







项目目录
 这里主要就看我在目录里强调的就行了,其他的是我练手瞎写的
这里主要就看我在目录里强调的就行了,其他的是我练手瞎写的
config.py
import argparse
def get_parser():
parser = argparse.ArgumentParser(description='parameters to train net')
parser.add_argument('--max_epoch', default=1, help='epoch to train the network')
parser.add_argument('--img_size', default=(94, 24), help='the image size')
parser.add_argument('--dropout_rate', default=0.5, help='dropout rate.')
parser.add_argument('--learning_rate', default=0.0001, help='base value of learning rate.')
parser.add_argument('--lpr_max_len', default=8, help='license plate number max length.')
parser.add_argument('--train_batch_size', default=128, help='training batch size.')
parser.add_argument('--test_batch_size', default=128, help='testing batch size.')
parser.add_argument('--phase_train', default=True, type=bool, help='train or test phase flag.')
parser.add_argument('--num_workers', default=0, type=int, help='Number of workers used in dataloading')
parser.add_argument('--use_cuda', default=True, type=bool, help='Use cuda to train model')
parser.add_argument('--resume_epoch', default=0, type=int, help='resume iter for retraining')
parser.add_argument('--save_interval', default=2000, type=int, help='interval for save model state dict')
parser.add_argument('--test_interval', default=2000, type=int, help='interval for evaluate')
parser.add_argument('--momentum', default=0.9, type=float, help='momentum')
parser.add_argument('--weight_decay', default=0.01, type=float, help='Weight decay for SGD')
parser.add_argument('--lr_schedule', default=[4, 8, 12, 14, 16], help='schedule for learning rate.')
parser.add_argument('--save_folder', default='./weights/', help='Location to save checkpoint models')
# parser.add_argument('--pretrained_model', default='./weights/Final_LPRNet_model.pth', help='pretrained base model')
parser.add_argument('--pretrained_model', default='D:/CRNN_CAR_REC/weights'
'/best_ccpd__base_99%.pth', help='pretrained base model')
parser.add_argument("--seed", type=int, default=123)
parser.add_argument("--project_name", type=str, default="车牌识别")
parser.add_argument("--base_dir", type=str, default="C:/Users/lth/Desktop/ccpd/ccpd_base")
parser.add_argument("--resume", type=bool, default=True)
parser.add_argument("--epoches", type=int, default=100)
parser.add_argument("--T_length", type=int, default=18)
parser.add_argument("--accumlate_k",type=int,default=4,help="梯度积累次数")
args = parser.parse_args()
return args
datalist.py
import os
from random import shuffle
import cv2
import numpy as np
from PIL import Image as Img
from torch.utils.data import Dataset
from torchvision import transforms
CHARS = ['京', '沪', '津', '渝', '冀', '晋', '蒙', '辽', '吉', '黑',
'苏', '浙', '皖', '闽', '赣', '鲁', '豫', '鄂', '湘', '粤',
'桂', '琼', '川', '贵', '云', '西', '陕', '甘', '青', '宁',
'新',
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K',
'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V',
'W', 'X', 'Y', 'Z', 'I', 'O', '-'
]
CHARS_DICT = {char: i for i, char in enumerate(CHARS)}
class LPRDataLoader(Dataset):
def __init__(self, train_lines, imgSize, lpr_max_len, PreprocFun=None):
super(LPRDataLoader, self).__init__()
self.train_lines = train_lines
self.img_size = imgSize
self.lpr_max_len = lpr_max_len
if PreprocFun is not None:
self.PreprocFun = PreprocFun
else:
self.PreprocFun = self.transform
def __len__(self):
return len(self.train_lines)
def __getitem__(self, index):
if index == 0:
shuffle(self.train_lines)
n = len(self.train_lines)
index = index % n
img = Img.open(self.train_lines[index])
Image = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2GRAY)
# height, width, _ = Image.shape
height, width= Image.shape
if height != self.img_size[1] or width != self.img_size[0]:
#img size 94x24
Image = cv2.resize(Image, self.img_size)
Image = self.PreprocFun(Image)
# 返回path最后的文件名
basename = os.path.basename(self.train_lines[index])
# 分离文件名与扩展名
imgname, suffix = os.path.splitext(basename)
imgname = imgname.split("-")[0].split("_")[0]
label = list()
for c in imgname:
label.append(CHARS_DICT[c])
# if len(label) == 8:
# if self.check(label) == False:
# print(imgname)
# assert 0, "Error label"
return Image, label, len(label)
def transform(self, img):
# img=transforms.Grayscale()(img)
img = img.astype('float32')
#数据标准化
img -= 127.5
img *= 0.0078125
# img = np.transpose(img, (2, 0, 1))
return img
'''
看不懂,好像是车牌的命名规则
'''
def check(self, label):
if label[2] != CHARS_DICT['D'] and label[2] != CHARS_DICT['F'] \
and label[-1] != CHARS_DICT['D'] and label[-1] != CHARS_DICT['F']:
print("Error label, Please check!")
return False
else:
return True
model.py
import torch
import torch.nn as nn
from tt import SoftPooling3D
class small_basic_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(small_basic_block, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),
nn.ReLU(),
nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),
)
def forward(self, x):
return self.block(x)
class LPRNet(nn.Module):
def __init__(self, lpr_max_len, phase, class_num, dropout_rate):
super(LPRNet, self).__init__()
self.phase = phase
self.lpr_max_len = lpr_max_len
self.class_num = class_num
self.backbone = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1), # 0
nn.BatchNorm2d(num_features=64),
nn.ReLU(), # 2
SoftPooling3D(kernel_size=(1, 3, 3), stride=(1, 1, 1)),
small_basic_block(ch_in=64, ch_out=128), # *** 4 ***
nn.BatchNorm2d(num_features=128),
nn.ReLU(), # 6
SoftPooling3D(kernel_size=(1, 3, 3), stride=(2, 1, 2)),
small_basic_block(ch_in=64, ch_out=256), # 8
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 10
small_basic_block(ch_in=256, ch_out=256), # *** 11 ***
nn.BatchNorm2d(num_features=256), # 12
nn.ReLU(),# 13
SoftPooling3D(kernel_size=(1, 3, 3), stride=(4, 1, 2)), # 14
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(1, 4), stride=1), # 16
nn.BatchNorm2d(num_features=256),
nn.ReLU(), # 18
nn.Dropout(dropout_rate),
nn.Conv2d(in_channels=256, out_channels=class_num, kernel_size=(13, 1), stride=1), # 20
nn.BatchNorm2d(num_features=class_num),
nn.ReLU(), # *** 22 ***
)
self.container = nn.Sequential(
nn.Conv2d(in_channels=704 + self.class_num, out_channels=self.class_num, kernel_size=(1, 1), stride=(1, 1)),
# nn.BatchNorm2d(num_features=self.class_num),
# nn.ReLU(),
# nn.Conv2d(in_channels=self.class_num, out_channels=self.lpr_max_len+1, kernel_size=3, stride=2),
# nn.ReLU(),
)
def forward(self, x):
keep_features = list()
for i, layer in enumerate(self.backbone.children()):
x = layer(x)
if i in [2, 6, 10,13,22]: # [2, 4, 8, 11, 22] [2,6,13,22] 448 [2,6,10,13,22]704
keep_features.append(x)
'''
这里使用了一个global context的trick来炼丹
'''
global_context = list()
for i, f in enumerate(keep_features):
if i in [0, 1]:
f = nn.AvgPool2d(kernel_size=5, stride=5)(f)
if i in [2,3]:
f = nn.AvgPool2d(kernel_size=(4, 10), stride=(4, 2))(f)
f_pow = torch.pow(f, 2)
f_mean = torch.mean(f_pow)
f = torch.div(f, f_mean)
global_context.append(f)
x = torch.cat(global_context, 1)
x = self.container(x)
logits = torch.mean(x, dim=2)
return logits
utils.py
import os
from PIL import Image
'''
数据转换代码
'''
province = {
"皖": 0,
"沪": 1,
"津": 2,
"渝": 3,
"冀": 4,
"晋": 5,
"蒙": 6,
"辽": 7,
"吉": 8,
"黑": 9,
"苏": 10,
"浙": 11,
"京": 12,
"闽": 13,
"赣": 14,
"鲁": 15,
"豫": 16,
"鄂": 17,
"湘": 18,
"粤": 19,
"桂": 20,
"琼": 21,
"川": 22,
"贵": 23,
"云": 24,
"西": 25,
"陕": 26,
"甘": 27,
"青": 28,
"宁": 29,
"新": 30
}
number = {
"A": 0,
"B": 1,
"C": 2,
"D": 3,
"E": 4,
"F": 5,
"G": 6,
"H": 7,
"J": 8,
"K": 9,
"L": 10,
"M": 11,
"N": 12,
"P": 13,
"Q": 14,
"R": 15,
"S": 16,
"T": 17,
"U": 18,
"V": 19,
"W": 20,
"X": 21,
"Y": 22,
"Z": 23,
"0": 24,
"1": 25,
"2": 26,
"3": 27,
"4": 28,
"5": 29,
"6": 30,
"7": 31,
"8": 32,
"9": 33
}
base_path = "E:/Datasets2/CCPD2019/ccpd_green/"
# dirs = ['ccpd_base', 'ccpd_blur', 'ccpd_challenge', 'ccpd_db', 'ccpd_fn', 'ccpd_rotate', 'ccpd_tilt', 'ccpd_weather']
dirs=['test','train','val']
def coord_operation(coord):
left = int(coord[0].split('&')[0])
top = int(coord[0].split('&')[1])
right = int(coord[1].split('&')[0])
bottom = int(coord[1].split('&')[1])
return left, top, right, bottom
def num_operation(num):
name = ''
name += new_province[int(num[0])]
for i in num[1:]:
name += new_number[int(i)]
return name
new_province = {v: k for k, v in province.items()}
new_number = {v: k for k, v in number.items()}
save_path = "E:/car_brand_green/"
count = 0
for dir in dirs:
for img in os.listdir(base_path + dir):
img_str = img
img = img.split('-')
coord = img[2].split('_')
num = img[-3].split('_')
image = Image.open(base_path + dir + '/' + img_str)
image = image.crop((coord_operation(coord)))
if not os.path.exists(save_path + dir):
os.mkdir(save_path + dir)
image.save(save_path + dir + '/' + num_operation(num) + '.jpg')
###################################################################################
train.py
import os
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from config import get_parser
from datalist import LPRDataLoader, CHARS
from model import LPRNet
# 将list转为tensor,这一步也可以直接并到getitem中
def collate_fn(batch):
imgs = []
labels = []
lengths = []
for _, sample in enumerate(batch):
img, label, length = sample
img = torch.from_numpy(img)
# img = img.unsqueeze(dim=0)
imgs.append(img)
labels.extend(label)
lengths.append(length)
labels = np.asarray(labels).flatten().astype(np.int)
return (torch.stack(imgs, 0), torch.from_numpy(labels), lengths)
best_acc = 0
'''
单GPU训练模型
'''
class train():
def __init__(self):
self.args = get_parser()
print(f"-----------{self.args.project_name}-------------")
use_cuda = self.args.use_cuda and torch.cuda.is_available()
if use_cuda:
torch.cuda.manual_seed(self.args.seed)
torch.cuda.manual_seed_all(self.args.seed)
else:
torch.manual_seed(self.args.seed)
self.device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 0, 'pin_memory': True} if use_cuda else {}
'''
构造DataLoader
'''
print("Create DataLoader")
self.lines = self.output_lines(self.args.base_dir)
self.num_val = int(len(self.lines) * 0.3)
self.num_train = len(self.lines) - self.num_val
self.train_dataset = LPRDataLoader(self.lines[:self.num_train], self.args.img_size, self.args.lpr_max_len)
self.test_dataset = LPRDataLoader(self.lines[self.num_train + 1:], self.args.img_size, self.args.lpr_max_len)
self.train_dataloader = DataLoader(self.train_dataset, batch_size=self.args.train_batch_size, **kwargs,
collate_fn=collate_fn)
self.test_dataloader = DataLoader(self.test_dataset, batch_size=self.args.test_batch_size, **kwargs,
collate_fn=collate_fn)
'''
定义模型
'''
print("Create Model")
self.model = LPRNet(lpr_max_len=self.args.lpr_max_len, phase=self.args.phase_train, class_num=len(CHARS),
dropout_rate=self.args.dropout_rate).to(self.device)
'''
根据需要加载与训练模型权重参数
'''
if self.args.resume and self.args.pretrained_model:
data_dict = torch.load(self.args.pretrained_model)
new_data_dict = {}
for k, v in data_dict.items():
new_data_dict[k[7:]] = v
self.model.load_state_dict(new_data_dict, strict=False)
print("load pretrained model successful!")
else:
print("initial net weights from stratch!")
'''
CUDA加速
'''
if use_cuda:
self.model = torch.nn.DataParallel(self.model, device_ids=range(torch.cuda.device_count()))
cudnn.benchmark = True
'''
构造loss目标函数
选择优化器
学习率变化选择
'''
print("Establish the loss, optimizer and learning_rate function")
self.criterion = nn.CTCLoss(blank=len(CHARS) - 1, reduction='mean') # reduction: 'none' | 'mean' | 'sum'
self.optimizer = optim.RMSprop(self.model.parameters(), lr=self.args.learning_rate, alpha=0.9, eps=1e-08,
momentum=self.args.momentum, weight_decay=self.args.weight_decay)
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer, T_max=5, eta_min=1e-6)
'''
模型开始训练
'''
print("start training")
for epoch in range(1, self.args.epoches + 1):
# if epoch % 1 == 0:
# self.test(epoch)
self.train(epoch)
torch.cuda.empty_cache()
print("model finish training")
def train(self, epoch):
self.model.train()
average_loss = []
pbar = tqdm(self.train_dataloader, desc=f'Train Epoch{epoch}/{self.args.epoches}')
for data, target, length in pbar:
data, target = data.to(self.device), target.to(self.device)
self.input_length, self.target_length = self.sparse_tuple_for_ctc(self.args.T_length, length)
self.optimizer.zero_grad()
output = self.model(data)
output_prob = output.permute(2, 0, 1)
output_prob = output_prob.log_softmax(2).requires_grad_()
loss = self.criterion(output_prob, target, input_lengths=self.input_length,
target_lengths=self.target_length)
if loss.item() == np.inf:
continue
loss.backward()
average_loss.append(loss.item())
self.optimizer.step()
pbar.set_description(
f'Train Epoch:{epoch}/{self.args.epoches} train_loss:{round(np.mean(average_loss), 2)} learning_rate:{self.optimizer.state_dict()["param_groups"][0]["lr"]}')
self.scheduler.step()
def test(self, epoch):
global best_acc
Tp = 0
Tn_1 = 0
Tn_2 = 0
# model.eval() disable the dropout and use the population staticatics to make batchnorm
self.model.eval()
pbar = tqdm(self.test_dataloader, desc=f'Test Epoch:{epoch}/{self.args.epoches}', mininterval=0.3)
for images, labels, lengths in pbar:
start = 0
targets = []
for length in lengths:
label = labels[start:start + length]
targets.append(label)
start += length
targets = np.array([el.numpy() for el in targets])
# stop tracing the grad from param to accerlate the computation
with torch.no_grad():
images = images.to(self.device)
# forward
prebs = self.model(images)
# greedy decode
prebs = prebs.cpu().detach().numpy()
preb_labels = list()
for i in range(prebs.shape[0]):
preb = prebs[i, :, :]
preb_label = list()
for j in range(preb.shape[1]):
preb_label.append(np.argmax(preb[:, j], axis=0))
no_repeat_blank_label = list()
pre_c = preb_label[0]
if pre_c != len(CHARS) - 1:
no_repeat_blank_label.append(pre_c)
for c in preb_label: # dropout repeate label and blank label
if (pre_c == c) or (c == len(CHARS) - 1):
if c == len(CHARS) - 1:
pre_c = c
continue
no_repeat_blank_label.append(c)
pre_c = c
preb_labels.append(no_repeat_blank_label)
for i, label in enumerate(preb_labels):
if len(label) != len(targets[i]):
Tn_1 += 1
continue
if (np.asarray(targets[i]) == np.asarray(label)).all():
Tp += 1
else:
Tn_2 += 1
pbar.set_description(
f'Test Epoch:{epoch}/{self.args.epoches} Test Accuracy {Tp * 1.0 / (Tp + Tn_1 + Tn_2)} [{Tp}:{Tn_1}:{Tn_2}:{Tp + Tn_1 + Tn_2}]')
if Tp * 1.0 / (Tp + Tn_1 + Tn_2) > best_acc:
best_acc = Tp * 1.0 / (Tp + Tn_1 + Tn_2)
self.save_model(epoch, best_acc)
def output_lines(self, base_dir):
output = []
for file in os.listdir(base_dir):
for image in os.listdir(base_dir + "/" + file):
output.append(base_dir + '/' + file + '/' + image)
return output
def weights_init(m):
for key in m.state_dict():
if key.split('.')[-1] == 'weight':
if 'conv' in key:
nn.init.kaiming_normal_(m.state_dict()[key], mode='fan_out')
if 'bn' in key:
m.state_dict()[key][...] = nn.init.xavier_uniform(1)
elif key.split('.')[-1] == 'bias':
m.state_dict()[key][...] = 0.01
def sparse_tuple_for_ctc(selff, T_length, lengths):
input_lengths = []
target_lengths = []
for ch in lengths:
input_lengths.append(T_length)
target_lengths.append(ch)
return tuple(input_lengths), tuple(target_lengths)
def save_model(self, epoch, acc):
path = "./weights"
if not os.path.exists(path):
os.mkdir(path)
torch.save({
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
"optimizer_state_dict": self.optimizer.state_dict(),
"accuracy": acc
}, path + '/' + 'Epoch_' + str(epoch) + "_" + 'Acc_' + str(round(acc, 4) * 100) + "%_car_plate_model.pth")
print("save model successful")
if __name__ == "__main__":
Train = train()
trainDDP.py
import os
from contextlib import suppress as nullcontext
import numpy as np
import torch
import torch.distributed as dist
import torch.multiprocessing.spawn as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel.distributed import DistributedDataParallel as DDP
from torch.utils.data import DataLoader
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm
from config import get_parser
from datalist import LPRDataLoader, CHARS
from model import LPRNet
'''
DDP模式,专门用于在单机多GPU的环境下显示,速度块
cmd: python -m torch.distributed.launch --nproc_per_node 4 trainDDP.py
严格注意:使用这个命令的时候,会修改你代码中的args.local_rank,所以一定要确保local_rank写在args里面
'''
# 对batch进行操作,将list转为tensor,这一步也可以直接并到getitem中
def collate_fn(batch):
imgs = []
labels = []
lengths = []
for _, sample in enumerate(batch):
img, label, length = sample
img = torch.from_numpy(img)
img = img.unsqueeze(dim=0)
imgs.append(img)
labels.extend(label)
lengths.append(length)
labels = np.asarray(labels).flatten().astype(np.int)
return (torch.stack(imgs, 0), torch.from_numpy(labels), lengths)
best_acc = 0
class train():
def __init__(self):
self.args = get_parser()
print(f"-----------{self.args.project_name}-------------")
'''
开启DDP模式
'''
local_rank = self.args.local_rank
torch.cuda.set_device(local_rank)
# DDP backend初始化
dist.init_process_group(backend="nccl")
# nccl 是GPU上最快、最推荐的后端,如果是cpu模型,选择其他通信方式
use_cuda = self.args.use_cuda and torch.cuda.is_available()
if use_cuda:
torch.cuda.manual_seed(self.args.seed)
torch.cuda.manual_seed_all(self.args.seed)
else:
torch.manual_seed(self.args.seed)
if use_cuda:
self.device = torch.device('cuda', local_rank)
else:
self.device = torch.device("cpu")
kwargs_train = {'num_workers': 0, 'pin_memory': True} if use_cuda else {}
kwargs_test = {'num_workers': 0, 'pin_memory': False} if use_cuda else {}
'''
构造DataLoader
'''
print("Create DataLoader")
self.lines = self.output_lines(self.args.base_dir)
self.num_val = int(len(self.lines) * 0.3)
self.num_train = len(self.lines) - self.num_val
self.train_dataset = LPRDataLoader(self.lines[:self.num_train], self.args.img_size, self.args.lpr_max_len)
self.test_dataset = LPRDataLoader(self.lines[self.num_train + 1:], self.args.img_size, self.args.lpr_max_len)
# 随机分割数据到各个GPU上,保证数据没有冗余性,也就是各个GPU上训练的数据是被等分之后,没有相互重叠的子数据
self.train_sampler = DistributedSampler(self.train_dataset)
self.test_sampler = DistributedSampler(self.test_dataset)
# 总的total_batch_size=world_size*batch_size,这个数据可以变得相当大
#理论上batch_size越大,对训练结果越好
self.train_dataloader = DataLoader(self.train_dataset, batch_size=self.args.train_batch_size, **kwargs_train,
collate_fn=collate_fn, sampler=self.train_sampler)
self.test_dataloader = DataLoader(self.test_dataset, batch_size=self.args.test_batch_size, **kwargs_test,
collate_fn=collate_fn, sampler=self.test_sampler)
'''
定义模型
'''
print("Create Model")
self.model = LPRNet(lpr_max_len=self.args.lpr_max_len, phase=self.args.phase_train, class_num=len(CHARS),
dropout_rate=self.args.dropout_rate)
# 引入SyncBN,将普通BN替换成SyncBN
self.model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(self.model).to(self.device)
'''
根据需要加载与训练模型权重参数
'''
# DDP: Load模型要在构造DDP模型之前,且只需要在master上加载就行了。
if self.args.resume and self.args.pretrained_model and dist.get_rank() == 0:
data_dict = torch.load(self.args.pretrained_model)["model_state_dict"]
new_data_dict = {}
for k, v in data_dict.items():
new_data_dict[k[7:]] = v
self.model.load_state_dict(new_data_dict, strict=False)
print("load pretrained model successful!")
else:
print("initial net weights from stratch!")
'''
多GPU训练
'''
if torch.cuda.device_count() > 1:
print("Let's use ", torch.cuda.device_count(), " GPUs")
self.model = DDP(self.model, device_ids=[local_rank], output_device=local_rank)
'''
构造loss目标函数
选择优化器
学习率变化选择
'''
print("Establish the loss, optimizer and learning_rate function")
#由于解码器输出和目标字符序列长度不同,我们应用CTC损失方法[20] - 用于无需分割的端到端训练。CTC损失是一种众所周知的方法,用于解决输入和输出序列未对齐且长度可变的情况
self.criterion = nn.CTCLoss(blank=len(CHARS) - 1, reduction='mean') # reduction: 'none' | 'mean' | 'sum'
self.optimizer = optim.RMSprop(self.model.parameters(), lr=self.args.learning_rate, alpha=0.9, eps=1e-08,
momentum=self.args.momentum, weight_decay=self.args.weight_decay)
self.scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(self.optimizer, T_max=5, eta_min=1e-6)
'''
模型开始训练
'''
print("start training")
for epoch in range(1, self.args.epoches + 1):
self.train(epoch)
if epoch % 1 == 0:
self.test(epoch)
torch.cuda.empty_cache()
print("model finish training")
def train(self, epoch):
# 通过epoch来设置每次随机切分的数据的分布,也可以使用其他数据
self.train_dataloader.sampler.set_epoch(epoch)
self.model.train()
average_loss = []
count_accumlate = 0
pbar = tqdm(self.train_dataloader, desc=f'Train Epoch{epoch}/{self.args.epoches}')
for data, target, length in pbar:
count_accumlate += 1
data, target = data.to(self.device), target.to(self.device)
self.optimizer.zero_grad() # 训练之前,梯度清0
self.input_length, self.target_length = self.sparse_tuple_for_ctc(self.args.T_length, length)
# 使用梯度积累---一种增大训练时batch size
context = self.model.no_sync if self.args.local_rank != -1 and count_accumlate % self.args.accmulate_k != 0 else nullcontext
with context():
output = self.model(data)
output_prob = output.permute(2, 0, 1)
output_prob = output_prob.log_softmax(2).requires_grad_()
loss = self.criterion(output_prob, target, input_lengths=self.input_length,
target_lengths=self.target_length)
if loss.item() == np.inf:
continue
if count_accumlate % self.args.accmulate_k == 0:
loss.backward()
average_loss.append(loss.item()) # GPU到CPU的数据转换
self.optimizer.step()
pbar.set_description(
f'Train Epoch:{epoch}/{self.args.epoches} train_loss:{round(np.mean(average_loss), 2)} learning_rate:{self.optimizer.state_dict()["param_groups"][0]["lr"]}')
self.scheduler.step()
def test(self, epoch):
global best_acc
self.test_dataloader.sampler.set_epoch(epoch)
Tp = 0
Tn_1 = 0
Tn_2 = 0
# model.eval() disable the dropout and use the population staticatics to make batchnorm
self.model.eval()
pbar = tqdm(self.test_dataloader, desc=f'Test Epoch:{epoch}/{self.args.epoches}', mininterval=0.3)
for images, labels, lengths in pbar:
start = 0
targets = []
for length in lengths:
label = labels[start:start + length]
targets.append(label)
start += length
targets = np.array([el.numpy() for el in targets])
# stop tracing the grad from param to accerlate the computation
with torch.no_grad():
images = images.to(self.device)
# forward
prebs = self.model(images)
# greedy decode
prebs = prebs.cpu().detach().numpy()
preb_labels = list()
for i in range(prebs.shape[0]):
preb = prebs[i, :, :]
preb_label = list()
for j in range(preb.shape[1]):
preb_label.append(np.argmax(preb[:, j], axis=0))
no_repeat_blank_label = list()
pre_c = preb_label[0]
if pre_c != len(CHARS) - 1:
no_repeat_blank_label.append(pre_c)
for c in preb_label: # dropout repeate label and blank label
if (pre_c == c) or (c == len(CHARS) - 1):
if c == len(CHARS) - 1:
pre_c = c
continue
no_repeat_blank_label.append(c)
pre_c = c
preb_labels.append(no_repeat_blank_label)
for i, label in enumerate(preb_labels):
if len(label) != len(targets[i]):
Tn_1 += 1
continue
if (np.asarray(targets[i]) == np.asarray(label)).all():
Tp += 1
else:
Tn_2 += 1
pbar.set_description(
f'Test Epoch:{epoch}/{self.args.epoches} Test Accuracy {Tp * 1.0 / (Tp + Tn_1 + Tn_2)} [{Tp}:{Tn_1}:{Tn_2}:{Tp + Tn_1 + Tn_2}]')
if Tp * 1.0 / (Tp + Tn_1 + Tn_2) > best_acc:
best_acc = Tp * 1.0 / (Tp + Tn_1 + Tn_2)
self.save_model(epoch, best_acc)
def output_lines(self, base_dir):
output = []
for file in os.listdir(base_dir):
for image in os.listdir(base_dir + "/" + file):
output.append(base_dir + '/' + file + '/' + image)
return output
def weights_init(m): # 模型从stratch开始训练时的权重参数初始化
for key in m.state_dict():
if key.split('.')[-1] == 'weight':
if 'conv' in key:
nn.init.kaiming_normal_(m.state_dict()[key], mode='fan_out')
if 'bn' in key:
m.state_dict()[key][...] = nn.init.xavier_uniform(1)
elif key.split('.')[-1] == 'bias':
m.state_dict()[key][...] = 0.01
def sparse_tuple_for_ctc(selff, T_length, lengths):
input_lengths = []
target_lengths = []
for ch in lengths:
input_lengths.append(T_length)
target_lengths.append(ch)
return tuple(input_lengths), tuple(target_lengths)
def save_model(self, epoch, acc):
path = "/weights"
if not os.path.exists(path):
os.mkdir(path)
# save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model
# 限制成主机保存模型
if dist.get_rank() == 0:
torch.save({
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
"optimizer_state_dict": self.optimizer.state_dict(),
"accuracy": acc
}, path + '/' + 'Epoch_' + str(epoch) + "_" + 'Acc_' + str(round(acc, 4) * 100) + "%_car_plate_model.pth")
print("save model successful")
#
# def run(train, world_size):
# mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
if __name__ == "__main__":
run(train=train(), world_size=4)
最后
这个是我从github上仿下来的lprnet,在这里多了一点新的内容,我强调了DDP模式下的训练,在这里我用的是ccpd数据集差不多30多万张,如果按照我上面那个train的话,要多久啊。后来经同事提点,开始觉得DDP这玩意真牛逼,在v100的机子上,这么大量的数据集用半天就能跑出效果。效果如下:
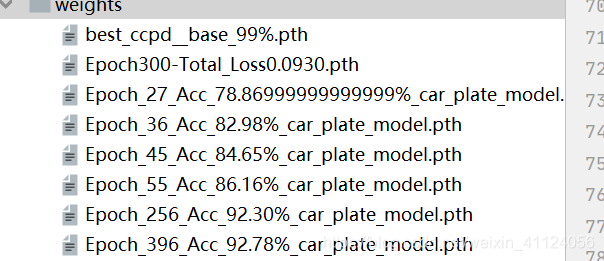
基本是一个很理想的状态了,关键是速度还贼快。
这里另外在utils中加入了关于数据集制作的方法,很简单。
最后再补充一下,我再这里使用了softpool和globaltext两个小trick,本来以为是涨点神器,但感觉用了跟没有用是差不多的。另外值得一提,这个算法对于初学者来说是非常有价值的,不仅体积小训练快,比用mnist学习更有实际意义。

















 5616
5616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









