







1、摘要
作者提出了新的自顶向下的多人姿态估计方法。首先使用 F a s t e r R C N N Faster~RCNN Faster RCNN 预测可能包含人体目标的边界框的位置和大小。然后估计每个提议边界框可能包含的关键点。使用全卷积 R e s N e t ResNet ResNet 预测每个关键点的密度热图和偏移量。为了合并输出,作者引入了一种新的聚合过程来获得高度定位的关键点预测。作者还使用了一种新形式的基于关键点的非最大值抑制,而不是更粗糙的框级非最大抑制,以及一种新形式的基于关键点的置信度得分估计,而不是框级得分。
2、方法
如图 1 1 1 所示为算法处理过程。
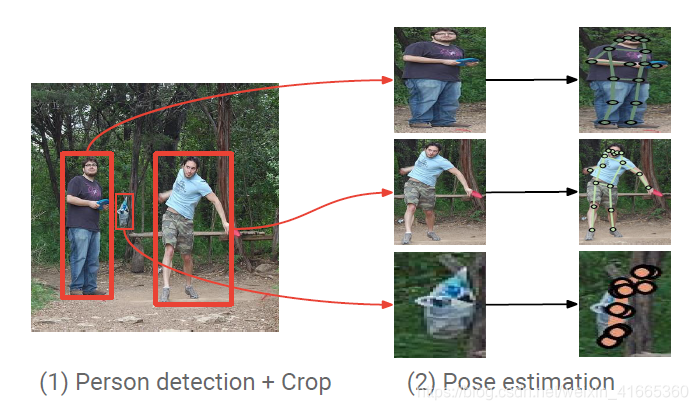
图 1 1 1 首先使用 F a s t e r R C N N Faster~RCNN Faster RCNN 检测人体目标,然后裁剪相应目标图像块,使用姿态估计器定位关键点,并且对相应提议重新打分。
2.1、人体检测
使用空洞卷积替代的 R e s N e t − 101 ResNet-101 ResNet−101 作为 F a s t e r R C N N Faster~RCNN Faster RCNN 检测器网络主骨,输出步长等于 8 8 8 像素。
2.2、姿态估计
姿态估计器在给定人体边界框的基础上预测 17 17 17 个人体关键点。对于每个空间位置,首先分类它是否在每个关键点附近(称之为“热图”),然后预测二维局部偏移向量,以获得相应关键点位置的更精确估计。
如图 2 2 2 所示,每个关键点对应 3 3 3 个输出通道。

图 2 2 2:网络目标输出。左和中:左肘关键点热图目标。右:偏移场 L 2 L2 L2 幅度(以灰度显示)和二维偏移向量以红色显示。
图像裁剪:首先通过扩展人体检测器返回的盒子的高度或宽度,使所有盒子具有相同的固定纵横比,而不扭曲图像纵横比。然后进一步扩大框来包含图像上下文:评估时缩放因子等于 1.25 1.25 1.25,训练时,缩放因子在 1.0 1.0 1.0 到 1.5 1.5 1.5 之间。之后将图像高度调整为 353 353 353,图像宽度调整为 257 257 257。纵横比为 353 / 257 = 1.37 353/257=1.37 353/257=1.37。
热图和偏移预测:使用全卷积的 R e s N e t − 101 ResNet-101 ResNet−101 产生热图(每个关键点一个通道)和偏移(每个关键点两个通道, x x x 和 y y y),一共 3 K 3K 3K 个通道, K = 17 K=17 K=17 为关键点数量。使用空洞卷积产生 3 K 3K 3K 个预测,输出步长为 8 8 8 像素,并使用双线性插值上采样至 353 × 257 353\times257 353×257。
若第 k k k 个关键点定位于 x i x_i xi, f k ( x i ) = 1 f_{k}\left(x_{i}\right)=1 f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









