




在数据库管理中,SQL查询性能优化是最常见且关键的任务之一。尤其是在大型应用程序和高并发环境中,慢SQL查询会严重影响系统的响应时间和吞吐量,导致用户体验下降。本文将详细介绍如何通过视图、执行计划、AWR报告、慢日志、系统资源等方面定位、分析并优化慢SQL查询,以提升数据库性能。
1、什么是慢SQL?
慢SQL指的是那些执行时间过长的SQL查询。不同数据库系统对慢查询的定义标准不同,不同复杂程度的查询语句对慢查询的界定也存在较大差异。在高并发环境下,慢SQL可能会成为性能瓶颈,影响整个系统的响应速度和可扩展性。
2、定位慢SQL
定位慢SQL查询是性能优化的第一步,先找到慢SQL语句才能“对症下药”。YashanDB有着丰富的定位慢SQL方法,可以通过SQL视图,自动工作负载存储库报告(AWR),数据库系统的慢日志等方法来定位。
YashanDB数据库中,有大量SQL相关视图来记录SQL语句的相关信息,如表1所示,列出部分相关SQL视图:

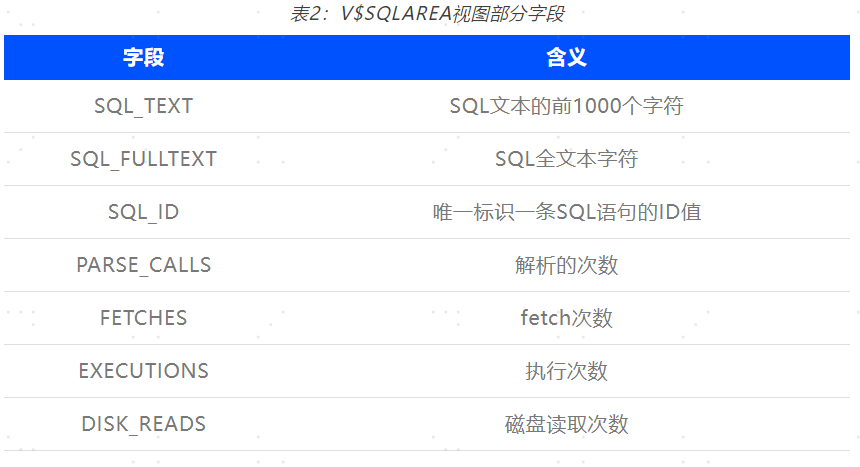
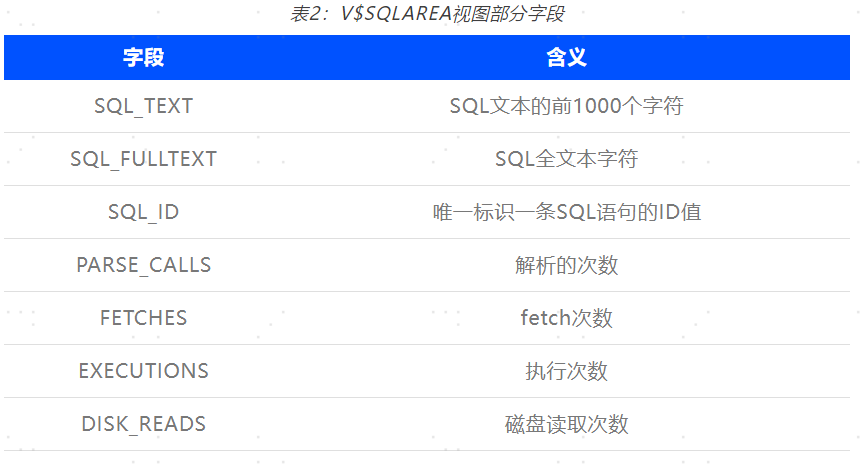
通过查询这些视图中执行时间列,并按其降序输出就能获取相关慢SQL。其中视图相关字段如表2所示:
**注:**以下各SQL语句在不同环境中执行,查询结果存在差异。
**例:**查询执行时间最长的TOP3 SQL,可以使用如下SQL语句进行查询,可以得到查询的SQL语句以及对应的执行时间(毫秒),结果如图1所示:
select sql_text,elapsed_time from v$sqlarea order by elapsed_time desc limit 3;
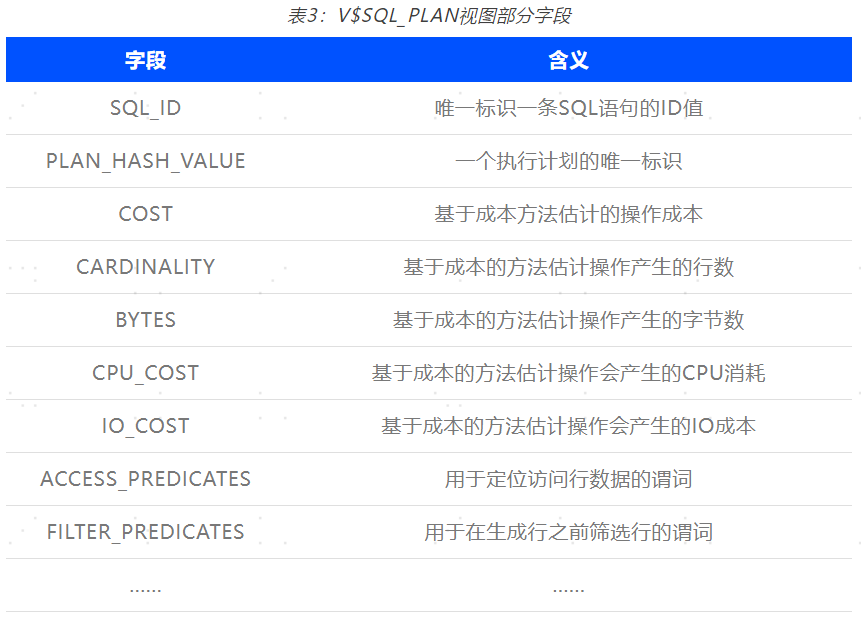
执行计划可用于分析慢SQL,SQL视图也能查询慢SQL语句当时的执行计划。YashanDB的SQL_PLAN视图可用于慢SQL执行计划查询,该视图的部分字段如表3所示:
例:查询执行时间最长SQL的执行计划以及时间消耗,结果如图2所示:
select operation, cost from v s q l _ p l a n w h e r e s q l _ i d i n ( s e l e c t s q l _ i d f r o m v sql\_plan where sql\_id in (select sql\_id from v s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









