






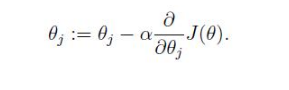
目的:降低损失函数y
可调整数值:变量x(式子中时θ)
当求得导数为正数时,代表x增大,y也增大,根据目的,需要减小x,这样y也会减小,所以取导数反方向,即更新为负号。
当求得导数为负数时,代表x增大,y减小,与目的相同,如何增大x呢,也需要取导数反方向,即
x-导数,这样x就增大了,y也就减小了。
综合两种情况,可以看出取取导数的反方向更新x,会使得y损失函数减小。
参数更新方向确定了,如何更新的更好呢,有一个学习率控制,还有没有更好的方法呢,得琢磨琢磨。


















12-30
 740
740
740
03-20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









