









近年来,自从 2017 年 Google 提出的论文《Attention Is All You Need》发布以来,Transformer 模型迅速成为自然语言处理(NLP)领域的主流模型。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer 模型依靠注意力机制实现了并行化处理,能够有效捕捉长距离依赖关系,并在多个任务上取得了出色的性能。本文将详细讲解 Transformer 模型的设计思想、各模块实现原理、代码实现细节以及优化方法,希望能帮助读者深入理解 Transformer 模型的内部机制。
1. Transformer 模型背景
在深度学习的早期,RNN 及其变种 LSTM、GRU 一直是处理序列数据的主要模型。然而,由于序列数据的并行计算受限以及梯度消失、梯度爆炸等问题,RNN 在长序列建模上存在不少局限性。CNN 在捕获局部特征方面效果较好,但在全局依赖建模上又有所不足。
Transformer 模型正是在这种背景下应运而生。Transformer 模型摒弃了传统的循环结构,完全依赖注意力机制来捕捉序列中各位置之间的依赖关系。这种基于注意力的架构具有以下优点:
• 并行化计算:所有单词的表示可以同时计算,大大提高训练速度。
• 捕捉长距离依赖:通过注意力机制,模型能够直接关注序列中任意两个位置的信息。
• 结构简单:相对于 RNN,Transformer 模型的结构更简单,易于扩展和修改。
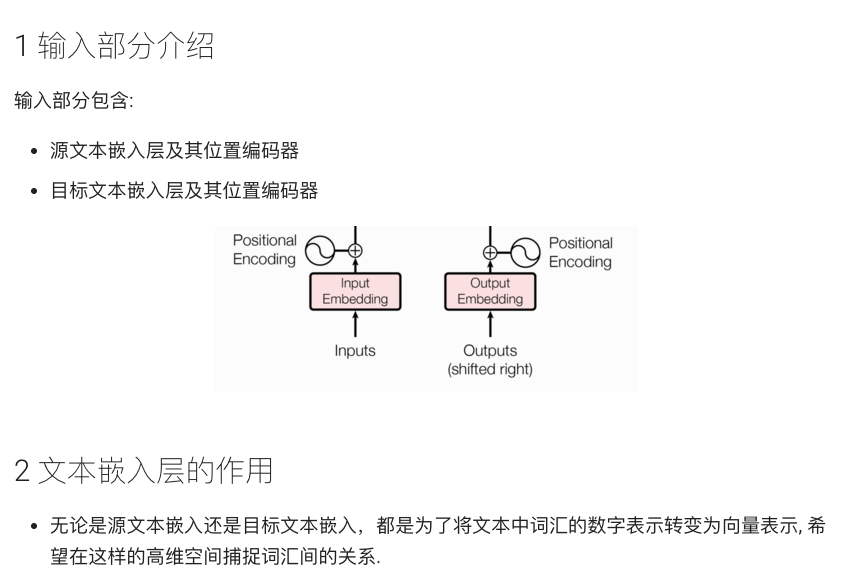
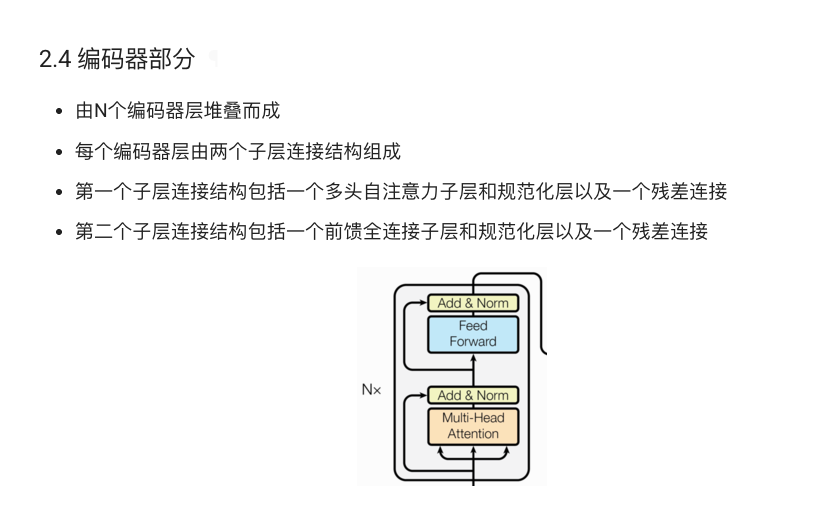
2. Transformer 模型架构概述
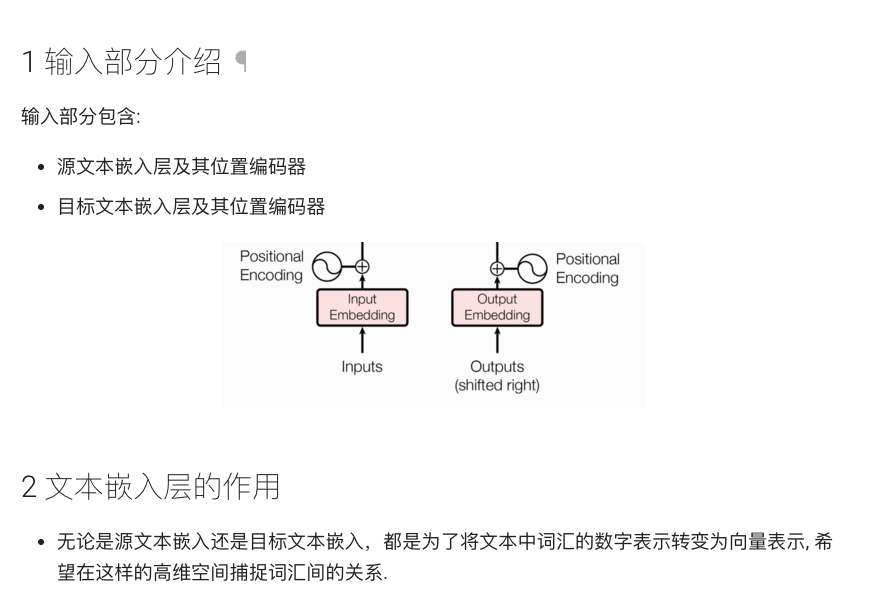
Transformer 模型由编码器(Encoder)和解码器(Decoder)两部分组成。整个模型的输入是一个源语言序列,输出是一个目标语言序列。
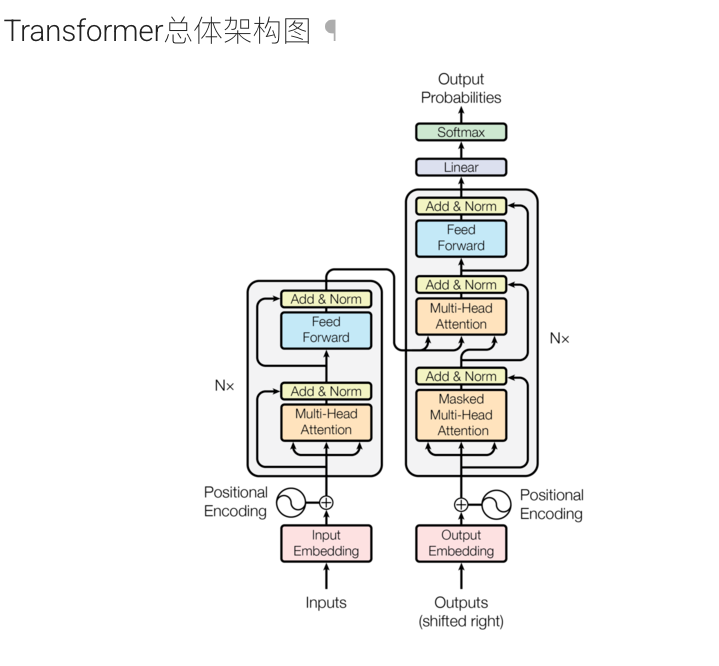
其基本结构图如下:
输入嵌入 + 位置编码
│
┌────Encoder────┐
│ 层叠 N 次 │
└──────┬──────┘
│ memory
▼
┌───Decoder───┬────────┐
│ 层叠 N 次 │ 输出层 Generator
└────────────┴────────┘
│
▼
输出对数概率分布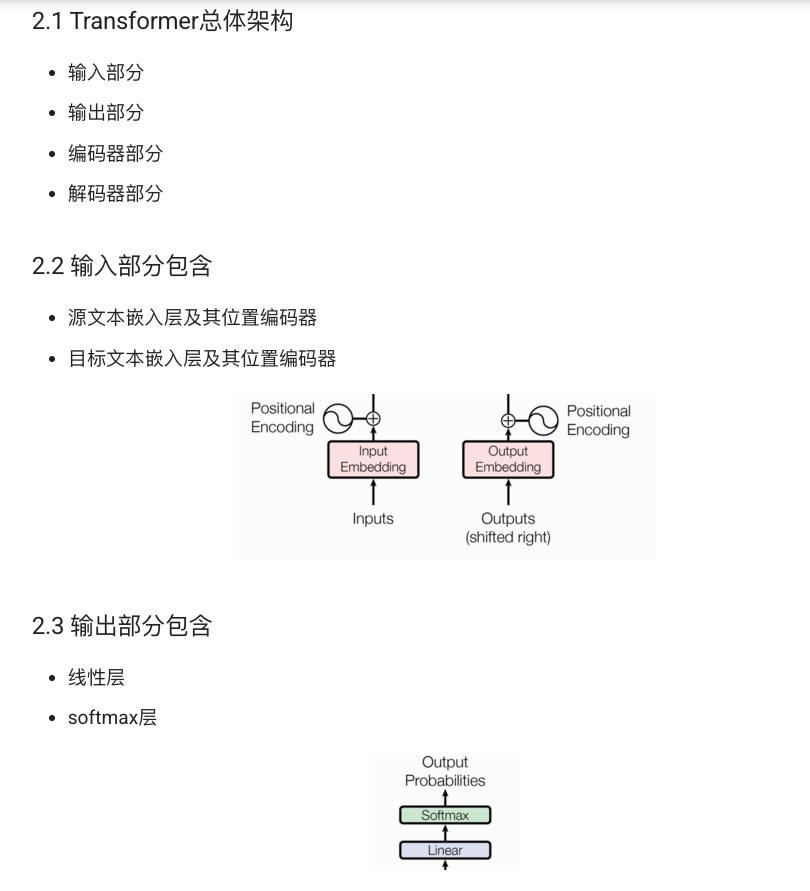


编码器主要由若干个 EncoderLayer 组成,每一层由两部分构成:多头自注意力层(Multi-Head Self-Attention)和前馈全连接层(Feed-Forward Network),两部分之间采用残差连接(Residual Connection)和层归一化(Layer Normalization)。
解码器的结构与编码器类似,但增加了编码器-解码器注意力层(Encoder-Decoder Attention),用于在生成过程中结合编码器输出的上下文信息,同时使用下三角掩码(subsequent mask)防止模型在解码时利用未来信息。
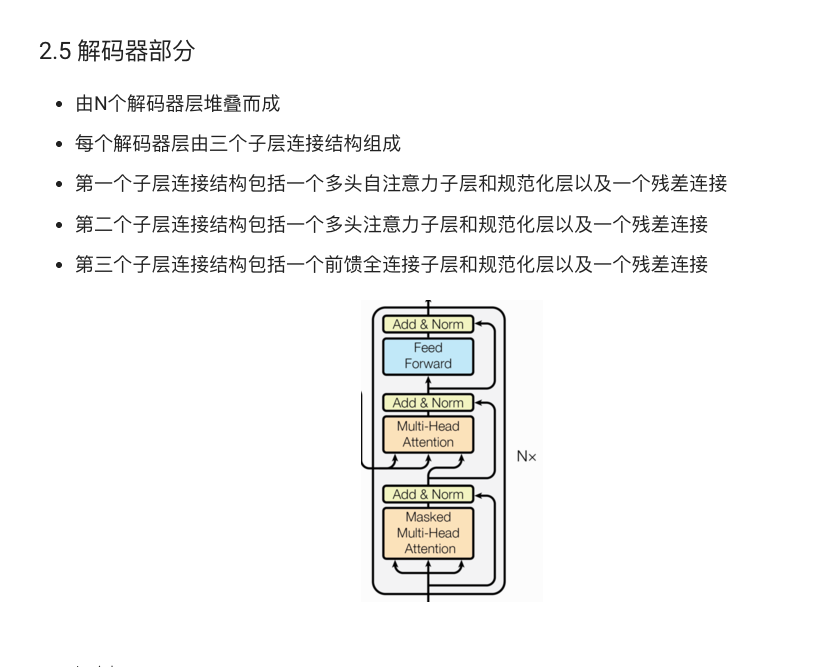
3. Transformer 模型的核心技术
3.1 注意力机制
注意力机制(Attention Mechanism)是 Transformer 模型的核心。简单来说,注意力机制允许模型在计算每个位置的表示时,根据所有位置的输入数据给予不同的权重。数学上,对于查询(Query)、键(Key)和值(Value),注意力计算公式为:


3.1.1 Scaled Dot-Product Attention

3.1.2 掩码机制


在实际任务中,注意力机制往往需要使用掩码来屏蔽掉某些不需要的信息。例如:
• 填充掩码(Padding Mask):当输入序列中存在填充(padding)时,模型需要忽略这些填充值对注意力计算的影响。
• 后续掩码(Subsequent Mask 或 Look-Ahead Mask):在解码器中,为防止模型在生成当前词时利用未来词的信息,需要对注意力分布进行屏蔽,使得每个位置只能看到当前位置及之前的部分。
我们可以使用如下函数自动生成这两类掩码:
def subsequent_mask(size: int) -> torch.Tensor:
"""
生成下三角掩码,用于解码器的目标序列,确保每个位置只能关注当前及之前的词(防止信息泄露)。
返回的掩码形状为 [1, size, size],其中 True 表示允许访问,False 表示屏蔽。
"""
subsequent_mask = torch.triu(torch.ones(1, size, size, dtype=torch.uint8), diagonal=1)
return subsequent_mask == 0
def create_pad_mask(seq: torch.Tensor, pad_token: int = 0) -> torch.Tensor:
"""
生成填充掩码,用于屏蔽输入序列中 pad 的位置。
:param seq: 输入的词索引张量,形状为 [batch_size, seq_len]
:param pad_token: 表示 pad 的 token 值,默认是0
:return: 掩码张量,形状为 [batch_size, 1, seq_len],其中 True 表示非pad位置
"""
return (seq != pad_token).unsqueeze(1)这两个函数分别用于生成后续掩码和填充掩码,最终可将二者进行逻辑与运算,生成最终目标序列的掩码。
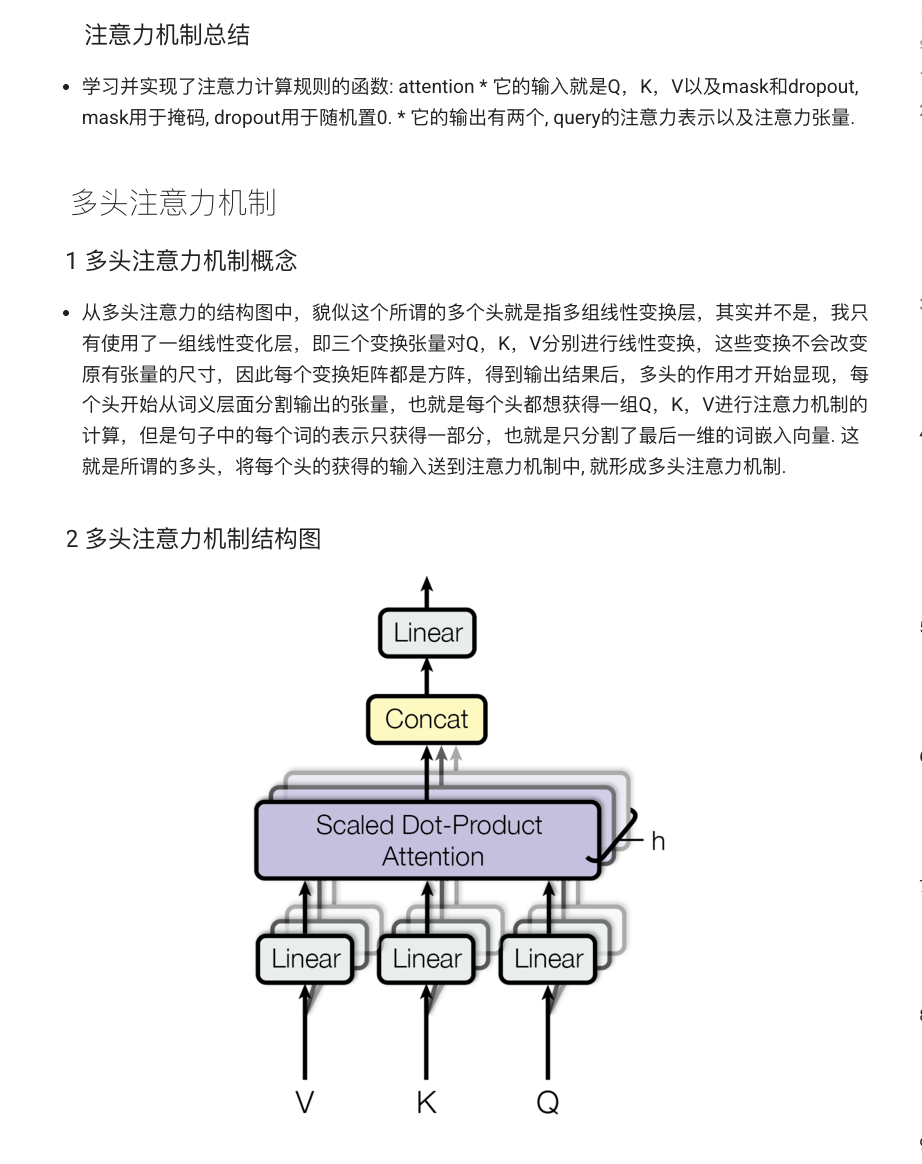
3.2 多头注意力

单头注意力虽然有效,但在实际应用中,不同的注意力头能够捕获输入数据的不同特征。多头注意力机制通过将输入向量分成多个子空间,在每个子空间上独立计算注意力,然后将各个头的结果拼接起来,经过线性变换得到最终输出。
其计算过程可以描述为:

3.3 前馈全连接层

在 Transformer 中,每个编码器层和解码器层都包含一个前馈全连接层。该层由两个线性层构成,中间通过 ReLU 激活和 dropout 进行非线性转换。
其作用在于为模型提供更强的表达能力,使得单层的注意力机制能够捕捉复杂的模式。
公式如下:
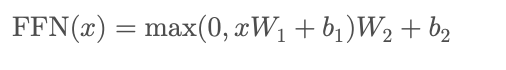
3.4 层归一化与残差连接

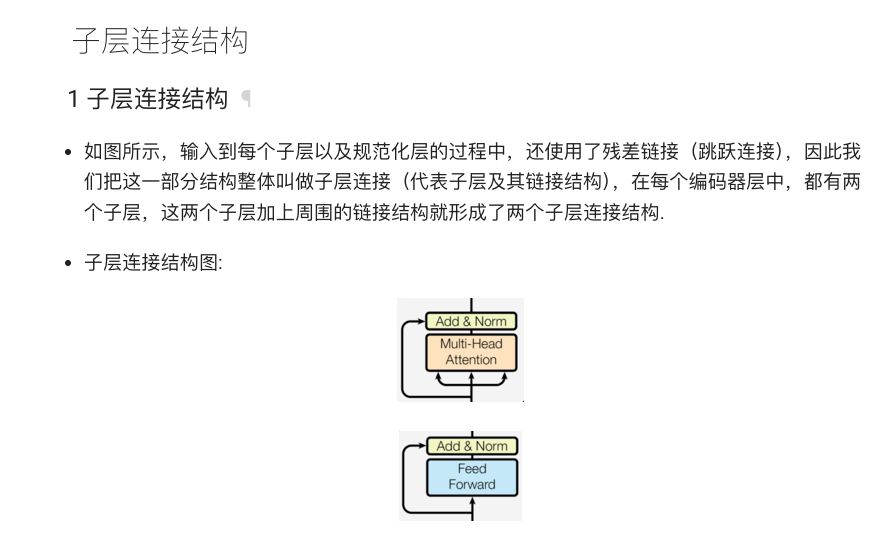
在 Transformer 模型中,每个子层(如注意力层、前馈网络)都包裹着残差连接(Residual Connection)和层归一化(LayerNorm)。
这种设计可以使得梯度传递更加顺畅,缓解深层网络中的梯度消失问题,同时有助于模型快速收敛。
残差连接的实现方式为:

这种设计将原始输入与子层的输出相加,起到“跳跃连接”的作用。
4. Transformer 模型的代码实现
下面给出一个基于 PyTorch 的 Transformer 模型的完整实现,包括词嵌入、位置编码、多头注意力、前馈全连接层、层归一化、编码器和解码器层、以及整体 EncoderDecoder 模块。代码实现遵循官方论文《Attention Is All You Need》的设计思想。
import copy, math
import torch
import torch.nn as nn
import torch.nn.functional as F
# -------------------------------
# 辅助函数:深度复制模块
def clones(module: nn.Module, N: int) -> nn.ModuleList:
"""返回包含 N 个深拷贝模块的 ModuleList"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
# -------------------------------
# 词嵌入层
class Embeddings(nn.Module):
def __init__(self, d_model: int, vocab: int):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 将词索引映射到向量,并乘以 sqrt(d_model) 来缩放
return self.lut(x) * math.sqrt(self.d_model)
# -------------------------------
# 位置编码器
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# 创建一个 [max_len, d_model] 的位置编码矩阵
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
# 每个维度对应一个不同频率的正弦和余弦函数
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x: [batch_size, seq_len, d_model]
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
# -------------------------------
# 注意力函数(Scaled Dot-Product Attention)
def attention(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor,
mask: torch.Tensor = None, dropout: nn.Dropout = None) -> (torch.Tensor, torch.Tensor):
d_k = query.size(-1)
# 计算 QK^T 并缩放
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# mask 期望形状为 [batch_size, 1, seq_len, seq_len] 或可广播至该形状
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
# -------------------------------
# 多头注意力层
class MultiHeadedAttention(nn.Module):
def __init__(self, head: int, embedding_dim: int, dropout: float = 0.1):
super(MultiHeadedAttention, self).__init__()
assert embedding_dim % head == 0, "embedding_dim 必须能被 head 整除"
self.d_k = embedding_dim // head
self.head = head
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor,
mask: torch.Tensor = None) -> torch.Tensor:
batch_size = query.size(0)
# 对输入分别做线性变换,再将维度重排为 [batch_size, head, seq_len, d_k]
query, key, value = [
lin(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 调用注意力函数;注意:mask 需要形状为 [batch_size, 1, seq_len, seq_len],
# 如果传入的 mask 形状不对,可以在外部提前调整。
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 将输出重排为 [batch_size, seq_len, embedding_dim]
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)
return self.linears[-1](x)
# -------------------------------
# 前馈全连接层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
super(PositionwiseFeedForward, self).__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(self.dropout(F.relu(self.w1(x))))
# -------------------------------
# 层归一化
class LayerNorm(nn.Module):
def __init__(self, features: int, eps: float = 1e-6):
super(LayerNorm, self).__init__()
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a2 * (x - mean) / (std + self.eps) + self.b2
# -------------------------------
# 残差连接与子层连接结构
class SublayerConnection(nn.Module):
def __init__(self, size: int, dropout: float = 0.1):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, sublayer) -> torch.Tensor:
# 规范化后传入子层,最后与输入进行残差连接
return x + self.dropout(sublayer(self.norm(x)))
# -------------------------------
# 编码器层
class EncoderLayer(nn.Module):
def __init__(self, size: int, self_attn: nn.Module, feed_forward: nn.Module, dropout: float):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
x = self.sublayer[1](x, self.feed_forward)
return x
# -------------------------------
# 编码器:堆叠多个 EncoderLayer
class Encoder(nn.Module):
def __init__(self, layer: nn.Module, N: int):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# -------------------------------
# 解码器层
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, self_attn: nn.Module, src_attn: nn.Module,
feed_forward: nn.Module, dropout: float):
super(DecoderLayer, self).__init__()
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(d_model, dropout), 3)
def forward(self, x: torch.Tensor, memory: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
x = self.sublayer[2](x, self.feed_forward)
return x
# -------------------------------
# 解码器:堆叠多个 DecoderLayer
class Decoder(nn.Module):
def __init__(self, d_model: int, layer: nn.Module, N: int):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(d_model)
def forward(self, x: torch.Tensor, memory: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
# -------------------------------
# 输出生成器:将 Transformer 输出映射到词汇表上
class Generator(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super(Generator, self).__init__()
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return F.log_softmax(self.project(x), dim=-1)
# -------------------------------
# EncoderDecoder 模块:整体 Transformer 模型
class EncoderDecoder(nn.Module):
def __init__(self, encoder: nn.Module, decoder: nn.Module,
source_embed: nn.Module, target_embed: nn.Module,
generator: nn.Module):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = source_embed
self.tgt_embed = target_embed
self.generator = generator
def forward(self, source: torch.Tensor, target: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
memory = self.encode(source, source_mask)
decoded = self.decode(memory, source_mask, target, target_mask)
return self.generator(decoded)
def encode(self, source: torch.Tensor, source_mask: torch.Tensor) -> torch.Tensor:
return self.encoder(self.src_embed(source), source_mask)
def decode(self, memory: torch.Tensor, source_mask: torch.Tensor,
target: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
# -------------------------------
# 掩码辅助函数
def create_pad_mask(seq: torch.Tensor, pad_token: int = 0) -> torch.Tensor:
"""
生成填充掩码,返回形状 [batch_size, 1, 1, seq_len],后续会广播到注意力得分上
"""
return (seq != pad_token).unsqueeze(1).unsqueeze(2)
def subsequent_mask(size: int) -> torch.Tensor:
"""
生成下三角掩码,返回形状 [1, size, size],用于解码器防止利用未来信息
"""
attn_shape = (1, size, size)
subsequent_mask = torch.triu(torch.ones(attn_shape, dtype=torch.uint8), diagonal=1)
return subsequent_mask == 0
# -------------------------------
# 构建 Transformer 模型的函数
def make_model(source_vocab: int, target_vocab: int, N: int = 6,
d_model: int = 512, d_ff: int = 2048, head: int = 8,
dropout: float = 0.1) -> nn.Module:
c = copy.deepcopy
attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(d_model, DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, source_vocab), c(position)),
nn.Sequential(Embeddings(d_model, target_vocab), c(position)),
Generator(d_model, target_vocab)
)
# 参数初始化(Xavier 均匀初始化)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
# -------------------------------
# 测试 Transformer 模型
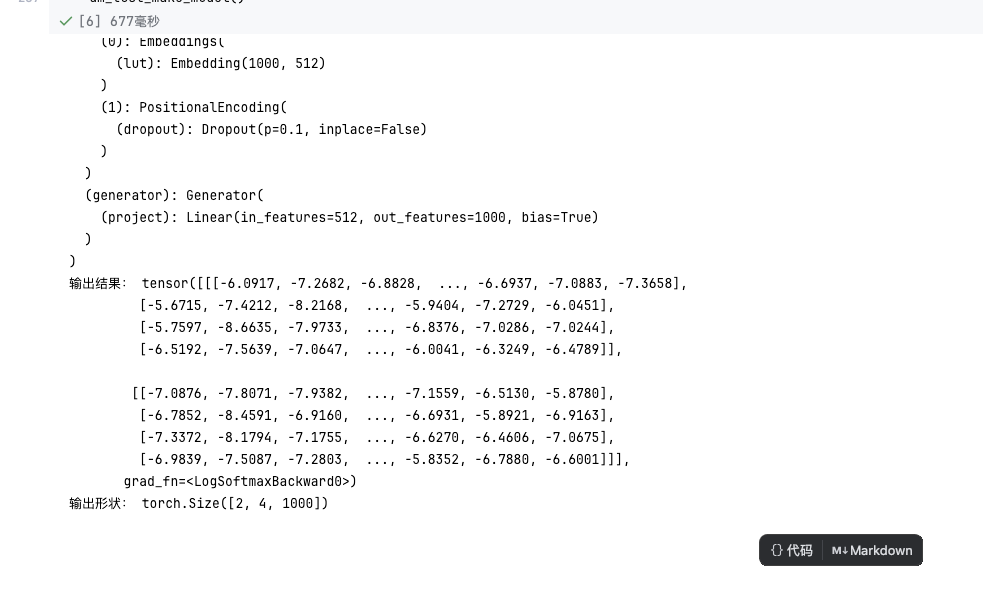
def dm_test_make_model():
source_vocab = 500
target_vocab = 1000
N = 6
model = make_model(source_vocab, target_vocab, N=N, d_model=512, d_ff=2048, head=8, dropout=0.1)
print("模型结构:\n", model)
# 构造测试输入,形状 [batch_size, seq_len]
source = torch.LongTensor([[1, 2, 3, 8], [3, 4, 1, 8]])
target = torch.LongTensor([[1, 2, 3, 8], [3, 4, 1, 8]])
# 自动生成掩码:pad 掩码(此处假设 pad token 为 0)和后续掩码(下三角 mask)
source_mask = create_pad_mask(source, pad_token=0) # [batch_size, 1, 1, src_seq_len]
# 解码器的掩码同时考虑 pad 掩码与后续 mask
tgt_pad_mask = create_pad_mask(target, pad_token=0) # [batch_size, 1, 1, tgt_seq_len]
tgt_sub_mask = subsequent_mask(target.size(1)).to(target.device) # [1, tgt_seq_len, tgt_seq_len]
# 广播后得到的 target_mask 形状为 [batch_size, 1, tgt_seq_len, tgt_seq_len],再 squeeze第一维即可用于注意力计算
target_mask = tgt_pad_mask & tgt_sub_mask.unsqueeze(1)
output = model(source, target, source_mask, target_mask)
print("输出结果:", output)
print("输出形状:", output.shape)
if __name__ == '__main__':
dm_test_make_model()输出:
代码说明
本文介绍了基于 PyTorch 实现 Transformer 模型的完整代码,包括以下主要部分:
1. 基础模块与辅助函数
• 使用 clones 函数实现深度复制。
• Embeddings 和 PositionalEncoding 实现了输入数据的嵌入和位置编码。
2. 注意力机制
• attention 函数实现了 Scaled Dot-Product Attention,并支持掩码操作。
• MultiHeadedAttention 通过多个线性层和维度重排实现多头注意力。
3. 前馈全连接层与层归一化
• PositionwiseFeedForward 由两个线性层、ReLU 和 dropout 组成。
• LayerNorm 对输入的最后一维进行归一化。
4. 残差连接与子层连接
• SublayerConnection 先对输入进行归一化,再传入子层,并加上原始输入形成残差连接。
5. 编码器与解码器
• EncoderLayer 和 DecoderLayer 分别构成编码器和解码器的基本单元,堆叠后构成完整的编码器和解码器。
• DecoderLayer 中还包含编码器-解码器注意力层。
6. 输出生成器与整体模型
• Generator 将解码器输出映射到目标词汇表上,并通过 log_softmax 得到对数概率分布。
• EncoderDecoder 模块将所有部分组合成完整的 Transformer 模型。
7. 掩码生成
• 自动生成 pad 掩码和下三角掩码,确保模型在训练和推理过程中不会利用无效信息。
8. 参数初始化
• 使用 Xavier 均匀初始化方法初始化模型参数。
这套代码实现遵循了论文《Attention Is All You Need》的设计思想,可直接用于构建 Transformer 模型,并根据具体任务进行扩展与优化。
4.1 辅助函数与基础模块
首先是一些辅助函数,例如深度复制模块(clones)以及 Embeddings、PositionalEncoding 等基础模块。

位置编码的计算公式:

import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy
def clones(module: nn.Module, N: int) -> nn.ModuleList:
"""返回包含 N 个深拷贝模块的 ModuleList"""
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Embeddings(nn.Module):
def __init__(self, d_model: int, vocab: int):
super(Embeddings, self).__init__()
self.d_model = d_model
self.lut = nn.Embedding(vocab, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.lut(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)4.2 注意力机制与多头注意力层
接下来实现注意力函数和多头注意力层。其中注意力函数计算 Scaled Dot-Product Attention,并支持掩码操作(支持填充掩码与后续掩码)。

def attention(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor,
mask: torch.Tensor = None, dropout: nn.Dropout = None) -> (torch.Tensor, torch.Tensor):
d_k = query.size()[-1]
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
# 如果 mask 的形状为 [batch_size, seq_len, seq_len],扩展到 [batch_size, 1, seq_len, seq_len]
if mask.dim() == 3:
mask = mask.unsqueeze(1)
elif mask.size(0) != query.size(0):
raise ValueError("mask 的第一维必须与 batch_size 相等")
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
x = torch.matmul(p_attn, value)
return x, p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, head: int, embedding_dim: int, dropout: float = 0.1):
super(MultiHeadedAttention, self).__init__()
assert embedding_dim % head == 0, "embedding_dim 必须能被 head 整除"
self.d_k = embedding_dim // head
self.head = head
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor,
mask: torch.Tensor = None) -> torch.Tensor:
batch_size = query.size(0)
query, key, value = [
model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for model, x in zip(self.linears, (query, key, value))
]
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k)
return self.linears[-1](x)4.3 前馈全连接层与层归一化


前馈全连接层和层归一化层在 Transformer 模型中同样扮演重要角色。前馈层增加了网络的非线性能力,而层归一化有助于稳定训练过程。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float = 0.1):
super(PositionwiseFeedForward, self).__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(self.dropout(F.relu(self.w1(x))))
class LayerNorm(nn.Module):
def __init__(self, features: int, eps: float = 1e-6):
super(LayerNorm, self).__init__()
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a2 * (x - mean) / (std + self.eps) + self.b24.4 残差连接与子层连接结构

残差连接与子层连接(Sublayer Connection)在 Transformer 中用于缓解梯度消失问题,并加快收敛速度。代码如下:
class SublayerConnection(nn.Module):
def __init__(self, size: int, dropout: float = 0.1):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, sublayer) -> torch.Tensor:
return x + self.dropout(sublayer(self.norm(x)))4.5 编码器层、编码器和解码器层


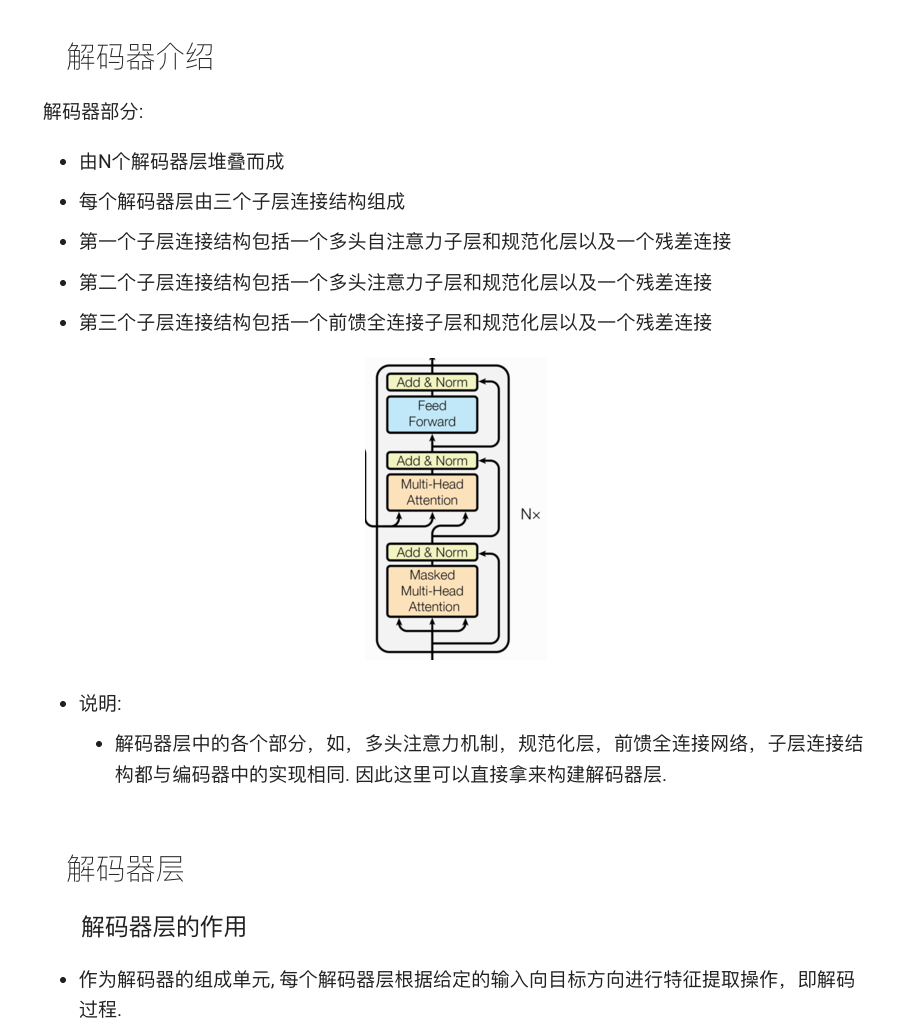

编码器层(EncoderLayer)和解码器层(DecoderLayer)是 Transformer 的基本组成单元。编码器层由自注意力层和前馈全连接层组成;解码器层除了自注意力层和前馈层外,还包括编码器-解码器注意力层。
class EncoderLayer(nn.Module):
def __init__(self, size: int, self_attn: nn.Module, feed_forward: nn.Module, dropout: float):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.size = size
self.sublayer = clones(SublayerConnection(size, dropout), 2)
def forward(self, x: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
x = self.sublayer[1](x, self.feed_forward)
return x
class Encoder(nn.Module):
def __init__(self, layer: nn.Module, N: int):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, self_attn: nn.Module, src_attn: nn.Module,
feed_forward: nn.Module, dropout: float):
super(DecoderLayer, self).__init__()
self.d_model = d_model
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(d_model, dropout), 3)
def forward(self, x: torch.Tensor, memory: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
x = self.sublayer[2](x, self.feed_forward)
return x
class Decoder(nn.Module):
def __init__(self, d_model: int, layer: nn.Module, N: int):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(d_model)
def forward(self, x: torch.Tensor, memory: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)4.6 输出生成器与整体 Transformer 模型
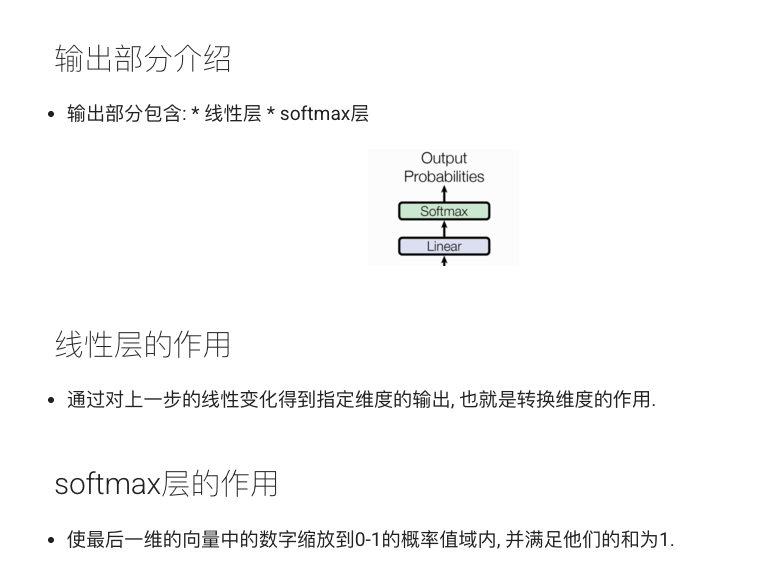
输出生成器(Generator)负责将解码器输出映射到目标词汇表上,并通过 log_softmax 生成对数概率。整体 Transformer 模型封装了编码器、解码器、嵌入层和输出层。
class Generator(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super(Generator, self).__init__()
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return F.log_softmax(self.project(x), dim=-1)
class EncoderDecoder(nn.Module):
def __init__(self, encoder: nn.Module, decoder: nn.Module,
source_embed: nn.Module, target_embed: nn.Module,
generator: nn.Module):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = source_embed
self.tgt_embed = target_embed
self.generator = generator
def forward(self, source: torch.Tensor, target: torch.Tensor,
source_mask: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
memory = self.encode(source, source_mask)
decoded = self.decode(memory, source_mask, target, target_mask)
return self.generator(decoded)
def encode(self, source: torch.Tensor, source_mask: torch.Tensor) -> torch.Tensor:
return self.encoder(self.src_embed(source), source_mask)
def decode(self, memory: torch.Tensor, source_mask: torch.Tensor,
target: torch.Tensor, target_mask: torch.Tensor) -> torch.Tensor:
return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)4.7 构建 Transformer 模型函数

最后,我们封装一个函数 make_model 来构建整个 Transformer 模型。该函数根据给定参数初始化各个模块,完成模型参数初始化(使用 Xavier 均匀初始化),并返回最终的 EncoderDecoder 模型。
def make_model(source_vocab: int, target_vocab: int, N: int = 6,
d_model: int = 512, d_ff: int = 2048, head: int = 8,
dropout: float = 0.1) -> nn.Module:
c = copy.deepcopy
attn = MultiHeadedAttention(head=head, embedding_dim=d_model, dropout=dropout)
ff = PositionwiseFeedForward(d_model=d_model, d_ff=d_ff, dropout=dropout)
position = PositionalEncoding(d_model=d_model, dropout=dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(d_model, DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, source_vocab), c(position)),
nn.Sequential(Embeddings(d_model, target_vocab), c(position)),
Generator(d_model, target_vocab)
)
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model4.8 测试 Transformer 模型
以下是一个测试函数 dm_test_make_model,用于构造测试输入、生成掩码,并通过 Transformer 模型前向传播得到输出。注意,这里掩码部分我们实现了动态生成 pad 掩码和后续掩码,这样用户不需要手动提供全0的掩码。
def dm_test_make_model():
source_vocab = 500
target_vocab = 1000
N = 6
model = make_model(source_vocab, target_vocab, N=N, d_model=512, d_ff=2048, head=8, dropout=0.1)
print(model) # 打印模型结构
# 构造测试输入:假设源数据和目标数据相同,形状为 [batch_size, seq_len]
source = torch.LongTensor([[1, 2, 3, 8], [3, 4, 1, 8]])
target = torch.LongTensor([[1, 2, 3, 8], [3, 4, 1, 8]])
# 自动生成掩码:
# 假设 pad token 为 0,则生成 pad 掩码;此处示例中输入不含 pad,可省略。
def create_pad_mask(seq: torch.Tensor, pad_token: int = 0) -> torch.Tensor:
return (seq != pad_token).unsqueeze(1)
source_mask = create_pad_mask(source, pad_token=0) # [batch_size, 1, src_seq_len]
# 生成后续掩码(下三角掩码)用于目标序列
def subsequent_mask(size: int) -> torch.Tensor:
subsequent_mask = torch.triu(torch.ones(1, size, size, dtype=torch.uint8), diagonal=1)
return subsequent_mask == 0
target_mask = subsequent_mask(target.size(1)).to(source_mask.device) # [1, tgt_seq_len, tgt_seq_len]
# 如果需要同时屏蔽 pad,可以将 pad 掩码和 subsequent mask 结合
pad_target_mask = create_pad_mask(target, pad_token=0) # [batch_size, 1, tgt_seq_len]
target_mask = pad_target_mask & target_mask # 广播与结合
output = model(source, target, source_mask, target_mask)
print("输出结果:", output)
print("输出形状:", output.shape)
if __name__ == '__main__':
dm_test_make_model()5. Transformer 的优化与扩展
Transformer 模型自发布以来,衍生出很多优化变体和扩展模型,例如 BERT、GPT、T5 等。下面介绍几种常见的优化思路:
5.1 模型参数初始化
在 Transformer 模型中,参数初始化非常关键。原论文中推荐使用 Xavier 均匀初始化(也称 Glorot 初始化),这种方法能够保持各层输出的方差稳定,从而有助于梯度传递。代码中我们已经在 make_model 函数中对所有参数使用了 nn.init.xavier_uniform_ 进行初始化。
5.2 掩码生成的改进
如前所述,掩码在 Transformer 中扮演了至关重要的角色。实际任务中,我们通常不希望用户手动提供全 0 掩码,而是自动生成 pad 掩码和后续掩码。
• 对于 pad 掩码,可以直接根据输入序列中 pad token 的位置生成。
• 对于后续掩码(look-ahead mask),生成下三角矩阵即可。
这两者可以通过逻辑与运算生成最终的目标掩码。
5.3 多头注意力的改进
原始 Transformer 中的多头注意力对每个头使用相同的计算流程,研究者后来提出了不同的变种,例如分离式注意力(separable attention)、改进的查询键分离策略等。
此外,如何高效实现大规模注意力计算也是一个热点问题,如 Linformer、Reformer 等模型提出了低秩近似或局部敏感哈希等方法来降低计算复杂度。
5.4 位置编码的改进
位置编码在 Transformer 中用于引入序列顺序信息,原始版本使用固定的正弦/余弦编码。后续工作中,BERT、RoBERTa 等预训练模型通常采用可学习的位置编码。此外,也有研究尝试利用相对位置编码(Relative Position Encoding)以更好地捕捉相对距离信息。
5.5 模型剪枝与加速
Transformer 模型参数量庞大,为了在移动设备或实时系统中应用,模型剪枝(Pruning)、量化(Quantization)以及知识蒸馏(Knowledge Distillation)等方法被广泛研究,以减小模型体积和加速推理过程。
6. 总结
Transformer 模型彻底改变了自然语言处理的研究方向,其基于注意力机制的设计突破了传统 RNN 的局限,实现了高效的并行计算和长距离依赖建模。本文详细介绍了 Transformer 模型的各个组成部分,包括:
1. 词嵌入与位置编码:将离散的词索引转换为连续的向量表示,并加入位置信息以捕捉序列顺序。
2. 注意力机制:核心的 Scaled Dot-Product Attention 及其多头变体,使模型可以灵活地捕获全局信息。
3. 前馈全连接层:增加模型的非线性表达能力,提高模型的拟合能力。
4. 层归一化与残差连接:缓解深层网络训练时的梯度消失问题,加快模型收敛速度。
5. 编码器和解码器结构:采用堆叠的 EncoderLayer 和 DecoderLayer 构建深层网络,实现源语言与目标语言之间的信息转换。
6. 掩码机制:自动生成 pad 掩码和后续掩码,确保模型在训练和推理过程中不会利用不应看到的信息。
此外,我们还讨论了 Transformer 模型的优化方法和扩展方向,从参数初始化、注意力计算优化到模型剪枝与量化,每个环节都是提升模型性能和效率的重要手段。
Transformer 模型以其高效并行、灵活捕获长距离依赖的优势,迅速成为 NLP 领域的核心架构。本文详细讲解了 Transformer 模型的各个模块——从嵌入层、位置编码、注意力机制、多头注意力、前馈网络、层归一化、残差连接到编码器和解码器的堆叠构造,以及如何利用自动生成的掩码确保模型正确工作。
通过完整的代码实现和详细解释,希望本文能帮助读者从理论到实践全面掌握 Transformer 模型,并为进一步优化与扩展提供参考。无论是用于机器翻译、文本生成还是其他 NLP 任务,Transformer 都为我们提供了强大的工具。未来,随着模型剪枝、量化和新型注意力机制的发展,Transformer 的应用前景将更加广阔。
参考资料
• Attention Is All You Need (论文原文)
• Transformer 论文(Attention Is All You Need):[1706.03762] Attention Is All You Need
• The Annotated Transformer(Harvard NLP):The Annotated Transformer
点赞、转发与反馈
如果你觉得本文对你理解 Transformer 模型有帮助,请点个赞、转发分享给更多的小伙伴,也欢迎留言讨论、指出不足,共同进步!
(完)

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









