









ABTest在互联网产品运营中发挥重要的作用。验证产品优化的好坏,产品改进后点击率优化了多少都可以用到ABTest。
所谓ABTest,就是为同一个目标制定两个方案(比如两个页面),让一部分用户使用A方案,另一部分用户使用B方案,记录下用户的使用情况,看哪个方案更符合设计目标。
举个例子:企业为了确定对于某游戏优化是否有效,选取实验组和对照组。实验组使用优化的游戏,对照组使用原游戏,一段时候得到实验组和对照组对产品的评分,使用假设检验方法判断优化是否有效。
咋一看,ABTest有点对照实验那意思,虽然定义简单,但在算法策略验证和产品优化验证中经常被使用到,以下从八个问题出发,深入ABTest原理。
问题 1:什么场景可以用 AB Test?
其实这个问题是非常基础的,主要有两个应用场景:产品迭代与策略优化。
产品迭代:比如界面优化、功能增加、流程增加,这些都可以使用 AB 实验测试产品改版是否成功。
策略优化:无论是运营策略还是算法策略,都可以通过 AB 实验的方式验证策略是否达到预期目标。
问题 2:AB 实验的底层逻辑是什么?
这些问题其实是在考察基础统计学知识,以及 AB 实验为什么能获得业界认可,背后的科学理论是什么?
其实主要基于两点。
随机化。AB 实验通过随机化的处理,使所有影响 treatment 到 effect 的混杂因子(Confounded Factor)失效。简单理解就是,随机化使全部的外在干扰因素都失效了,treatment 成为了产生差异的唯一来源。
AB test 的统计学基础——假设检验。假设检验顾名思义,就是对样本特征提出一个假设,然后来检验这个假设是否正确,怎么检验呢,自然肯定是利用正态分布之类的统计理论了。
本质上来说,假设检验就是根据构造的统计量所符合的统计学理论分布,采用小概率理论来推断假设是否正确。如果原假设发生的概率较大则接受原假设,如果原假设发生的概率为小概率事件则抛弃原假设,接受除原假设以外的其他情况。
举个例子:
假设某 APP 为 DAU 1200人,标准差为 150。产品经理增加了一个天天打卡的功能,随机抽取了其后 30 天的 DAU,计算了下 DAU 为 1245 人,那么能否说改版后DAU显著高于改版前?
假设一个命题,产品的功能迭代升级实际上没有成效,所统计出来的 1245 看似比原来的1200 高 45,我们假定这个是抽样的随机误差导致的。
于是我们有了原始假设 H0 和备择假设 H1
H0 = 改版后用户访问量均值小于等于 1200(意思就是分布仍然符合均值为1200的高斯分布)
H1 = 改版后用户访问量均值大于1200
注意 H1 命题是 H0 命题的备择假设,也就是包含了除 H0 以外的其他信息。
第二步就是构建统计量,可以构建 Z 统计量。
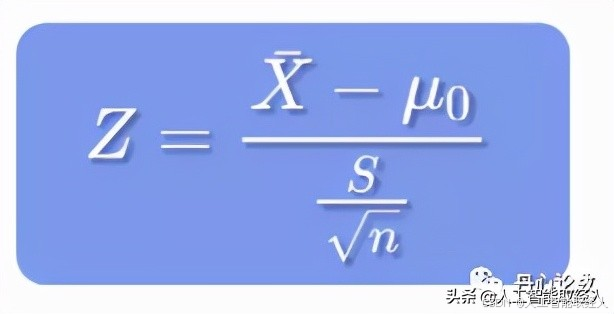
第三步:验证假设是否成立。
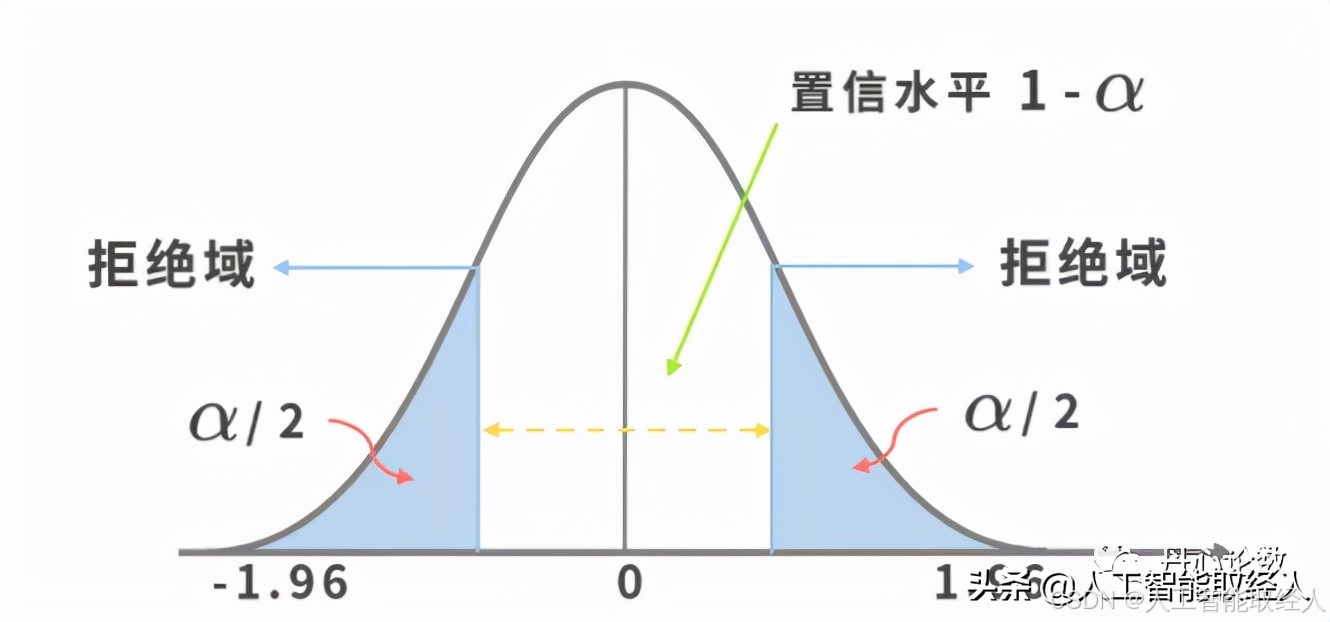
通过计算得出,z=1.34,小于图中的 1.96,没有落到拒绝域中,因此我们不能拒绝原假设,那么我们可以得出结论,这个产品经理的功能改版 95% 的可能性来说,是没有提升 DAU 的。
问题 3:AB 实验需要多大的样本?AB 实验需要做多久是如何确定的?
我们知道何时开始一个实验,但是不知道何时结束,就是因为我们不知道如何计算样本量。平时经常看见有些 AB 实验能做几个月甚至一年,这明显违背了 AB 实验的初衷,即我们要以最小的成本,最快的时间去验证策略的有效性。
其实计算样本量,有套路可循,有一个通用的公式可以计算:

α:第一类错误概率(也叫弃真错误),一般取0.05
β:第二类错误概率(也叫取伪错误),一般取0.2
Δ:|u1-u2|,指标预期的变化量,指标的绝对变化量,如5% 增长到10%,指标变化量为10%-5%=5%
σ2:指标的方差
注意事项:
①如果实验有多个指标需要通过 ABTest 来验证,则需要选择那个需要样本量最大的指标所需的样本量作为实验的样本量。
②计算结果是每个分组的最低样本量,两个分组加在一起的样本量是需要翻倍的。
③样本量可以是一段时间累积的总量,例如实验总共需要 10000 个样本,每天最多产生 1000 个样本,则实验持续 10 天可以满足样本量的基础需求。
问题 4:AB 实验如何选择实验城市?
原则一:尽量选择大体量城市,小体量城市样本小,需要更长的实验周期;
原则二:在做实验的时候要选择不同类型城市(一般公司都会有一个城市分级,会依据城市的不同属性分为一级二级三级城市等等,不同的公司分级标准不同,使用自己公司的分级标准即可),实验策略可能对不同类型的城市有不同效果,需要通过选择不同类城市,使实验具有普适性。
问题 5:如何确定分流时机?
实验分流的触发点是且只能是策略的生效点。
为什么只能在策略生效点分流呢?原因在于 AB 实验通过随机化的方式,使所有影响 treatment到 effect 的混杂因子(Confounded Factor)失效,进而使策略是产生差异的唯一来源。
举个例子
大家在用滴滴打车的时候,经常会接收到弹窗,告诉你给你一个优惠,就可以让你升级优享或者专车。这个弹窗就是导流策略,但是弹窗的出发是基于一定规则的,不是所有场景都会触发。现在我们要做一个实验,想要测试导流对全局 GMV 是否有正向的提升作用?
在这个实验里面,我们应该在什么地方分流呢?
我给大家三个选项:
A. 对滴滴所有存量用户进行分流
B. 对滴滴所有快车订单进行分流
C. 对滴滴所有满足导流策略的订单,进行分流
A 和 B 两个选项都不是策略生效的场景,策略在用户打快车订单,并且满足策略触发条件的时候才会生效。因此正确答案是 C。
有时候,我们信心满满的做完了一个 AB 实验,结果发现 AB 实验的效果挺好,但是上线之后效果并不如预期
问题 6:做 AB 实验的时候,数据对比上涨 25%,判定为效果显著,但上线后效果不好,为什么?
实验效果好,但上线效果不好的原因可能要从两方面来分析。
第一,首先还是要检查 AB 实验的科学性,是否 AB 实验的流程和步骤是科学而且合理的,常见的问题有以下几类。
样本量不足:样本量小,结果是随机波动导致,并不置信。
实验时间太短。在观测实验结果时要小心“新奇效应”,也就是实验时间过短的情况下,用户由于新鲜感而表现出不可持续的行为。观测实验结果下定论需要等实验的结果稳健以后才可进行。
实验人群≠上线人群:实验城市不同,实验对象不同可能会引起的策略效果差异,所以做实验时应该尽量保证样本与总体一致。
其次,检查外部环境。如果外部环境和试验期间的外部环境产生了非常大的变化,则也可以使试验效果与上线效果不一致。比如在打车场景下,我们知道如果下雨或者下雪的时候,订单量会激增,用户的心理和行为与平日是有较大差异的。因此如果实验期间天气恶劣,而上线后天气很好,则会影响实验效果与实际效果的一致性。
问题 7:统计上显著,但是业务觉得没有上涨,这个是怎么回事?
统计上的显著定义:本质是通过假设检验的方式,来看两组样本数据一样是否是一个小概率事件。
统计显著是一个统计学概念,指的是数据差异随机产生的难度有多大,它不是一个业务上的概念,是一个通过理性计算算出来的数据。
我们在做假设检验时,大部分使用 Z 检验

统计上的显著,是一个依赖于效应量(u1-u2)和样本量(n1,n2)的实验设计输出,试想:如果样本量无限大,会怎样?在样本量足够大的,p 值就会趋近于0,任何策略都在统计学意义上是显著的。
而业务显著是一个业务上的判断,要求新策略上线后必须有实际上的业务意义。
如果仅仅是在统计学意义上实验策略是显著的,而不考虑商用价值,最后所有的 AB 实验都会沦为数字游戏。
比如某实验,实验组比对照组转化率提升了 0.00025%,因为实验覆盖了千万 DAU,P –value 小于 0.001,这样的数据即使在统计上是显著的,也不具备任何实际的商业意义。
统计显著是一个统计学的概念,在样本量过大的时候,任何策略都会在统计上显著,所以不能说统计上显著就可以了。而业务显著指的是策略是否有足够的增长,是否具有商业价值,是一个业务判断。因此为了避免这个问题,应该前置解决,即在实验开始前,设定好预计提升量(业务显著),在此基础上计算所需样本量,然后再去进行实验设计,就不会出现这个问题。
问题 8什么场景不可以用 AB Test?AB 实验是万能的吗?
AB 实验当然不是万能的,它也是有局限性的。比如这些场景AB实验就不太能起效果。
用户体验制约:一些较为敏感的策略,如价格调整,激励变化等,往往需要顾及用户间的体验公平性和用户长期体验的一致性。比如美团配送之前被曝光的不同手机用户同一时间在一个商户下单,配送费不一致,其实就是AB实验导致的,只是媒体不会按照这个解读,对用户价格歧视明显更有话题性。
样本数量制约:部分场景由于天然不可抗力因素导致样本量非常小,无法达到统计学上大样本的要求。典型场景如:防止侵害的安全类措施(高危样本量减小且无法认为扩大)。
AB 组间存在干扰:AB 实验假设 AB 两组都是独立样本,可以独立作出判断,如果两组互相影响,则不能进行 AB 实验。
比如司机激励策略,A 策略是对司机进行“冲单奖”激励,每日在线时长>5h,且完单量>10单的司机会获得额外奖励;B 策略是无激励。因司机私下有司机群,司机群会对激励策略进行讨论,无激励的司机会认为受到不公平待遇,从而对 B 策略的效果产生影响,这就是所说的存在组间影响的例子,所以这种情况便不能够对同城的司机进行实验。
总结:
ABTest虽然很简单,但是也是数据分析师工作中经常使用的效果评估方法,搞懂以上八个问题,基本上就解决了ABTest。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









