







先修知识:
- RNN https://blog.youkuaiyun.com/weixin_41332009/article/details/114023882?spm=1001.2014.3001.5501
- RNN 变种
https://blog.youkuaiyun.com/weixin_41332009/article/details/114044090?spm=1001.2014.3001.5501 - Seq2seq+attention https://blog.youkuaiyun.com/weixin_41332009/article/details/114129748?spm=1001.2014.3001.5501

1. 引言
读完“先修知识”一栏中的文章之后,你会发现:RNN由于其顺序结构训练速度常常受到限制,既然Attention模型本身可以看到全局的信息, 那么一个自然的疑问是我们能不能去掉RNN结构,仅仅依赖于Attention模型呢,这样我们可以使训练并行化,同时拥有全局信息?
这一篇就主要根据谷歌的这篇 Attention is All you need 论文来回顾一下仅依赖于Attention机制的Transformer架构。
2. Transformer总体结构
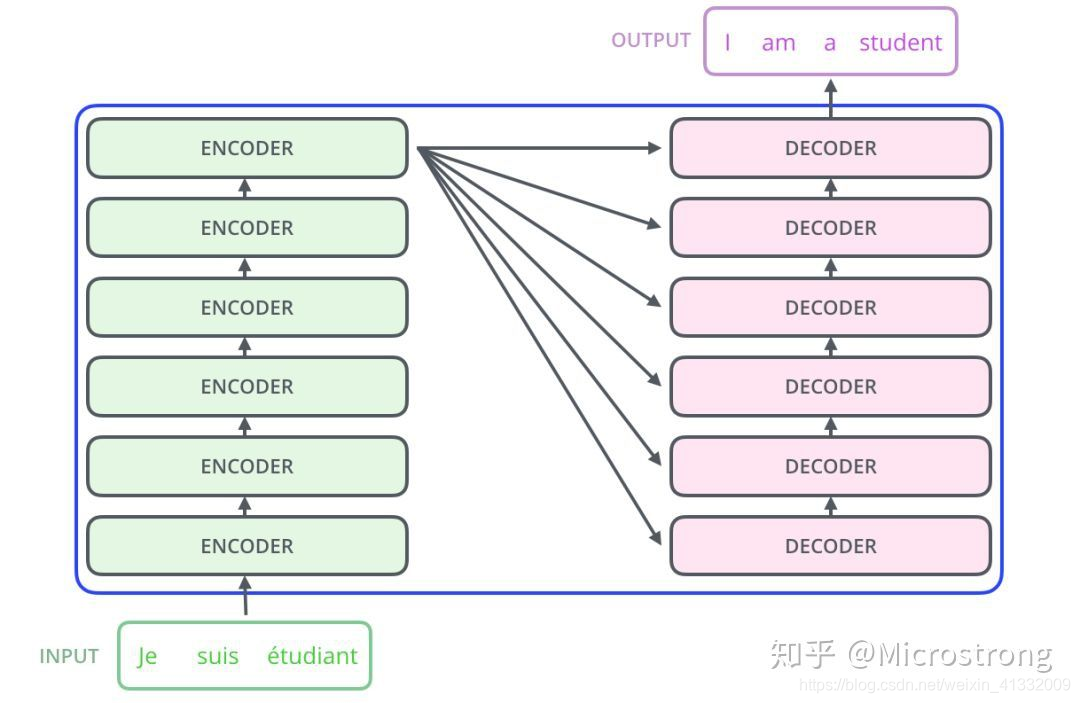
Transformer的结构也采用了 Encoder-Decoder 架构。但其结构更加复杂,论文中Encoder层由6个Encoder堆叠在一起,Decoder层也一样。
每一个Encoder和Decoder的内部结构如下图:
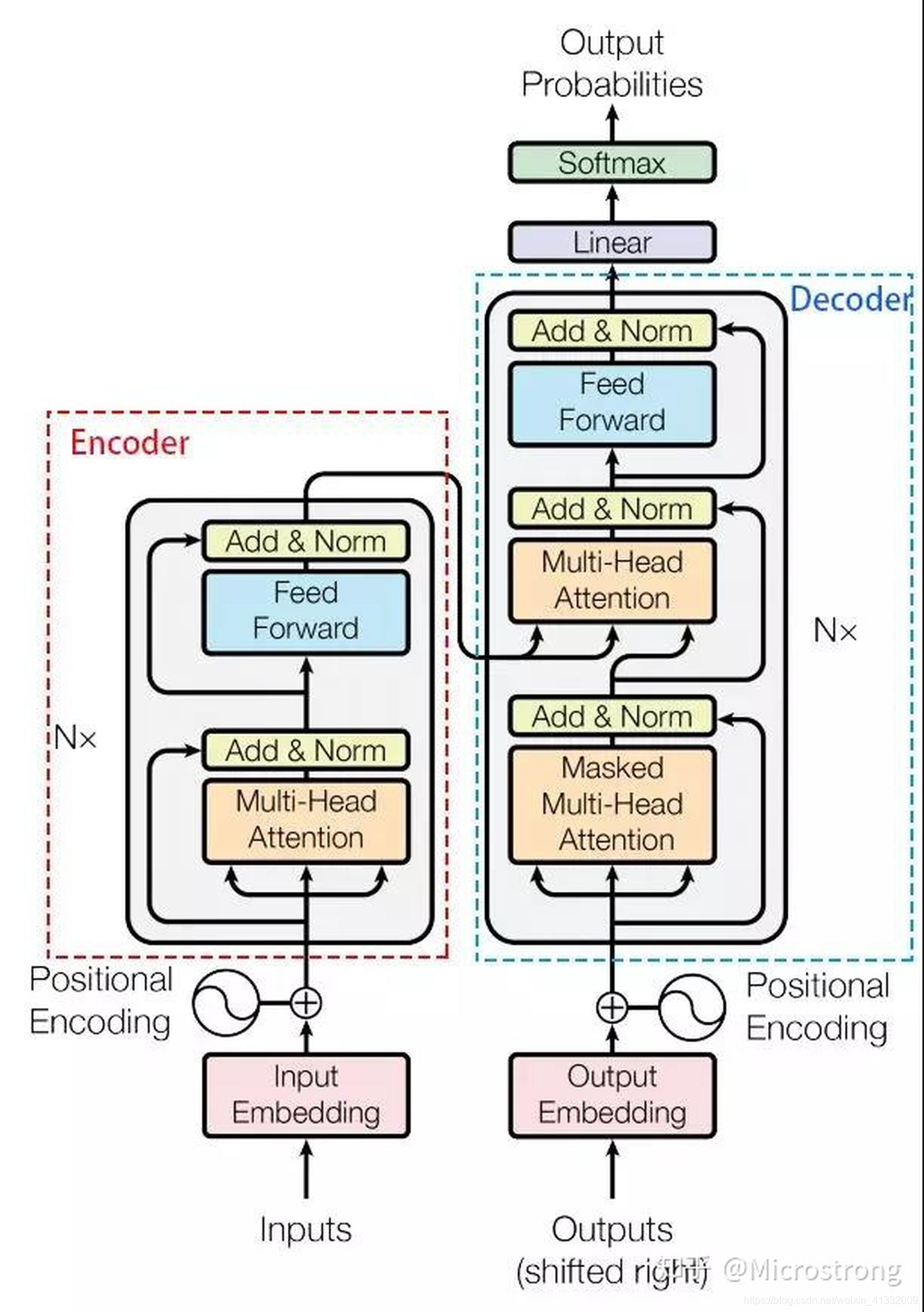
- Encoder包含两层,一个Self-attention层(Multi-Head Attention)和一个前馈神经网络层(feed forward),Self-attention层能帮助当前节点不仅仅只关注当前的词,从而能获取到上下文的语义。
- Decoder也包含Encoder提到的两层网络,但是在这两层中间还有一层Attention层,帮助当前节点获取到当前需要关注的重点内容。
2.1 Encoder层详细说明
首先,模型需要对输入的数据进行一个embedding操作,并输入到Encoder层,Self-attention处理完数据后把数据送给前馈神经网络,前馈神经网络的计算可以并行,得到的输出会输入到下一个Encoder。大致结构如下:
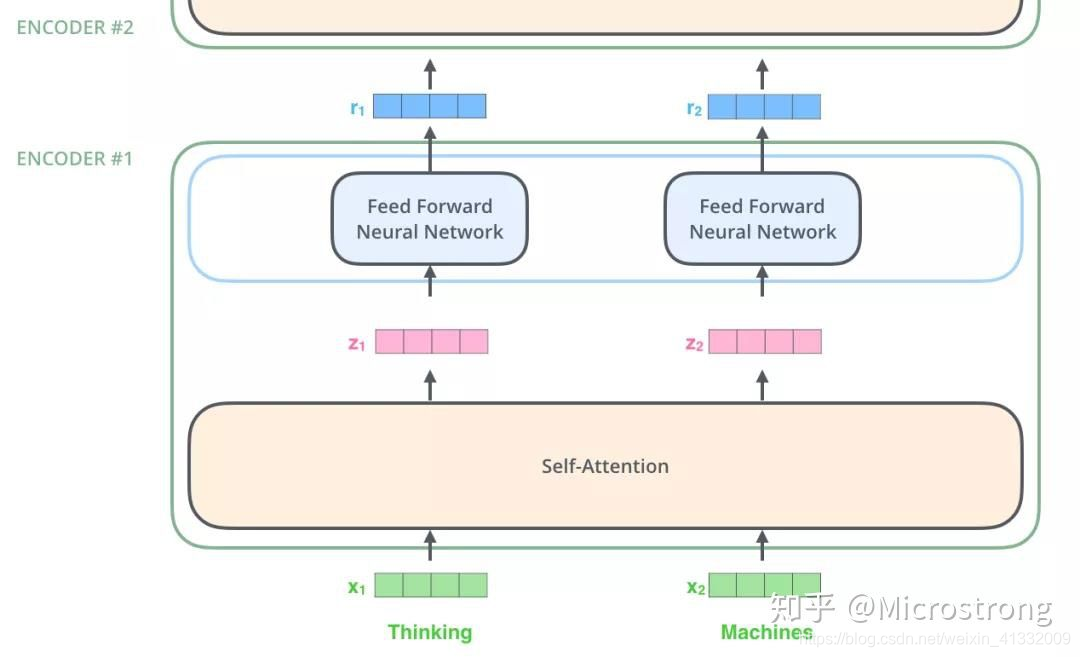
x 1 , x 2 x_1, x_2 x1,x2就是embedding, z 1 , z 2 z_1, z_2 z1,z2是经过self-attention之后的输出,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









