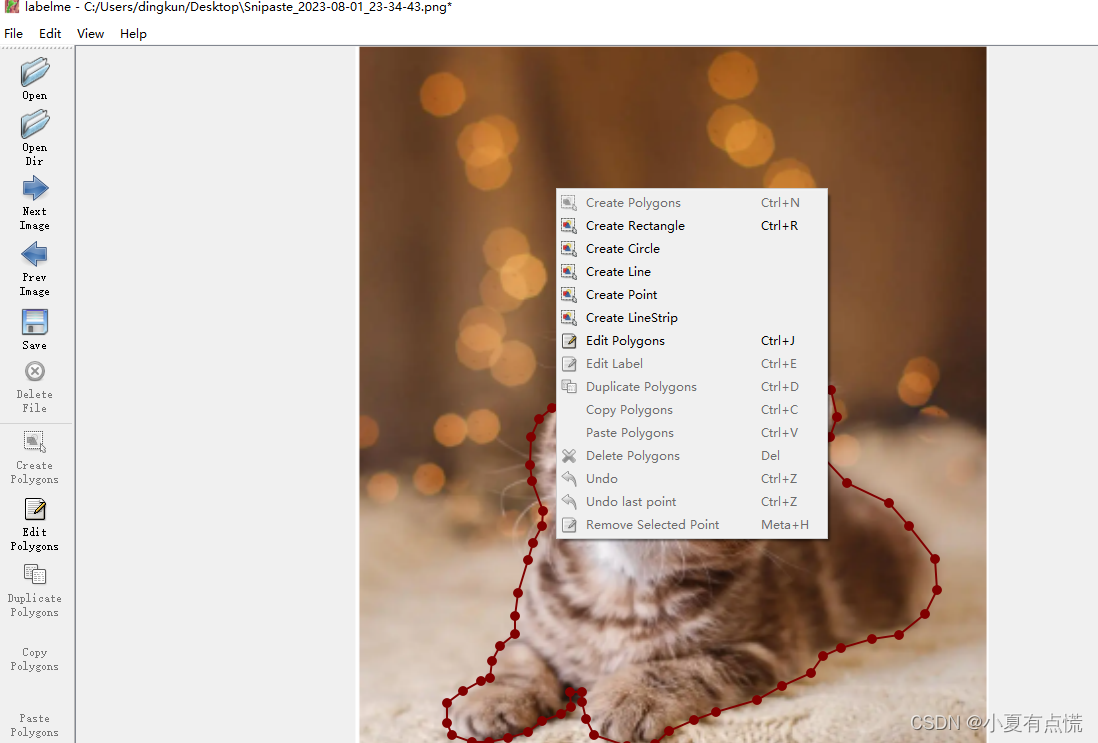
3.数据转换
在进行目标训练的时候经常要把标注的结果转化为需要的yolo格式,下面贴出数据集转yolo的代码。
## python 数据集转yolo代码
import json
import os
import cv2
file_dir = "E:/BaiduNetdiskDownload/all_images/all_images/"
files = [i for i in os.listdir(file_dir)]
label_list = []
for file in files:
if not os.path.basename(file).endswith(".json"):
continue
file_path = os.path.join(file_dir, os.path.basename(file))
image_path = file_path.replace(".json", ".bmp")
print(image_path)
image = cv2.imread(image_path)
W = image.shape[1]
H = image.shape[0]
with open(file_path, "rb") as rf:
file_in = json.load(rf)
shapes = file_in["shapes"]
anno = ""
for shape in shapes:
if shape["label"] not in label_list:
label_list.append(shape["label"])
x1 = shape["points"][0][0]
y1 = shape["points"][0][1]
x2 = shape["points"][1][0]
y2 = shape["points"][1][1]
x = (x1 + x2) / 2 / W
y = (y1 + y2) / 2 / H
w = (x2 - x1) / W
h = (y2 - y1) / H
anno += str(label_list.index(shape["label"])) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + "\n"
new_path = os.path.join(file_dir, os.path.basename(file).replace(".json", ".txt"))
with open(new_path, "wb") as wf:
wf.write(anno.encode())
## python 数据集 转yolo-face的代码
import json
import os
import cv2
file_dir = "E:/BaiduNetdiskDownload/yolo-face/new_dataset/images"
files = [i for i in os.listdir(file_dir)]
label_list = []
for file in files:
if not os.path.basename(file).endswith(".json"):
continue
file_path = os.path.join(file_dir, os.path.basename(file))
image_path = file_path.replace(".json", ".bmp")
print(image_path)
# image = cv2.imread(image_path)
# W = image.shape[1]
# H = image.shape[0]
with open(file_path, "rb") as rf:
file_in = json.load(rf)
shapes = file_in["shapes"]
W = file_in["imageWidth"]
H = file_in["imageHeight"]
anno = ""
for shape in shapes:
if shape["label"] == "target":
x1 = shape["points"][0][0]
y1 = shape["points"][0][1]
x2 = shape["points"][1][0]
y2 = shape["points"][1][1]
x = (x1 + x2) / 2 / W
y = (y1 + y2) / 2 / H
w = (x2 - x1) / W
h = (y2 - y1) / H
if shape["label"] == "circle_point":
x3 = shape["points"][0][0] / W
y3 = shape["points"][0][1] / H
x4 = shape["points"][1][0] / W
y4 = shape["points"][1][1] / H
x5 = (x3 + x4) / 2
y5 = (y3 + y4) / 2
p1 = (x3, y5) # left
p2 = (x5, y3) # top
p3 = (x4, y5) # right
p4 = (x5, y4) # bottom
p5 = (x5, y5) # center
print(x1)
anno = "0" + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + " " + str(x3) + " " + str(y5) + " " + str(x5) + " " + str(y3) + " " + str(x4) + " " + str(y5) + " " + str(x5) + " " + str(y4) + " " + str(x5) + " " + str(y5) + "\n"
new_path = os.path.join(file_dir, os.path.basename(file).replace(".json", ".txt"))
with open(new_path, "wb") as wf:
wf.write(anno.encode())下面语义分割数据集转化
# 1.单张图片的转化
# cd 到标注的文件夹执行以下命令
labelme_json_to_dataset x.json -o x
# x.json 要转化的数据
# x 要输出的目录文件夹多张图片的转化如下:
首先准备好自己的txt文件,文件中设置好自己的标签。
__ignore__
_background_
human
bike
bottle//执行以下代码
python labelme2voc.py input_dir output_dir --lables labels.txt
iput_dir 标注文件所在文件夹
output_dir 输出结果的文件夹
labels.txt 指定标签文件的文件名,可更改下面是lableme2voc.py代码,不方便下载的可以自己从下面拷贝代码,也可以自己下载源文件。
#label_to_voc文件内容
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
os.makedirs(osp.join(args.output_dir, "SegmentationObject"))
os.makedirs(osp.join(args.output_dir, "SegmentationObjectPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationObjectVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_cls_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_clsp_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_clsv_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
out_ins_file = osp.join(
args.output_dir, "SegmentationObject", base + ".npy"
)
out_insp_file = osp.join(
args.output_dir, "SegmentationObjectPNG", base + ".png"
)
if not args.noviz:
out_insv_file = osp.join(
args.output_dir,
"SegmentationObjectVisualization",
base + ".jpg",
)
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
cls, ins = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
ins[cls == -1] = 0 # ignore it.
# class label
labelme.utils.lblsave(out_clsp_file, cls)
np.save(out_cls_file, cls)
if not args.noviz:
clsv = imgviz.label2rgb(
cls,
imgviz.rgb2gray(img),
label_names=class_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_clsv_file, clsv)
# instance label
labelme.utils.lblsave(out_insp_file, ins)
np.save(out_ins_file, ins)
if not args.noviz:
instance_ids = np.unique(ins)
instance_names = [str(i) for i in range(max(instance_ids) + 1)]
insv = imgviz.label2rgb(
ins,
imgviz.rgb2gray(img),
label_names=instance_names,
font_size=15,
loc="rb",
)
imgviz.io.imsave(out_insv_file, insv)
if __name__ == "__main__":
main()下面是voc2coco代码:
#!/usr/bin/env python
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "Visualization"))
print("Creating dataset:", args.output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[
dict(
url=None,
id=0,
name=None,
)
],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
if class_id == -1:
assert class_name == "__ignore__"
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(
supercategory=None,
id=class_id,
name=class_name,
)
)
out_ann_file = osp.join(args.output_dir, "annotations.json")
label_files = glob.glob(osp.join(args.input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
data["images"].append(
dict(
license=0,
url=None,
file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not args.noviz:
viz = img
if masks:
labels, captions, masks = zip(
*[
(class_name_to_id[cnm], cnm, msk)
for (cnm, gid), msk in masks.items()
if cnm in class_name_to_id
]
)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
args.output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
if __name__ == "__main__":
main()
















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









