






 本文概述了大模型从专用到通用的发展,重点介绍了InternLM开源历程,包括InternLM2的7B和20B模型及其增强版本,强调了微调、算力、智能体和全链条开源工具的重要性。同时提到了评测体系和多模态智能体工具AgentLego的应用。
本文概述了大模型从专用到通用的发展,重点介绍了InternLM开源历程,包括InternLM2的7B和20B模型及其增强版本,强调了微调、算力、智能体和全链条开源工具的重要性。同时提到了评测体系和多模态智能体工具AgentLego的应用。
大模型逐渐从专用大模型向通用大模型转变,即一个模型对应多种任务和模态.
书生浦语大模型开源历程
2023年6月发布InternLM第一代大模型,一个月后开源模型及全链条工具体系
8月开源多模态语料库 chat7B以及lagent
9月开源InternLM20B并且升级全线开源工具链
2024年1月17日 InternLM2 开源
InternLM2体系
InternLM2有7B(Billion)和20B两种不同参数量级的模型,前者更轻量级,后者能支持更复杂的场景.
每个参数规格包含三种不同的模型版本
InternLm2-Base 基座模型
InternLM2 通过base在多个能力上进行了强化
InternLM2-Chat 在base基础上经过SFT和RLHF,面向对话交互进行了优化.简单来说就是注入一些人的对话思维
SFT(Supervised Fine-Tuning) 监督微调
RLHF(human feedback) 基于人类反馈的强化学习
InternLM2的主要亮点
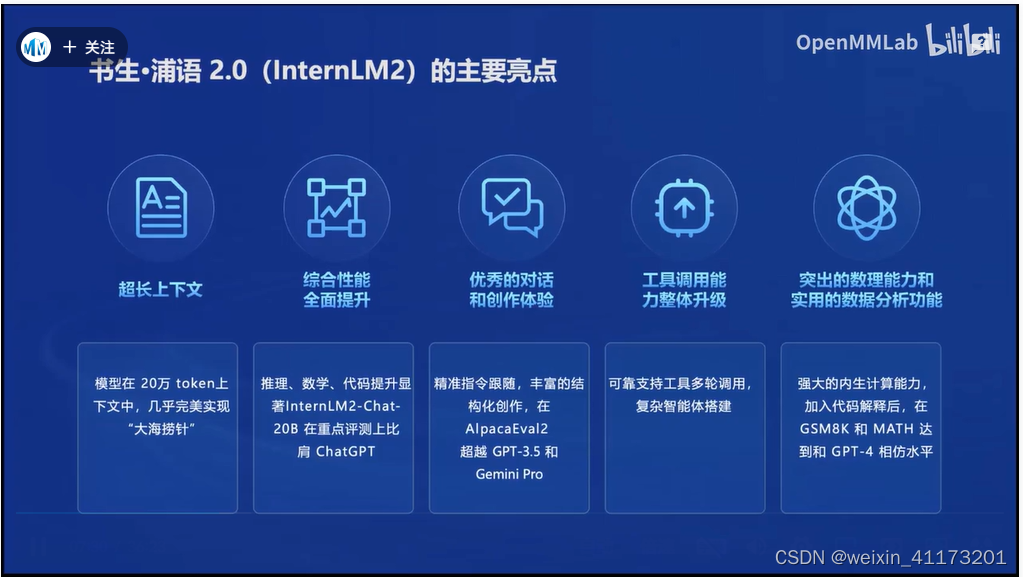
InternLM2的全链条开源体系
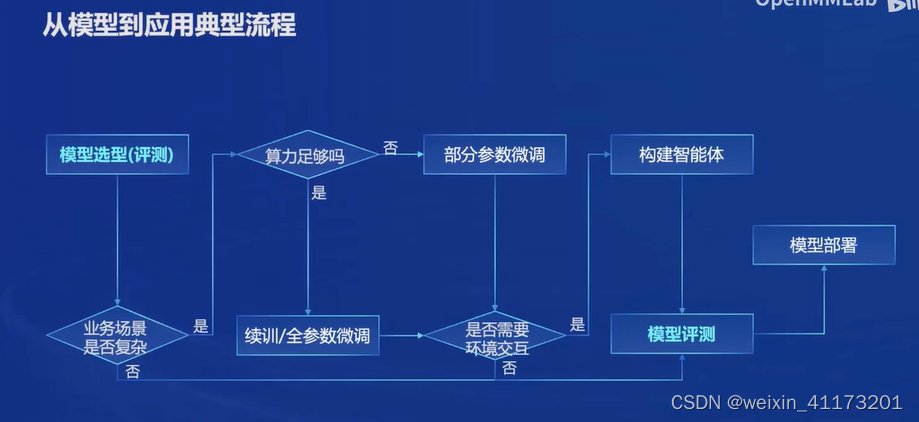
上图里可以看到大模型不只是微调,还有其他重要的环节:算力也是大模型开发微调很重要的一个因素; 智能体可以赋予大模型更强大的能力; 对模型的测评可以对模型的能力有更清晰的评估
而InternLM2从数据到模型落地的整个流程都有工具支持
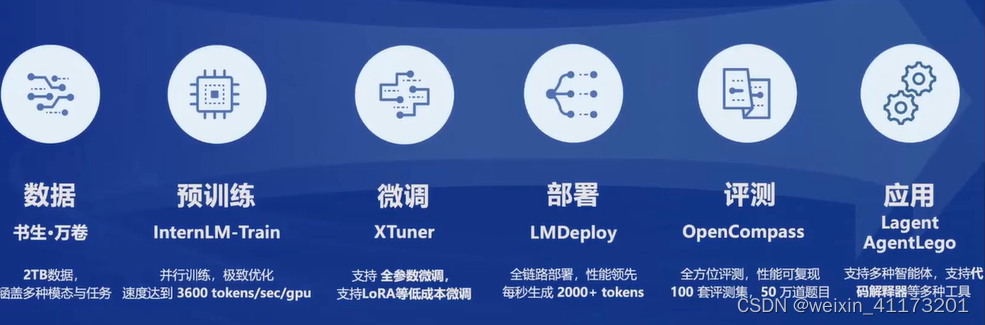
数据
值得一提的是书生万卷cc对有毒性/色情/个人隐私信息都进行了安全加固处理,可能会对舆情监控有所帮助

预训练

微调
大语言模型的下游应用中,增量续训和有监督微调是经常会用到的两种方式
增量训练是指让base学习到新知识,训练数据一般有文章\书籍\代码等
有监督微调是让大模型学会理解指令进行对话或少量注入领域知识,训练数据一般是高质量对话及问大数据
微调一般也分为全量参数微调和部分参数微调
适配的微调工具为XTuner
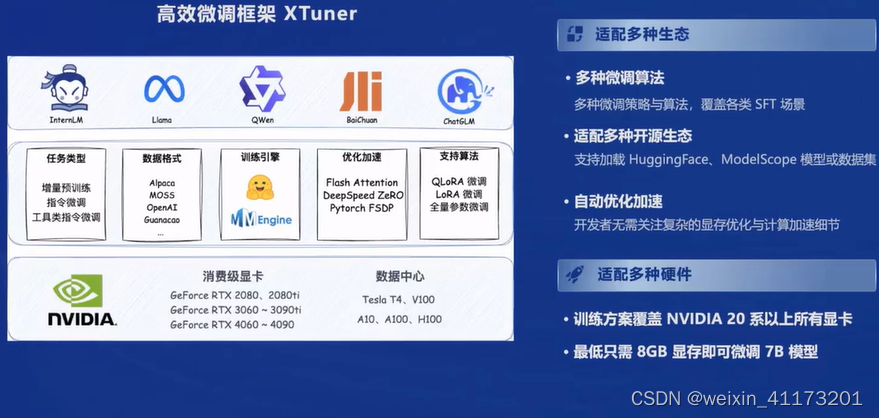
实际应用下来感觉确实比较好用,但是8GB还是不太够,侧面也反映了算力对大模型来说是个关键因素
评测
2024年1月30日 OpenCompass司南大模型评测体系 正式发布
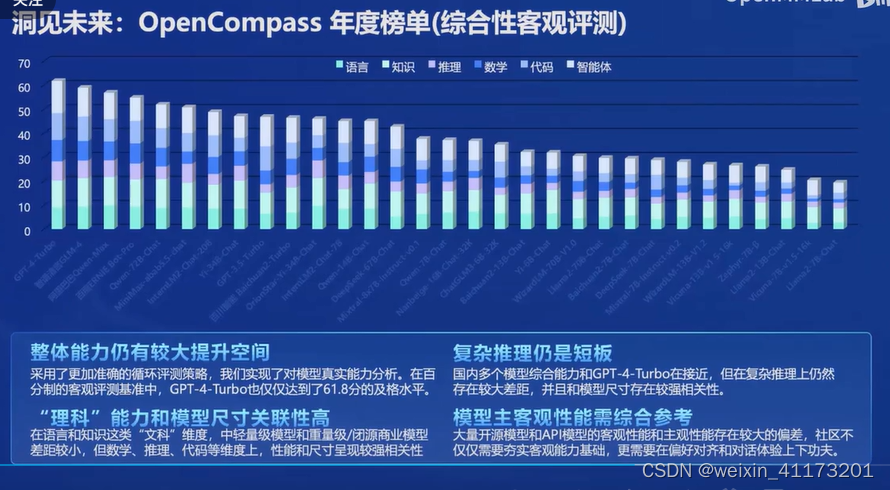
一些评测结果, 看起来国外还是比较领先的,也反映了一些大模型的公共短板
部署

智能体
我理解起来智能体就像是一些比较有针对性的小模型,就像小组件可以丰富大模型
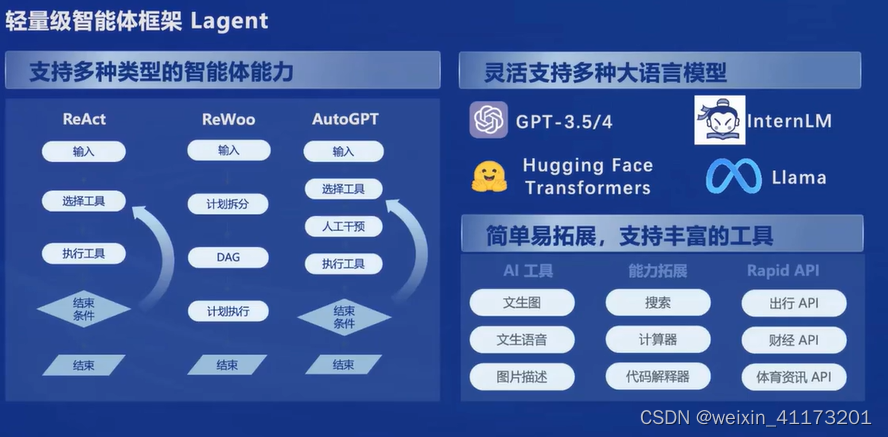
还有多模态智能体工具箱AgentLego,有很多前沿算法,尤其是针对视觉和多模态的

















 2119
2119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









