










最优化理论
最优化理论与算法是一个重要的数据分支,也可以认为是运筹学。涵盖线性规划、非线性规划、整数规划、组合规划、图论、网络流、决策分析、排队论、可靠性数学理论、仓储库存论、物流论、博弈论、搜索论和模拟等分支,它所解决的问题是如何在众多的方案中找出最优方案。比如:工业设计中如何选择设计参数,使得设计方案既能满足要求又能降低成本;资源分配中,如何分配有限资源,既能满足需求又能得到最大的经济效益。
遗传算法
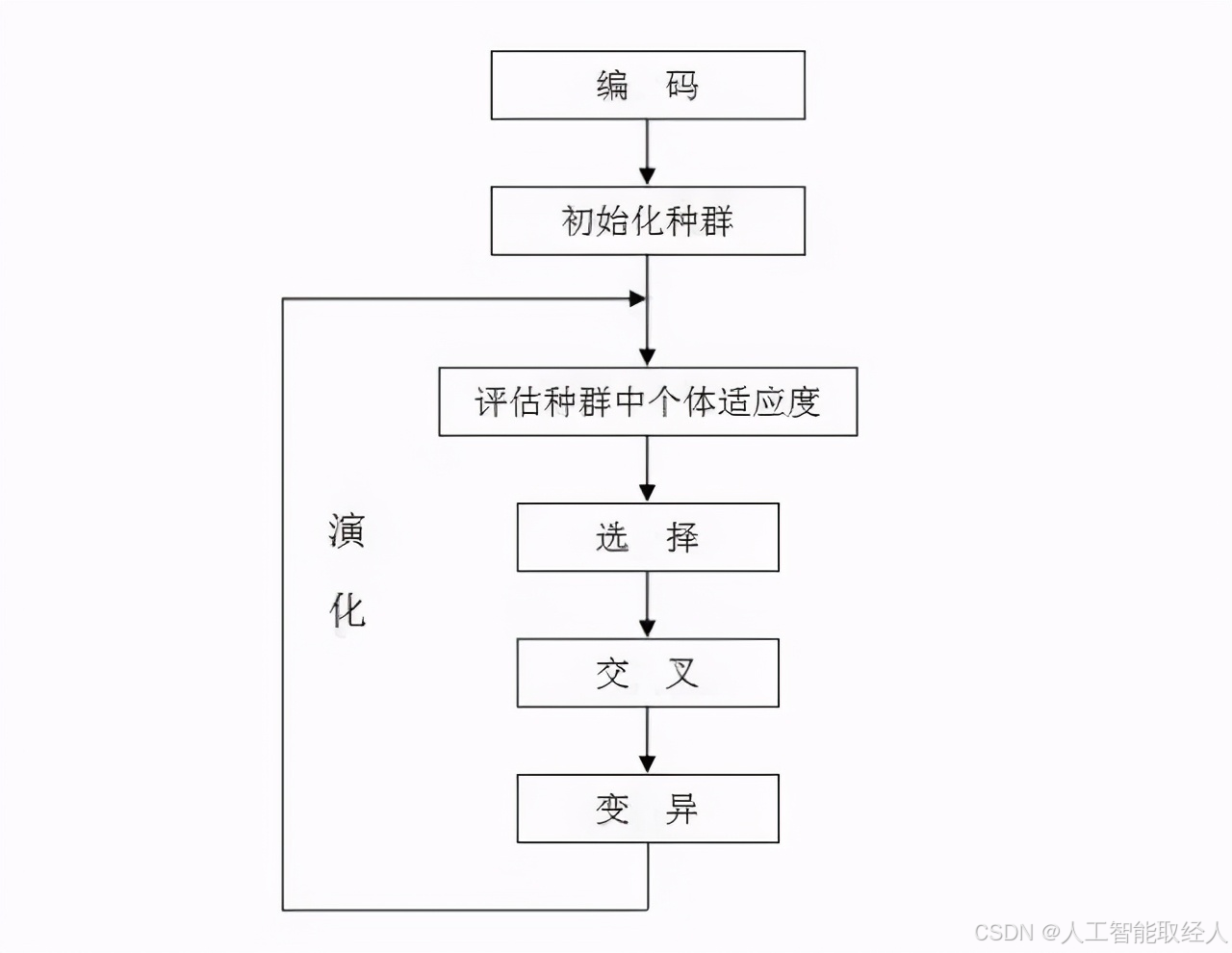
遗传算法(Genetic Algorithm, GA)是众多解决最优化问题算法中的一类,是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
本质上,遗传算法是排除法。通过从初始值出发,根据适应度函数选择优秀的个体留下来,排除不好的个体【数值】,通过变异和交叉不断扩展搜索空间,最后保留下最优的个体也就是问题的解。
python遗传算法代码实现
以案例求解y = 2*sin(x)+cos(x)的最大值为例,庖丁解牛遗传算法内部机理
初始化种群
#初始化生成chromosome_length大小的population_size个个体的二进制基因型种群
#输入种群大小和染色体长度,染色体用列表表示
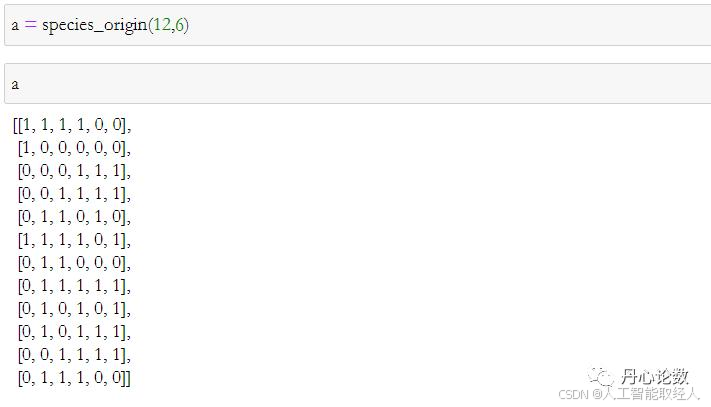
def species_origin(population_size,chromosome_length):
population=[]
#二维列表,包含染色体和基因
for i in range(population_size):
temporary=[]
#染色体暂存器
for j in range(chromosome_length):
temporary.append(random.randint(0,1))
#随机产生一个染色体,由二进制数组成
population.append(temporary)
#将染色体添加到种群中
return population
生成一个染色体长度为6,12个个体的种群
进制转换函数
#进制转换函数
def translation(population,chromosome_length):
temporary=[]
for i in range(len(population)):
total=0
for j in range(chromosome_length):
total+=population[i][j]*(math.pow(2,j))
#从第一个基因开始,每位对2求幂,再求和
# 如:0101 转成十进制为:1 * 20 + 0 * 21 + 1 * 22 + 0 * 23 = 1 + 0 + 4 + 0 = 5
temporary.append(total)
#一个染色体编码完成,由一个二进制数编码为一个十进制数
return temporary
种群a的转换结果

适应度计算
def function(population,chromosome_length,max_value):
temporary=[]
function1=[]
temporary=translation(population,chromosome_length)
# 暂存种群中的所有的染色体(十进制)
for i in range(len(temporary)):
x=temporary[i]*max_value/(math.pow(2,chromosome_length)-1)
#一个基因代表一个决策变量,其算法是先转化成十进制,然后再除以2的基因个数次方减1(固定值)。
function1.append(2*math.sin(x)+math.cos(x))
#这里将2*sin(x)+cos(x)作为目标函数,也是适应度函数
return function1
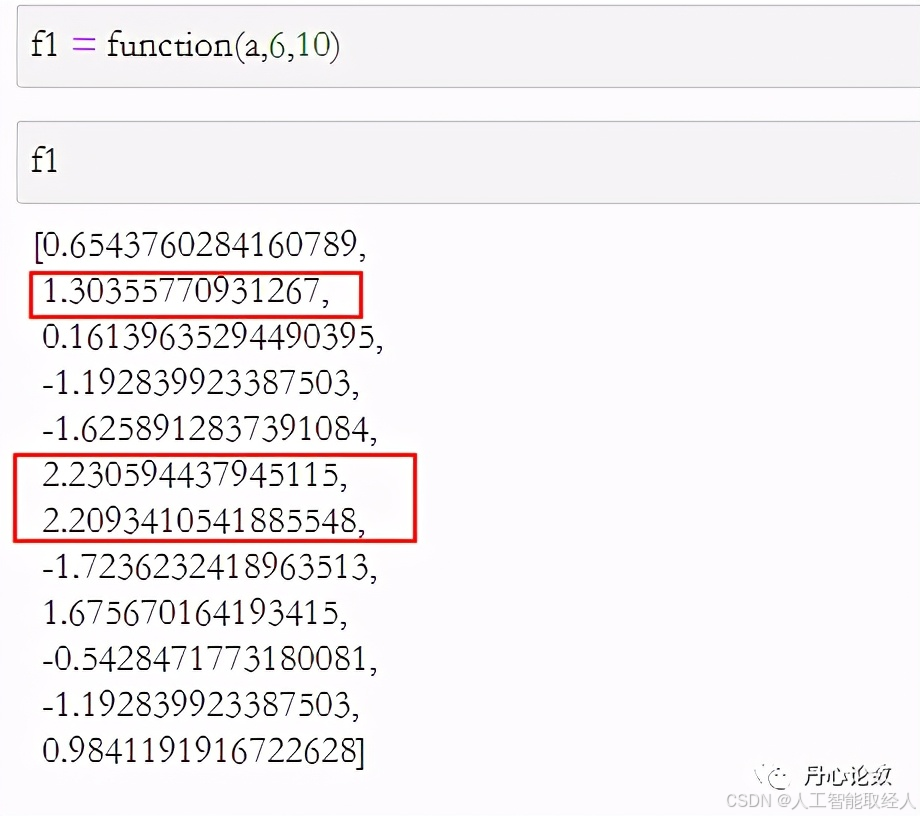
适应度函数用于选择优秀个体,适应度高的个体才会被选择
选择操作
#将小于0的适应度转化为0
def fitness(function1):
fitness1=[]
min_fitness=mf=0
for i in range(len(function1)):
if(function1[i]+mf>0):
temporary=mf+function1[i]
else:
temporary=0.0
# 如果适应度小于0,则定为0
fitness1.append(temporary)
#将适应度添加到列表中
return fitness1
#计算适应度和
def sum(fitness1):
total=0
for i in range(len(fitness1)):
total+=fitness1[i]
return total
#计算适应度斐波纳挈列表,这里是为了求出累积的适应度
def cumsum(fitness1):
for i in range(len(fitness1)-2,-1,-1):
# range(start,stop,[step])
# 倒计数
total=0
j=0
while(j<=i):
total+=fitness1[j]
j+=1
#这里是为了将适应度划分成区间
fitness1[i]=total
fitness1[len(fitness1)-1]=1
#3.选择种群中个体适应度最大的个体
def selection(population,fitness1):
new_fitness=[]
#单个公式暂存器
total_fitness=sum(fitness1)
#将所有的适应度求和
for i in range(len(fitness1)):
new_fitness.append(fitness1[i]/total_fitness)
#将所有个体的适应度概率化,类似于softmax
cumsum(new_fitness)
#将所有个体的适应度划分成区间
ms=[]
#存活的种群
population_length=pop_len=len(population)
#求出种群长度
#根据随机数确定哪几个能存活
for i in range(pop_len):
ms.append(random.random())
# 产生种群个数的随机值
ms.sort()
# 存活的种群排序
fitin=0
newin=0
new_population=new_pop=population
#轮盘赌方式
while newin<pop_len:
if(ms[newin]<new_fitness[fitin]):
new_pop[newin]=pop[fitin]
newin+=1
else:
fitin+=1
population=new_pop
交叉操作
def crossover(population,pc):
#pc是概率阈值,选择单点交叉还是多点交叉,生成新的交叉个体,这里没用
pop_len=len(population)
for i in range(pop_len-1):
cpoint=random.randint(0,len(population[0]))
#在种群个数内随机生成单点交叉点
temporary1=[]
temporary2=[]
temporary1.extend(pop[i][0:cpoint])
temporary1.extend(pop[i+1][cpoint:len(population[i])])
#将tmporary1作为暂存器,暂时存放第i个染色体中的前0到cpoint个基因,
#然后再把第i+1个染色体中的后cpoint到第i个染色体中的基因个数,补充到temporary2后面
temporary2.extend(pop[i+1][0:cpoint])
temporary2.extend(pop[i][cpoint:len(pop[i])])
# 将tmporary2作为暂存器,暂时存放第i+1个染色体中的前0到cpoint个基因,
# 然后再把第i个染色体中的后cpoint到第i个染色体中的基因个数,补充到temporary2后面
pop[i]=temporary1
pop[i+1]=temporary2
# 第i个染色体和第i+1个染色体基因重组/交叉完
变异操作
#step4:突变
def mutation(population,pm):
# pm是概率阈值
px=len(population)
# 求出种群中所有种群/个体的个数
py=len(population[0])
# 染色体/个体中基因的个数
for i in range(px):
if(random.random()<pm):
#如果小于阈值就变异
mpoint=random.randint(0,py-1)
# 生成0到py-1的随机数
if(population[i][mpoint]==1):
#将mpoint个基因进行单点随机变异,变为0或者1
population[i][mpoint]=0
else:
population[i][mpoint]=1
运行结果
# 将每一个染色体都转化成十进制 max_value为基因最大值,为了后面画图用
def b2d(b,max_value,chromosome_length):
total=0
for i in range(len(b)):
total=total+b[i]*math.pow(2,i)
#从第一位开始,每一位对2求幂,然后求和,得到十进制数?
total=total*max_value/(math.pow(2,chromosome_length)-1)
return total
#寻找最好的适应度和个体
def best(population,fitness1):
px=len(population)
bestindividual=[]
bestfitness=fitness1[0]
for i in range(1,px):
# 循环找出最大的适应度,适应度最大的也就是最好的个体
if(fitness1[i]>bestfitness):
bestfitness=fitness1[i]
bestindividual=population[i]
return [bestindividual,bestfitness]
population_size=500
max_value=10
# 基因中允许出现的最大值
chromosome_length=10
pc=0.6
pm=0.01
results=[[]]
fitness1=[]
fitmean=[]
population=pop=species_origin(population_size,chromosome_length)
#生成一个初始的种群
for i in range(population_size):#注意这里是迭代500次
function1=function(population,chromosome_length,max_value)
fitness1=fitness(function1)
best_individual,best_fitness=best(population,fitness1)
results.append([best_fitness,b2d(best_individual,max_value,chromosome_length)])
#将最好的个体和最好的适应度保存,并将最好的个体转成十进制
selection(population,fitness1)#选择
crossover(population,pc)#交配
mutation(population,pm)#变异
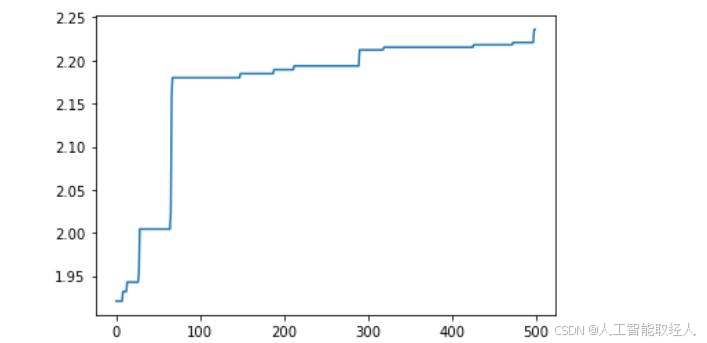
results=results[1:]
results.sort()
X=[]
Y=[]
for i in range(500):#500轮的结果
X.append(i)
Y.append(results[i][0])
plt.plot(X,Y)
plt.show()
geatpy模块
geatpy是封装好的python遗传算法包,还是拿案例来说明。
求解
max f (x1, x2, x3) = 4x1 + 2x2 + x3
s.t.
2x1 + x2 ≤ 1
x1 + 2x3 ≤ 2
x1 + x2 + x3 = 1
x1 ∈ [0, 1], x2 ∈ [0, 1], x3 ∈ (0, 2)
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'MyProblem' # 初始化name(函数名称, 可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [-1] # 初始化目标最小最大化标记列表, 1:min;-1:max
Dim = 3 # 初始化Dim(决策变量维数)
varTypes = [0] * Dim # 初始化决策变量类型, 0:连续;1:离散
lb = [0,0,0] # 决策变量下界
ub = [1,1,2] # 决策变量上界
lbin = [1,1,0] # 决策变量下边界
ubin = [1,1,0] # 决策变量上边界
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def aimFunc(self, pop): # 目标函数, pop为传入的种群对象
Vars = pop.Phen # 得到决策变量矩阵
x1 = Vars[:, [0]] # 取出第一列得到所有个体的x1组成的列向量
x2 = Vars[:, [1]] # 取出第二列得到所有个体的x2组成的列向量
x3 = Vars[:, [2]] # 取出第三列得到所有个体的x3组成的列向量
# 计算目标函数值, 赋值给pop种群对象的ObjV属性
pop.ObjV = 4*x1 + 2*x2 + x3
# 采用可行性法则处理约束, 生成种群个体违反约束程度矩阵
pop.CV = np.hstack([2*x1 + x2 - 1, # 第一个约束
x1 + 2*x3 - 2, # 第二个约束
np.abs(x1 + x2 + x3 - 1)]) # 第三个约
import geatpy as ea # import geatpy
"""============================实例化问题对象========================"""
problem = MyProblem() # 实例化问题对象
"""==============================种群设置==========================="""
Encoding = 'RI' # 编码方式
NIND = 50 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges,problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) #实例化种群对象(此时种群还没被真正初始化, 仅仅是生成一个种群对象)
"""===========================算法参数设置=========================="""
myAlgorithm = ea.soea_DE_best_1_L_templet(problem, population) #实例化一个算法模板对象
myAlgorithm.MAXGEN = 1000 # 最大进化代数
myAlgorithm.mutOper.F = 0.5 # 差分进化中的参数F
myAlgorithm.recOper.XOVR = 0.7 # 设置交叉概率
myAlgorithm.logTras = 1 #设置每隔多少代记录日志, 若设置成0则表示不记录日志
myAlgorithm.verbose = True # 设置是否打印输出日志信息
myAlgorithm.drawing = 1 #设置绘图方式(0:不绘图;1:绘制结果图;2:绘制目标空间过程动画;3:绘制决策空间过程动画)
"""==========================调用算法模板进行种群进化==============="""
[BestIndi, population] = myAlgorithm.run() #执行算法模板, 得到最优个体以及最后一代种群
BestIndi.save() # 把最优个体的信息保存到文件中
"""=================================输出结果======================="""
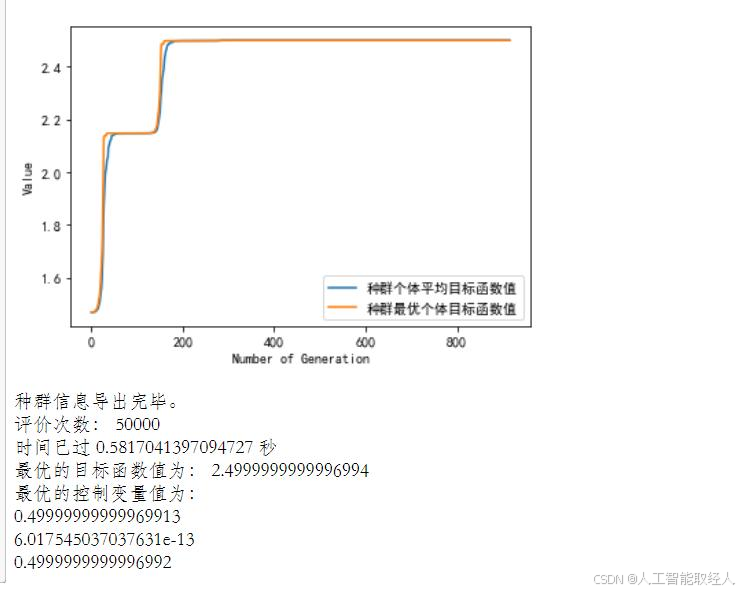
print('评价次数:%s' % myAlgorithm.evalsNum)
print('时间已过 %s 秒' % myAlgorithm.passTime)
if BestIndi.sizes != 0:
print('最优的目标函数值为:%s' % BestIndi.ObjV[0][0])
print('最优的控制变量值为:')
for i in range(BestIndi.Phen.shape[1]):
print(BestIndi.Phen[0, i])
else:
print('没找到可行解。')
总结
最优化问题不同于传统的机器学习需要大量的数据作为支撑,从数据中挖掘信息和知识规则,优化问题的难点主要在于如何将决策问题转化为带有约束条件的目标规划问题,比如:车辆匹配问题可以抽象为如下数学模型:


利用python设置好目标函数、适应度函数(一般情况,跟目标函数相同)、约束条件、遗传操作相关参数【染色体长度、编码形式、初始族群、选择比例、交叉位置、变异比例】

















 3582
3582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









