



一、DeepLab V1
1、结构:
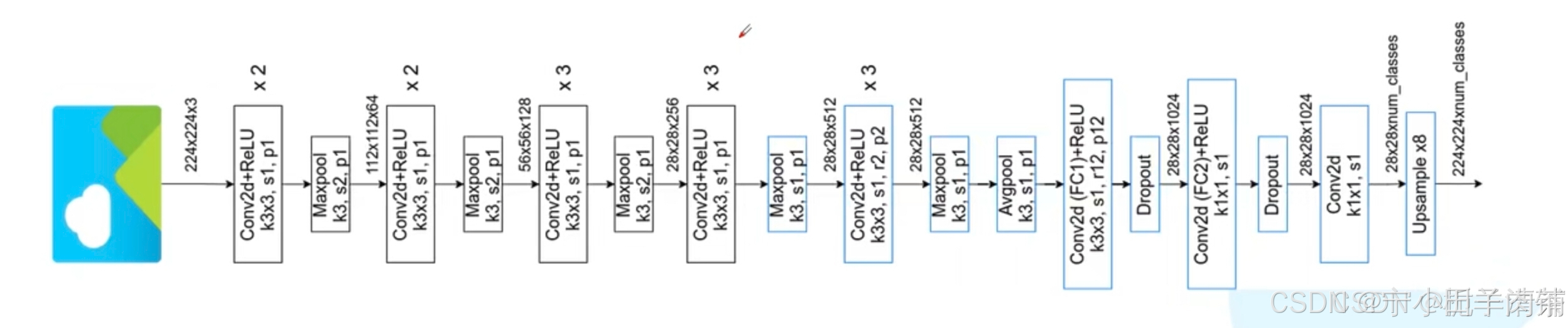
DeepLab V1使用了卷积神经网络(CNN)与条件随机场(CRF)的组合来实现图像的语义分割,前面部分主要是跟vgg的结构差不多的。具体而言,它通过标准的卷积神经网络进行特征提取,然后在最后的DCNN层输出结果上结合一个全连接的CRF,增强分割边界的精细度。
2、优点:
边界精细度提升:CRF的加入显著提升了边界的精确度,使得分割结果在边界处更为清晰。
计算效率:通过引入“洞(Atrous)算法”,有效地减少了计算量,使得特征提取过程更加高效(DeeplabV1)。
3、缺点:
多尺度处理不足:V1主要依赖于单一的特征尺度,处理不同大小物体的能力有限。
对全局上下文缺乏处理:仅使用CRF和CNN组合,缺乏对全局上下文信息的进一步利用(DeeplabV1)。
二、DeepLab V2
1、结构
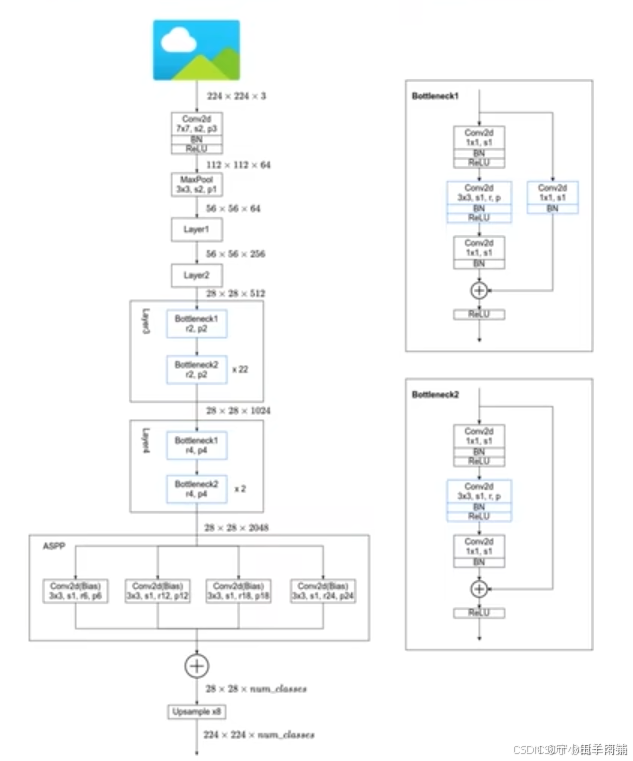
在V2中,引入了“空洞空间金字塔池化(ASPP)”模块,前面部分主要是跟resnet的结构差不多的。ASPP模块在不同采样率下对特征进行卷积,使得模型可以更好地捕获多尺度的信息。同时,CRF也继续被用于改善边界细节(DeeplabV2)。
2、优点:
多尺度分割能力增强:ASPP模块可以在不同尺度上处理特征,使得模型在处理不同大小的目标时表现更好。
边界细节进一步优化:继续使用CRF作为后处理步骤,进一步优化边界分割(DeeplabV2)。
3、缺点:
复杂度增加:ASPP模块引入了多个并行卷积,虽然提升了多尺度处理能力,但也增加了模型的复杂度和计算量。
依赖CRF进行后处理:依赖于CRF来增强边界分割的精确度,增加了后处理的时间(DeeplabV2)。
三、DeepLab V3
1、结构:
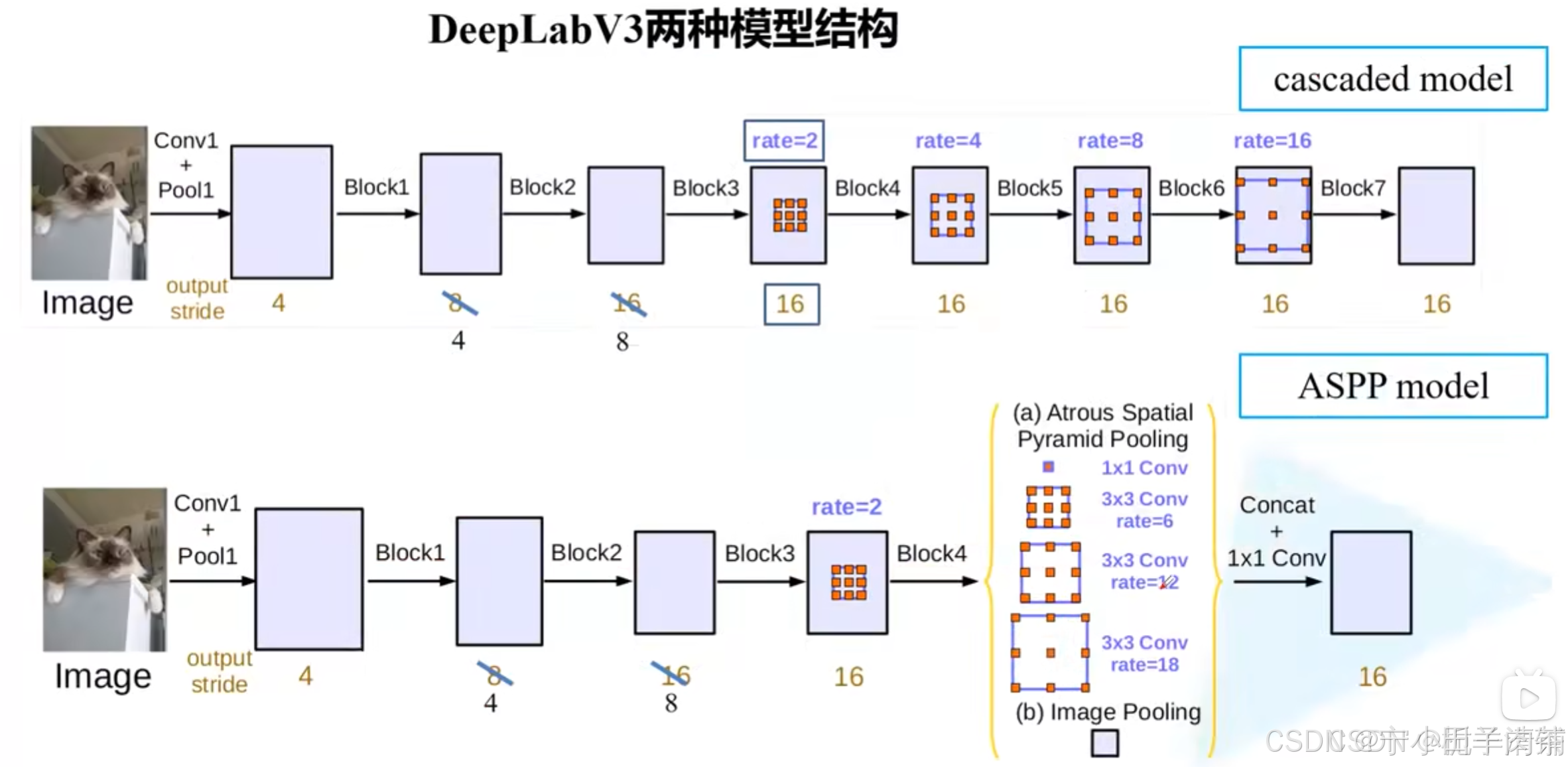
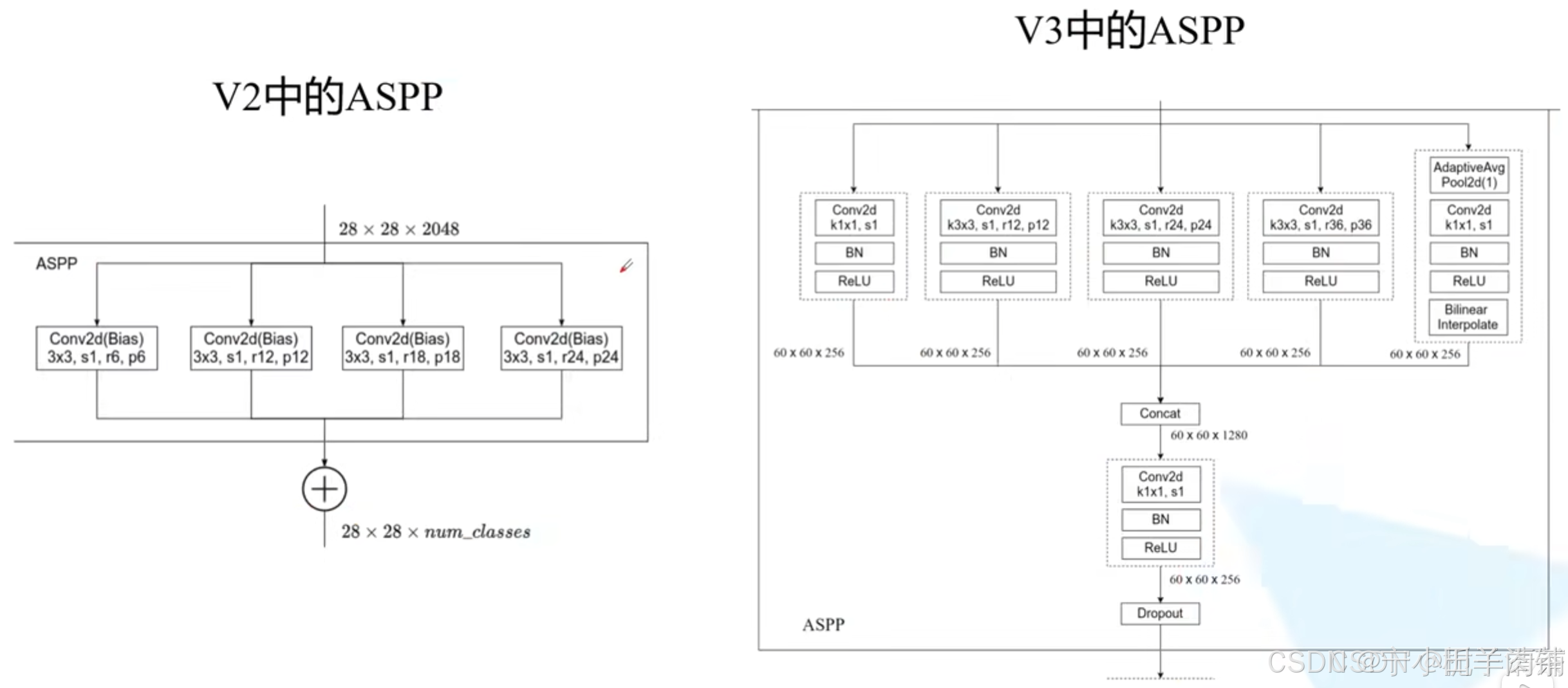
DeepLab V3进一步改进了ASPP模块,引入了更多的卷积率(rate)来扩展感受野,同时增加了全局图像特征(image-level features),不再依赖CRF作为后处理。DeepLab V3通过并行的ASPP和全局图像特征来捕获多尺度信息和全局上下文(DeeplabV3)。
2、优点:
全局和多尺度信息结合:增加了全局特征,使得模型可以更好地理解整体场景,提升分割精确度。
摆脱CRF依赖:去掉了CRF后处理,直接输出分割结果,使得模型更高效。
性能进一步提升:在多个数据集上实现了更高的分割精度(DeeplabV3)。
3、缺点:
对更高分辨率特征要求较高:在高分辨率特征处理下对内存和计算资源要求增加。
对超参数敏感:特别是在不同的图像尺度下,需要对不同的空洞卷积率进行调优(DeeplabV3)。
四、三个版本之间的关系
结构演进:每一代都在前一代的基础上优化,V1的核心是CNN+CRF组合,V2在此基础上加入了ASPP模块提升多尺度特征处理能力,而V3进一步优化ASPP并加入了全局图像特征以替代CRF。
多尺度处理能力增强:从V1到V3,模型逐步提升了多尺度分割的能力,特别是在V3中通过ASPP和全局特征的结合,实现了更强的多尺度和上下文信息处理。
精细化的边界分割处理:V1和V2依赖CRF来增强边界处理,而V3通过多尺度空洞卷积与全局特征融合,摆脱了CRF的依赖,且实现了更高效的边界分割(DeeplabV1)(DeeplabV2)(DeeplabV3)。
总结
DeepLab系列模型在每一代都逐步增强了多尺度处理能力和全局上下文的理解。V1适合于基础的分割任务,V2在多尺度和边界优化上有所突破,而V3则进一步摆脱了后处理步骤,通过ASPP和全局特征的结合达到了较高的性能。
1、DeepLab V1
其他图像分割模型如FCN和U-Net都使用了反卷积和pooling保持分别率不变,而只使用空洞卷积就可以实现反卷积和pooling的效果,而且空洞卷积还具有可学习的优点。
1.1 基于VGG模型
1、以VGG模型为基础,因为想利用VGG模型预训练的参数;
2、去除掉最后2个max pooling,并使用空洞卷积保持感受野一致,空洞卷积使用在原VGG模型最后2个max pooling之间;
3、最后3个FC层都换成3×3的卷积,所以输出feature size为28×28;
4、第3步使用3×3 的卷积输出的通道数换成1024,不影响效果而且也增加速度;
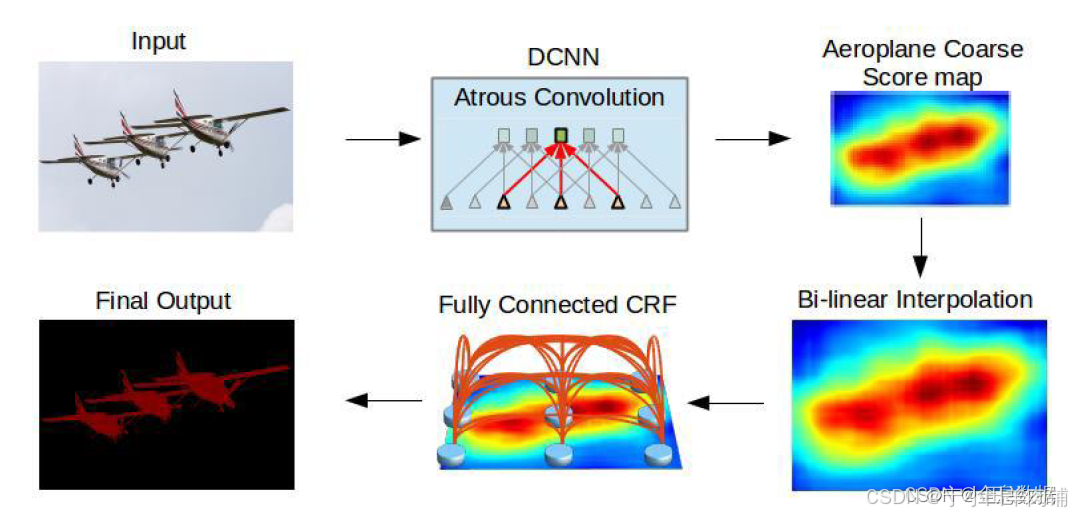
1.2 总体架构
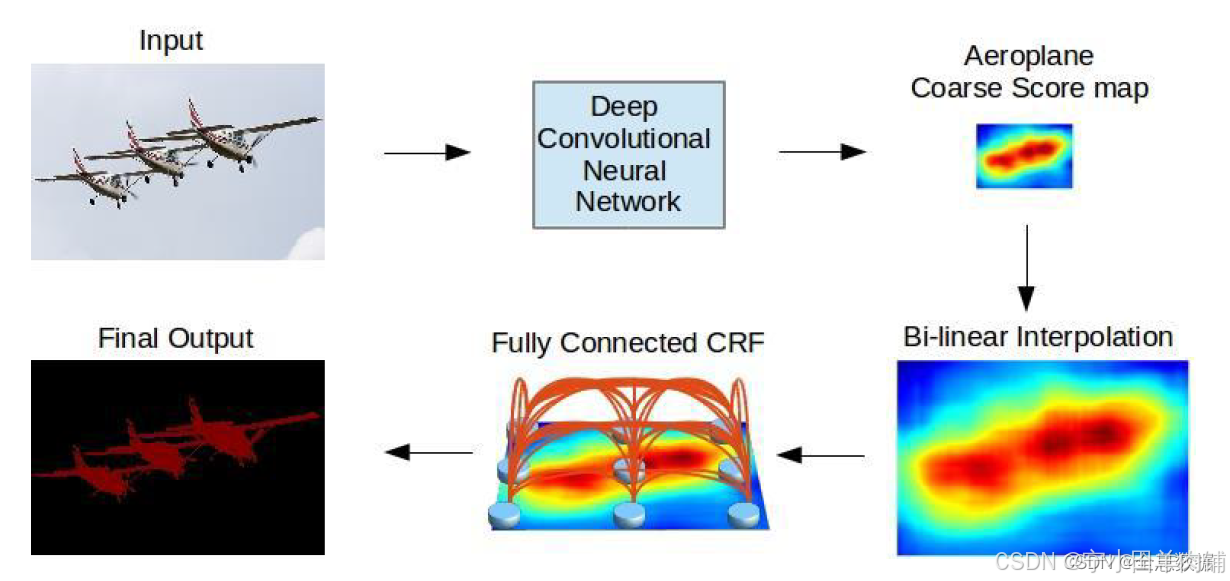
1、基于VGG模型修改的结构在上图的第一行已完成;
2、第四步是对基于VGG修改模型输出的结果进行双线性插值,增加8倍还原成原feature size的大小;
3、使用了Fully Connected CRF(条件随机场)
1.2.1 Fully Connected CRF(条件随机场)
公式: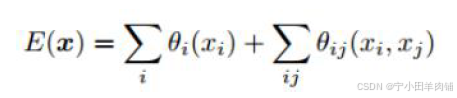
其中:
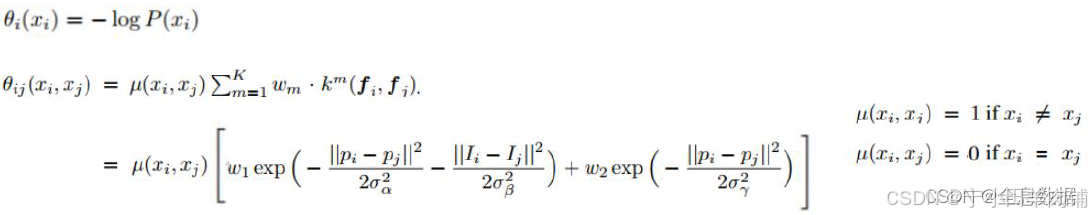

1.3 DeepLab V1模型实验
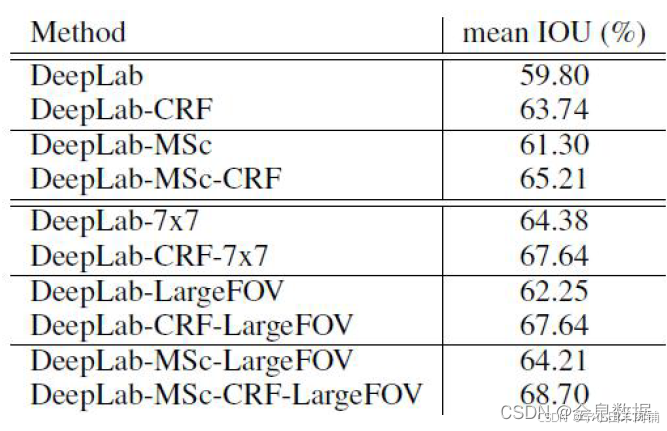
总结:
1、增加CRF、通过设置较大的dilation增加感受野、以及多尺度输入可增加模型的效果;
2、所以根据上面所做的增加模型效果的实验,就诞生了DeepLab V2。

总结:
根据第一行和最后一行可知:在3*3的kernel size下,增加stride可增加模型的效果,而且还减少了参数量。
2、DeepLab V2
与V1版本的区别就是引入了ASPP,结合V1所做的实验,增加多尺度训练和较大的感受野可增加mIOU;
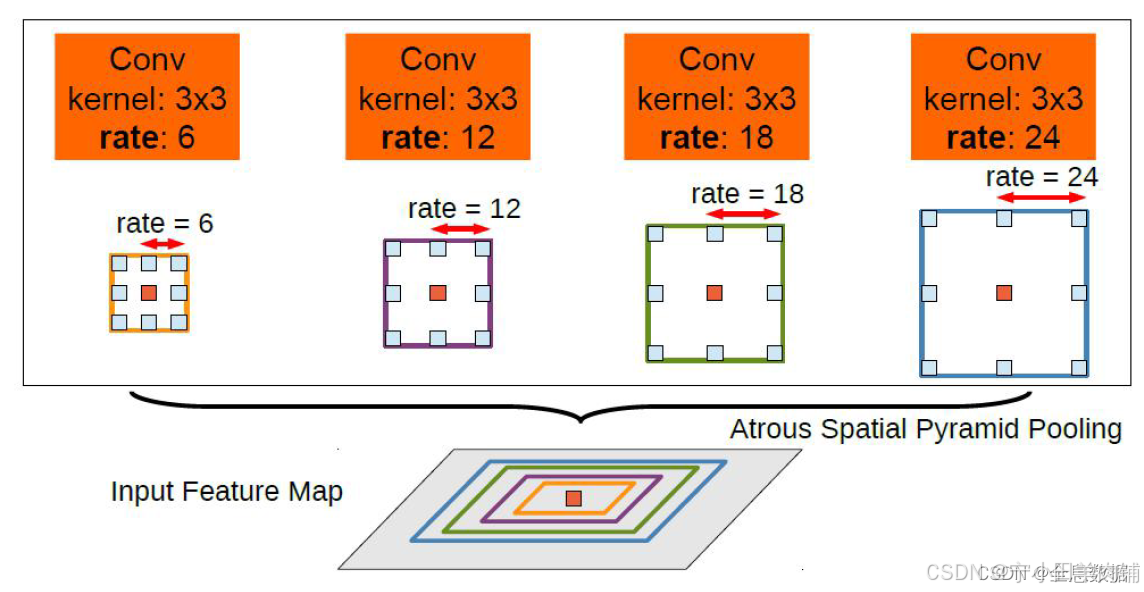
步骤:
1、对输入的feature map进行分组空洞卷积,rate为(6,12,18,24),此对应多尺度输入;
2、通过padding,使各个组输出的feature size与输入相同;
3、对各个组输出的feature map进行sum;
ASPP code:
import torch
from torch._C import Size
import torch.nn as nn
import torch.nn.functional as F
class ASPP(nn.Module):
"""
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling)在给定的输入上以不同采样率(dilation)的空洞卷积
并行采样,相当于以多个比例捕捉图像的上下文。
"""
def __init__(self, in_chans, out_chans, rate=1):
super(ASPP, self).__init__()
# 以不同的采样率预制空洞卷积(通过调整dilation实现)
# 1x1卷积——无空洞
self.branch1 = nn.Sequential(
nn.Conv2d(in_chans, out_chans, 1, 1, padding=0, dilation=rate, bias=True),
nn.BatchNorm2d(out_chans),
nn.ReLU(inplace=True)
)
# 3x3卷积——空洞6
self.branch2 = nn.Sequential(
nn.Conv2d(in_chans, out_chans, 3, 1, padding=6 * rate, dilation=6 * rate, bias=True),
nn.BatchNorm2d(out_chans),
nn.ReLU(inplace=True)
)
# 3x3卷积——空洞12
self.branch3 = nn.Sequential(
nn.Conv2d(in_chans, out_chans, 3, 1, padding=12 * rate, dilation=12 * rate, bias=True),
nn.BatchNorm2d(out_chans),
nn.ReLU(inplace=True)
)
# 3x3卷积——空洞18
self.branch4 = nn.Sequential(
nn.Conv2d(in_chans, out_chans, 3, 1, padding=18 * rate, dilation=18 * rate, bias=True),
nn.BatchNorm2d(out_chans),
nn.ReLU(inplace=True)
)
# 全局平均池化——获取图像层级特征,image pooling,
self.branch5_avg = nn.AdaptiveAvgPool2d(1) # 1:输出为1*1
# 1x1的conv、bn、relu——用于处理平均池化所得的特征图
self.branch5_conv = nn.Conv2d(in_chans, out_chans, 1, 1, 0, bias=True)
self.branch5_bn = nn.BatchNorm2d(out_chans)
self.branch5_relu = nn.ReLU(inplace=True)
# 1x1的conv、bn、relu——用于处理concat所得的特征图
self.conv_cat = nn.Sequential(
nn.Conv2d(out_chans * 5, out_chans, 1, 1, padding=0, bias=True),
nn.BatchNorm2d(out_chans),
nn.ReLU(inplace=True)
)
def forward(self, x):
# 获取size——用于上采样的时候确定上采样到多大
b, c, h, w = x.size()
# 一个1x1的卷积
conv1x1 = self.branch1(x)
# 三个3x3的空洞卷积
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
# 一个平均池化
global_feature = self.branch5_avg(x)
# 对平均池化所得的特征图进行处理
global_feature = self.branch5_relu(self.branch5_bn(self.branch5_conv(global_feature)))
# 将平均池化+卷积处理后的特征图上采样到原始x的输入大小
global_feature = F.interpolate(global_feature, (h, w), None, 'bilinear', True)
# 把所有特征图cat在一起(包括1x1、三组3x3、平均池化+1x1),cat通道的维度
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
# 最后再连一个1x1卷积,把cat翻了5倍之后的通道数缩减回来
result = self.conv_cat(feature_cat)
return result
2.1 整体架构
2.2 训练策略
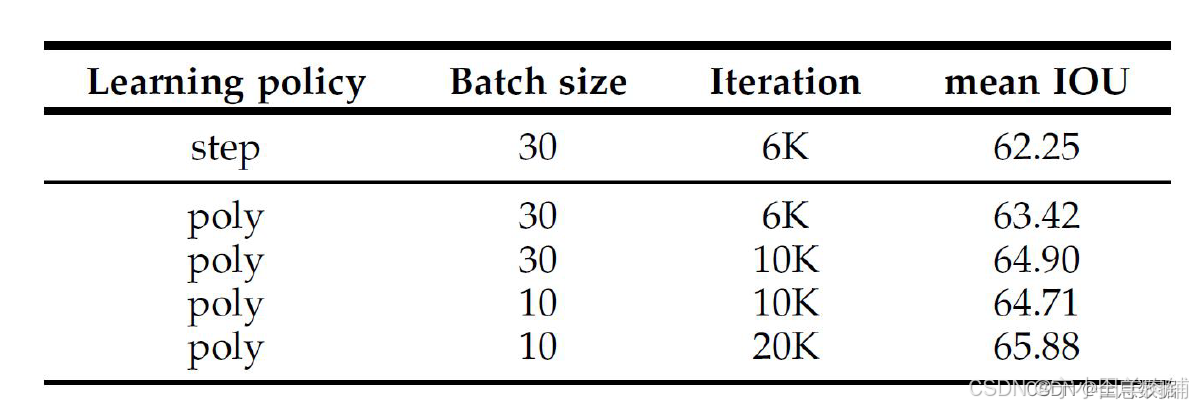
总结:
通过调小batch size和增加训练的epoch可增加mIOU。
2.2.1 学习率的调整
随着训练epoch的增加,学习率应作适当减小,所以V2提出新的学习率的策略,公式为:
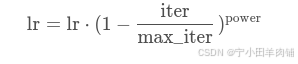
其中原论文 p o w e r power power设置的是:0.9;
3、DeepLab V3
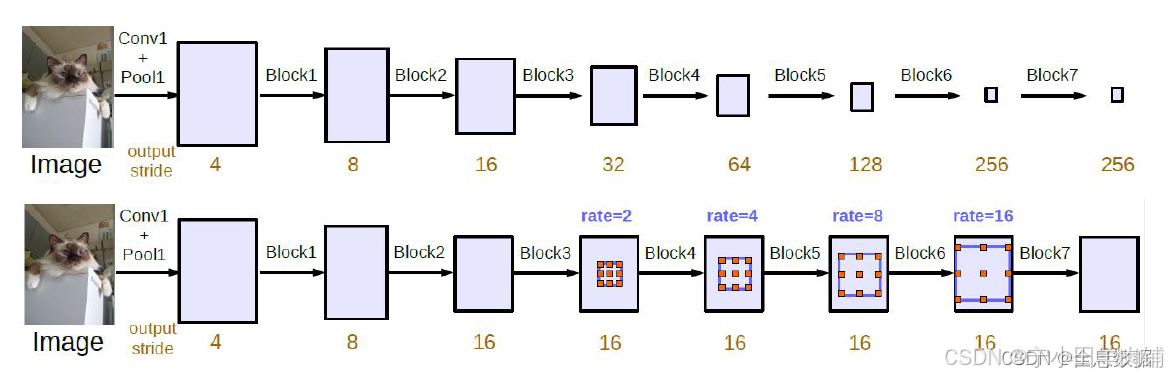
DeepLab V3有cascade和parallel两种的形式,先介绍cascade;
3.1 cascade形式的DeepLab V3

3.2 parallel形式的DeepLab V3
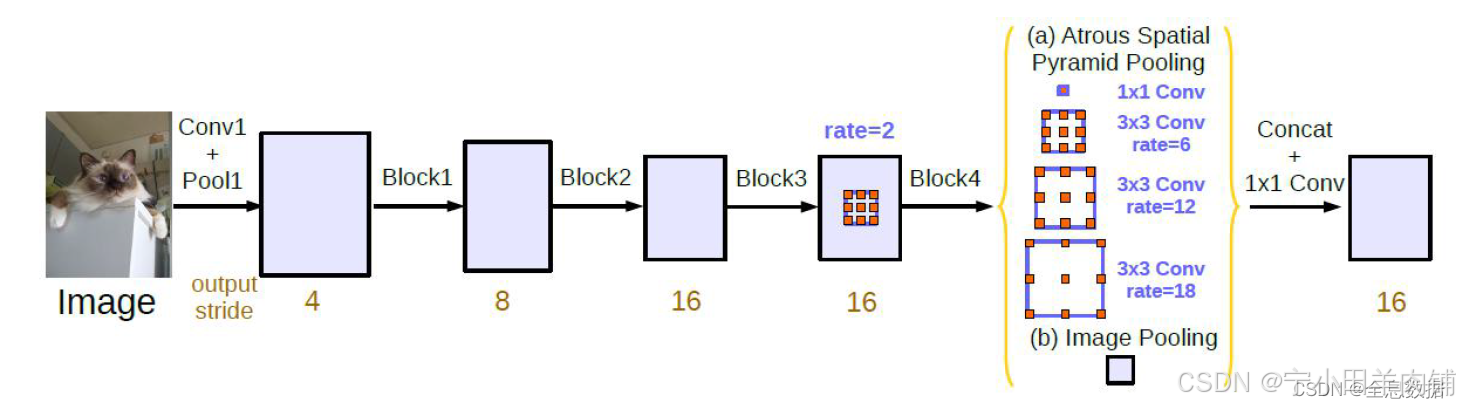
因为在cascade模型中,网络做的太深效果反而出现下降,所以就引用了ASPP。
4、DeepLab V3+
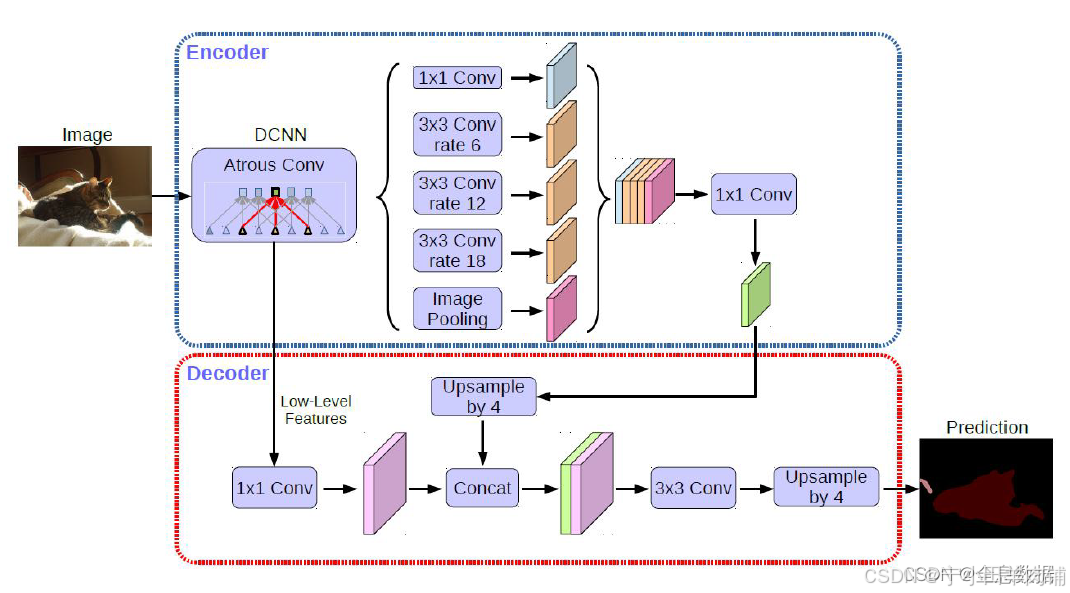
改进点:
1、借鉴了Encode和Decode的结合,进行了特征的concat;
2、使用了Modified Xception;
3、使用了深度可分离空洞卷积(Depthwise Separable Convolution);
4.1 深度可分离空洞卷积


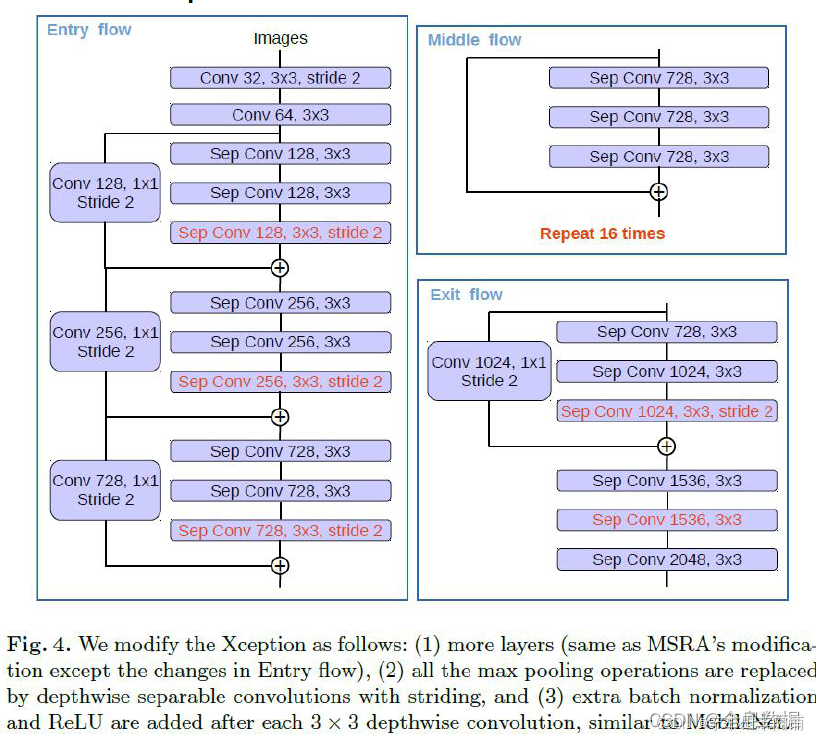
总结:
1、类似于resnet,但与resnet有很大的不同;
2、Modified Xception使用了Depthwise Separable Convolution;
DeepLab V3+ 代码:
"""
Attention:需要把上一个ASPP的代码和当前的代码放在同一目录下
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as model_zoo
bn_mom = 0.0003
# 预先训练模型地址
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth'
}
# same空洞卷积
# 对于k=3的卷积,通过设定padding=1*atrous,保证添加空洞后的3x3卷积,输入输出feature map同样大小
def conv3x3(in_planes, out_planes, stride=1, atrous=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1 * atrous, dilation=atrous, bias=False)
# 通过 same 空洞卷积实现BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_chans, out_chans, stride=1, atrous=1, downsample=None):
super(BasicBlock, self).__init__()
# 使用自定义的same 空洞卷积
self.conv1 = conv3x3(in_chans, out_chans, stride, atrous)
self.bn1 = nn.BatchNorm2d(out_chans)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_chans, out_chans)
self.bn2 = nn.BatchNorm2d(out_chans)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# 实现带有空洞卷积的Bottleneck
# 这个bottleneck结构,
# 在resnet 50的block1中串连使用了3个,block2中串连使用了4个,block3中串连使用了6个,block4中串连使用了3个。
# 在resnet 101的block1中串连使用了3个,block2中串连使用了4个,block3中串连使用了24个,block4中串连使用了3个。
# 在resnet 152的block1中串连使用了3个,block2中串连使用了8个,block3中串连使用了36个,block4中串连使用了3个。
# 所以,当我们定block1,block2,block3,block4分别为[3,4,6,3]时,就对应resnet50
# 所以,当我们定block1,block2,block3,block4分别为[3,4,24,3]时,就对应resnet101
# 所以,当我们定block1,block2,block3,block4分别为[3,8,36,3]时,就对应resnet152
class Bottleneck(nn.Module):
# bottleneck block中,有三个卷积层,分别是:C1:1x1conv,C2:3x3conv,C3:1x1conv
# C1的输入featue map 的channel=4C,输处feature map 的channel=C
# C2的输入featue map 的channel=C,输处feature map 的channel=C
# C3的输入featue map 的channel=C,输处feature map 的channel=4C
# expansion:定义瓶颈处的feature map,C2的输入输出feature map 的 channel是非瓶颈处的channel的1/4
expansion = 4
def __init__(self, in_chans, out_chans, stride=1, atrous=1, downsample=None):
super(Bottleneck, self).__init__()
# 这里in_chans是out_chans的4倍,在make_layer函数里有实现,大概在本代码164行左右
self.conv1 = nn.Conv2d(in_chans, out_chans, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_chans)
# same空洞卷积
self.conv2 = nn.Conv2d(out_chans, out_chans, kernel_size=3, stride=stride,
padding=1 * atrous, dilation=atrous, bias=False)
self.bn2 = nn.BatchNorm2d(out_chans)
self.conv3 = nn.Conv2d(out_chans, out_chans * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_chans * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# 定义完整的空洞残差网络
class ResNet_Atrous(nn.Module):
# 当layers=[3,4,6,3]时,block为bottlenet时,就生成resnet50
def __init__(self, block, layers, atrous=None, os=16):
super(ResNet_Atrous, self).__init__()
self.block = block
stride_list = None
if os == 8:
# 控制block2,block3,block4的第一个bottleneck的3x3卷积的stride
# 这里指将block2内的第一个bottleneck的3x3卷集的stride设置为2
# 这里指将block3内的第一个bottleneck的3x3卷集的stride设置为1
# 这里指将block4内的第一个bottleneck的3x3卷集的stride设置为1
stride_list = [2, 1, 1]
elif os == 16:
stride_list = [2, 2, 1]
else:
raise ValueError('resnet_atrous.py: output stride=%d is not supported.' % os)
self.inplanes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# resnet的 block1
self.layer1 = self._make_layer(block, 64, 64, layers[0])
# resnet的 block2
self.layer2 = self._make_layer(block, 64 * block.expansion, 128, layers[1], stride=stride_list[0])
# resnet的 block3
self.layer3 = self._make_layer(block, 128 * block.expansion, 256, layers[2], stride=stride_list[1],
atrous=16 // os)
# resnet的 block4,block4的atrous为列表,里面使用了multi-grid技术
self.layer4 = self._make_layer(block, 256 * block.expansion, 512, layers[3], stride=stride_list[2],
atrous=[item * 16 // os for item in atrous])
self.layer5 = self._make_layer(block, 512 * block.expansion, 512, layers[3], stride=1,
atrous=[item * 16 // os for item in atrous])
self.layer6 = self._make_layer(block, 512 * block.expansion, 512, layers[3], stride=1,
atrous=[item * 16 // os for item in atrous])
self.layers = []
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, in_chans, out_chans, blocks, stride=1, atrous=None):
downsample = None
if atrous == None:
# 当没有设置atrous,blocks=3时,atrous=[1,1,1]
# 此时表示resnet的block1,或者block2,或者block3,或者block4内的bottleneck中的3x3卷积的膨胀系数为1,
# 膨胀系数为1,就表示没有膨胀,还是标准卷积。
atrous = [1] * blocks
elif isinstance(atrous, int):
# 当设置atrous=2,blocks=3时,atrous=[2,2,2]
# 此时表示resnet的block1,或者block2,或者block3,或者block4内的bottleneck中的3x3卷积的膨胀系数为2
atrous_list = [atrous] * blocks
atrous = atrous_list
# 如果atrous不是None,也不是一个整数,那么atrous被直接设定为[1,2,3]
# 此时表示resnet的block1,或者block2,或者block3,或者block4内的bottleneck中的3个3x3卷积的膨胀系数分别为[1,2,3]
if stride != 1 or in_chans != out_chans * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(in_chans, out_chans * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_chans * block.expansion),
)
layers = []
layers.append(block(in_chans, out_chans, stride=stride, atrous=atrous[0], downsample=downsample))
in_chans = out_chans * block.expansion
for i in range(1, blocks):
layers.append(block(in_chans, out_chans, stride=1, atrous=atrous[i]))
return nn.Sequential(*layers)
def forward(self, x):
layers_list = []
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
# 此时x为4倍下采样
layers_list.append(x)
x = self.layer2(x)
# 此时x为8倍下采样
layers_list.append(x)
x = self.layer3(x)
# 此时x为8倍或者16倍下采样,由本代码的123,125行的 stride_list决定
# stride_list[2,1,1]时,就是8倍下采样
# stride_list[2,2,1]时,就是16倍下采样
layers_list.append(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.layer6(x)
# 此时x为8倍或者16倍下采样,由本代码的123,125行的 stride_list决定
# stride_list[2,1,1]时,就是8倍下采样
# stride_list[2,2,1]时,就是16倍下采样
layers_list.append(x)
# return 4个feature map,分别是block1,block2,block3,block6的feature map
return layers_list
def resnet34_atrous(pretrained=True, os=16, **kwargs):
"""Constructs a atrous ResNet-34 model."""
model = ResNet_Atrous(BasicBlock, [3, 4, 6, 3], atrous=[1, 2, 1], os=os, **kwargs)
if pretrained:
old_dict = model_zoo.load_url(model_urls['resnet34'])
model_dict = model.state_dict()
old_dict = {k: v for k, v in old_dict.items() if (k in model_dict)}
model_dict.update(old_dict)
model.load_state_dict(model_dict)
return model
def resnet50_atrous(pretrained=True, os=16, **kwargs):
"""Constructs a atrous ResNet-50 model."""
model = ResNet_Atrous(Bottleneck, [3, 4, 6, 3], atrous=[1, 2, 1], os=os, **kwargs)
if pretrained:
old_dict = model_zoo.load_url(model_urls['resnet50'])
model_dict = model.state_dict()
old_dict = {k: v for k, v in old_dict.items() if (k in model_dict)}
model_dict.update(old_dict)
model.load_state_dict(model_dict)
return model
def resnet101_atrous(pretrained=True, os=16, **kwargs):
"""Constructs a atrous ResNet-101 model."""
model = ResNet_Atrous(Bottleneck, [3, 4, 23, 3], atrous=[1, 2, 1], os=os, **kwargs)
if pretrained:
old_dict = model_zoo.load_url(model_urls['resnet101'])
model_dict = model.state_dict()
old_dict = {k: v for k, v in old_dict.items() if (k in model_dict)}
model_dict.update(old_dict)
model.load_state_dict(model_dict)
return model
from aspp import ASPP
class Config(object):
# 决定本代码的123,125行的 stride_list的取值
OUTPUT_STRIDE = 16
# 设定ASPP模块输出的channel数
ASPP_OUTDIM = 256
# Decoder中,shortcut的1x1卷积的channel数目
SHORTCUT_DIM = 48
# Decoder中,shortcut的卷积的核大小
SHORTCUT_KERNEL = 1
# 每个像素要被分类的类别数
NUM_CLASSES = 21
class DeeplabV3Plus(nn.Module):
def __init__(self, cfg, backbone=resnet50_atrous):
super(DeeplabV3Plus, self).__init__()
self.backbone = backbone(pretrained=False, os=cfg.OUTPUT_STRIDE)
input_channel = 512 * self.backbone.block.expansion
self.aspp = ASPP(in_chans=input_channel, out_chans=cfg.ASPP_OUTDIM, rate=16 // cfg.OUTPUT_STRIDE)
self.dropout1 = nn.Dropout(0.5)
self.upsample4 = nn.UpsamplingBilinear2d(scale_factor=4)
self.upsample_sub = nn.UpsamplingBilinear2d(scale_factor=cfg.OUTPUT_STRIDE // 4)
indim = 64 * self.backbone.block.expansion
self.shortcut_conv = nn.Sequential(
nn.Conv2d(indim, cfg.SHORTCUT_DIM, cfg.SHORTCUT_KERNEL, 1, padding=cfg.SHORTCUT_KERNEL // 2, bias=False),
nn.BatchNorm2d(cfg.SHORTCUT_DIM),
nn.ReLU(inplace=True),
)
self.cat_conv = nn.Sequential(
nn.Conv2d(cfg.ASPP_OUTDIM + cfg.SHORTCUT_DIM, cfg.ASPP_OUTDIM, 3, 1, padding=1, bias=False),
nn.BatchNorm2d(cfg.ASPP_OUTDIM),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(cfg.ASPP_OUTDIM, cfg.ASPP_OUTDIM, 3, 1, padding=1, bias=False),
nn.BatchNorm2d(cfg.ASPP_OUTDIM),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(cfg.ASPP_OUTDIM, cfg.NUM_CLASSES, 1, 1, padding=0)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
# 利用backbone生成block1,2,3,4,5,6,7的feature maps
layers = self.backbone(x)
# layers[-1]是block7输出的feature map相对于原图下采样了16倍
# 把block7的输出送入aspp
feature_aspp = self.aspp(layers[-1])
feature_aspp = self.dropout1(feature_aspp)
# 双线行插值上采样4倍
feature_aspp = self.upsample_sub(feature_aspp)
# layers[0],是block1输出的featuremap,相对于原图下采样的4倍,我们将它送入1x1x48的卷积中
feature_shallow = self.shortcut_conv(layers[0])
# aspp上采样4倍,变成相对于原图下采样4倍,与featue _shallow 拼接融合
feature_cat = torch.cat([feature_aspp, feature_shallow], 1)
result = self.cat_conv(feature_cat)
result = self.cls_conv(result)
result = self.upsample4(result)
return result
cfg = Config()
model = DeeplabV3Plus(cfg, backbone=resnet50_atrous)
x = torch.randn((2, 3, 128, 128), dtype=torch.float32)
y = model(x)
print(y.shape)
语义分割之FCN、Deeplab V3+
1、相关参考链接
最新论文:
LEDNet
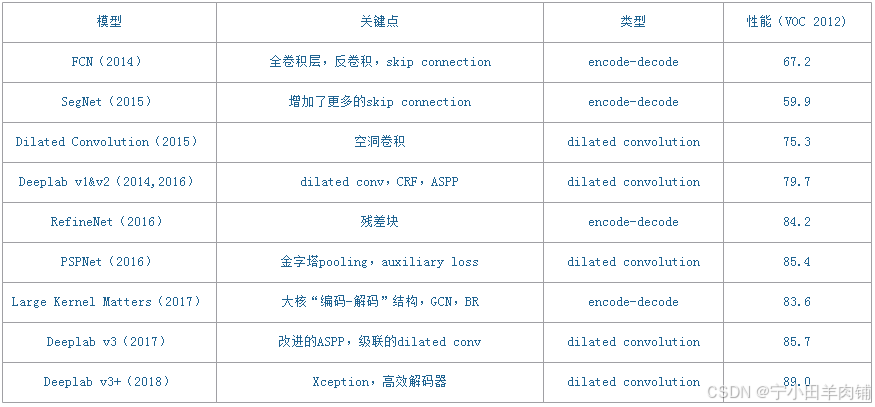
这里将语义分割网络分为两类:一类是以FCN为代表的“encode-decode”,另一类是以Deeplab为代表的“dilate convolution”(空洞卷积网络)。
2、从FCN讲起
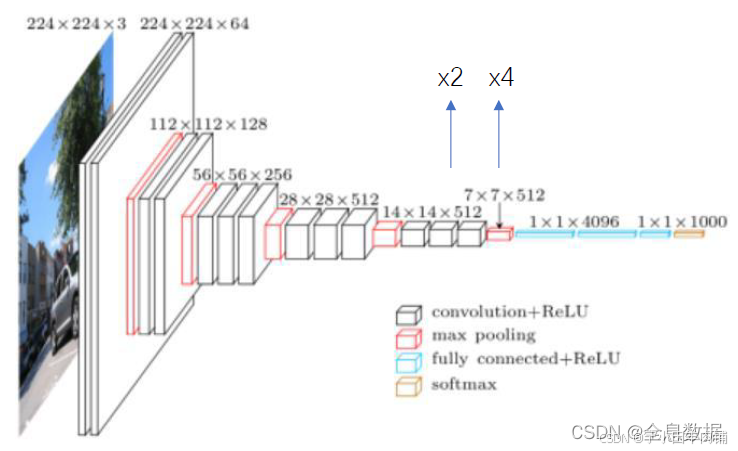
FCN(Fully Convolutional Networks for Semantic Segmentation,2014)是语义分割领域的开山之作,顾名思义其特点就是网络中只有卷积层,没有全连接层。它能够实现端到端的像素级别分类,从下图可以大概了解它的整体结构。
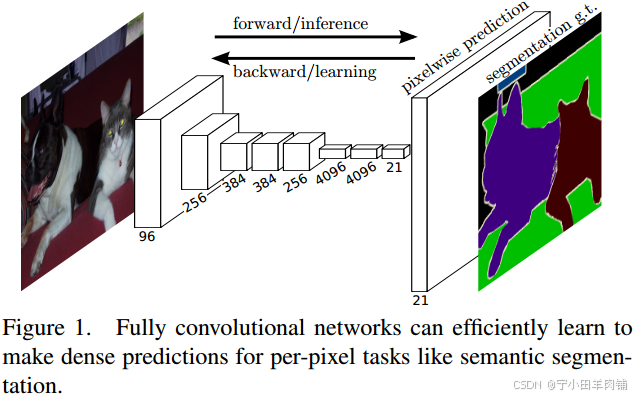
实际上对于FCN这样一种元老级别的网络,它的思想要远大于它的实用价值,所以更多的是了解它的创新想法而不是死抠它的性能。FCN的核心思想包括三方面:
使用卷积代替全连接层,使得网络可以适应任意尺寸的输入;
网络后期使用反卷积进行上采样操作,使得网络的输出恢复到输入尺寸大小,从而进行像素级别的分类;
添加 skip connection,联结 low-level 的降采样特征和 high-level 的上采样层,用以优化预测结果。
2.1 网络结构
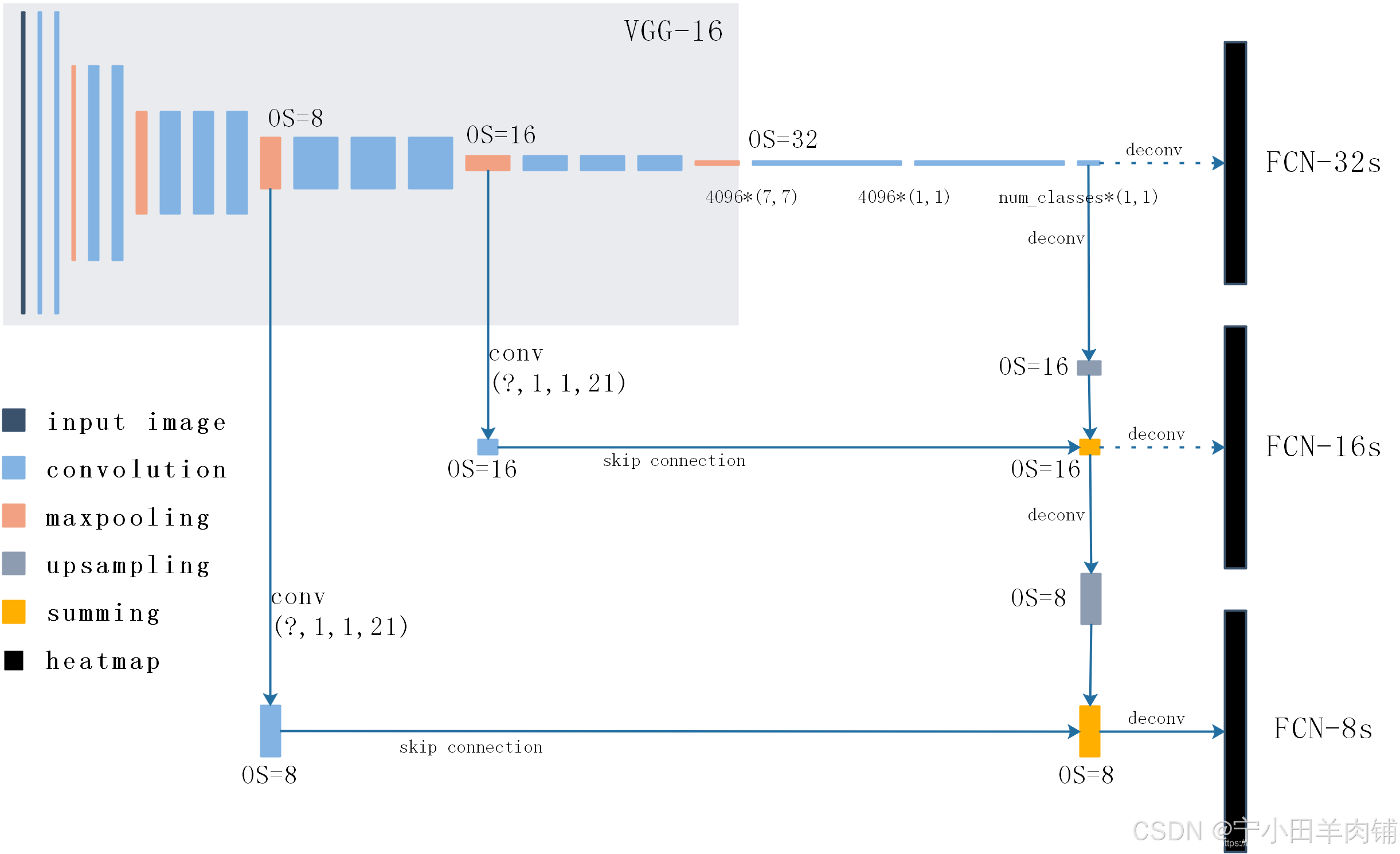
论文中首先是给出 AlexNet 来讲解FCN的思路,然后对比了 VGG-16、GoogLeNet 作为 backbone 时的效果,最终发现 VGG-16 的 mean IU 值是最高的。上图给出了基于 VGG-16 改造后的FCN详细结构,对比 VGG-16 可以发现,FCN改变的就是最后的三个全连接层以及增加的反卷积和skip connection。
首先,VGG-16 中使用5个maxpool,每一次使得特征图的尺寸减半。这里我们采用OS(Output stride)来表示特征图与输入图像的大小关系,例如进行一次maxpool之后特征尺寸减小为输入图像的一半,那么 OS=2。
三个全连接分别被4096个7x7卷积、4096个1x1卷积、num_classes个1x1卷积代替。
两次skip connection分别与maxpool4、maxpool3的输出特征相连接,因为通道数不一样(最终的通道数为num_classes),所以需要用1x1卷积来调整通道数(图中以num_classes=21为例)。
这里的连接并不是concat,而是求和;经过反卷积(upsampling)的high-level特征图与经过maxpool、1x1卷积调整之后的low-level特征图理论上具有完全相同的尺寸、通道,所以直接将对应元素求和是可以的。
heatmap总共有num_classes个,每一个都和输入图像拥有相同的尺寸大小,它代表了每一个像素属于一个类的概率,最终取每一个像素的最大概率值作为其归属类。
虽然有FCN-32s、FCN-16s、FCN-8s三种不同的输出,但是论文证明FCN-8s的精度是最好的,这也体现了skip connection的意义。
2.2 损失函数
因为是像素级别的分类,对于FCN来说每一个像素点就是一个样本。文章将batch_size设置为1,也就是说一次送入一张图,然后对每一个像素的预测类和真实的标签求softmax loss。这里,train和inference稍有区别,inference是直接取每一个像素点的num_classes维向量最大值对应的类,train则是对这个num_classes维向量进行softmax操作,然后求entroy_loss。
这种像素级别的交叉熵损失,将每一个像素点的损失同等对待,但当图像中某一类占主导地位时这种“同一对待”的方式就会显得不太合理。后来的U-Net就给不同的像素损失加以权重辅助,赋予在分割目标边界的像素更高的权重,这种加权损失思想帮助U-Net模型在应对生物学图像的细胞时能够提供边界分明的分割图,从而使得每个细胞个体间的区分更加容易。
另外一种语义分割损失函数的定义就是“Dice coefficient”,它利用heatmap在矩阵级别上与label进行loss的计算,其实跟交叉熵类似,只是交叉熵从像素的通道方向入手,“Dice coefficient”则考虑整体的像素分布。关于“Dice coefficient”的细节内容可以查看上面综述中的第一部分。
2.3 训练数据集
PASCAL VOC 2011中用于语义分割的部分,输入图像尺寸为224。训练分4个阶段进行:
分类训练,就是不修改 VGG-16 的结构进行训练,最后三个全连接层的参数丢弃;
训练FCN-32s,这一阶段耗时3天;
训练FCN-16s,这一阶段耗时1天;
训练FCN-8s,这一阶段耗时1天。
总结:
FCN的反卷积其实和OpenCV中的上采样是一样的道理,只是OpenCV中上采样卷积核的值是固定的,这里上采样卷积核通过学习得到。“卷积+池化”的操作会提取图像中的特征,但是也会损失大量的细节;虽然反卷积可以让feature map的尺寸得以恢复,但是丢失的细节并不能找回来,所以加入low-level的skip connection操作可以看做是找回这些细节。
3、Deeplab V3+
Deeplab V3+ 之前还有三篇文章,但是鉴于Deeplab V3+写的比较详细,不经过前三篇文章的过渡也能基本看懂,除了一些细节、想法的来源等可能是在前面的文章中体现。
3.1 网络结构
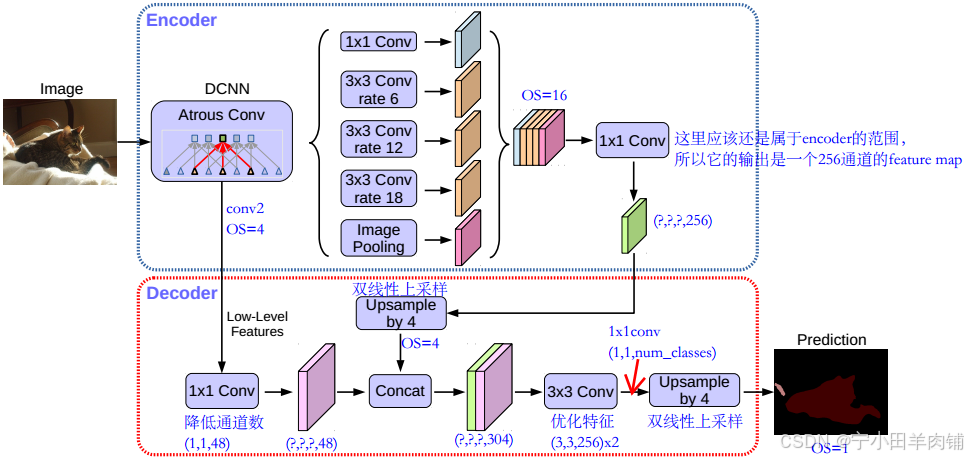
Deeplab V3+也采用了“encode-decode”的方式,所以可以对比FCN的网络来看。Deeplab V3+将Deeplab V3作为自己的 encoder,它沿袭了后者的一些创新项,同时也做了一些优化:
ASPP:Deeplab V3+并不是像FCN的VGG-16那样一味地进行“卷积-池化”,它采用的是ASPP结构:A表示的是“Atrous”,就是空洞卷积;SPP指的就是空间金字塔池化。这两者并不是Deeplab V3+的首创,把它们结合起来Deeplab也做过了,Deeplab V3+继承了该部分内容。空洞卷积使用了三次,从上图也能清晰的看到,分别是 r a t e = [ 6 , 12 , 18 ] rate=[6,12,18] rate=[6,12,18],要注意的是这是针对 OS=16 的情况,如果 OS=8 则需要将每一个空洞卷积的 rate 乘以2;池化操作使用的是平均池化。ASPP得到五个尺度相同、通道数不同的特征图,用concat的方式直接拼接后接一个1x1卷积调整通道数。ASPP部分是接在backbone之后的,Deeplab V3+的backbone采用的是ResNet和Xception两种形式,从最终结果上来看Xception要稍微好于ResNet,当然也可以使用其他的backbone形式,比如说轻量化的MobileNet。
Atrous separable convolution:Deeplab V3中采用了 atrous conv(空洞卷积)来提取特征,这个和FCN是完全不同的;它的优势在于可以获得更大的感受野,同时能得到任意分辨率的特征图像。空洞卷积的感受野由参数 rate 控制,当 rate=1 时就和普通卷积没区别。Deeplab V3+在空洞卷积的基础上引入Depthwise separable convolution(通道分离卷积)的思想(先用input_c个3x3x1卷积对每个通道进行计算,然后用output_c个1x1xinput_c卷积做标准卷积计算),在Xception中使用 atrous separable convolution,大大降低了参数量和计算开销,获得了速度和精度上的提升。
Decoder:Deeplab V3+的decoder部分要优于Deeplab V3的双线性插值,这是Deeplab V3+的创新点所在,可以将之前的encoder看作是对上下文信息的编码,decoder则负责将编码的信息解码得到特征。Deeplab V3+的decoder首先采用因子为4的双线性上采样将编码特征从OS=16变为OS=4,然后抽取encoder中具有相同空间分辨率(low-level)的特征层(例如ResNet101中的conv2),做一个skip connection。因为low-level的特征通道数可能比较大(例如256/512),可能会超过输出编码特征的通道数(ResNet101输出 256 channels) 导致训练困难;作者采用1x1卷积对其进行调整,实验证明调整为 channels=48 效果是最好的。skip connection 采用的是concat操作,之后会进行两次3x3卷积,它们是用来优化特征的,实验证明采取2个3x3卷积的效果最好的。在这个卷积之后的特征通道数并不是我们期待的类别数量,所以要用1x1卷积来调整;最后再加上一个上采样操作,将特征尺寸变为和原始图像尺寸一致,这时每个像素就拥有一个代表类概率的向量了。
Xception:受到MSRA提出的 Aligned Xception 的启发,Deeplab V3+对backbone网络 Xception 也做了一些优化。首先,加深网络但是不修改它的“entry flow”部分,为的是保证高效的计算效率;其次,将maxpool操作用atrous separable convolution代替,获取任意分辨率的特征;还有就是,在每个分离卷积后面添加BN和ReLu操作。实验证明,优化后的Xception效果无论是Top1还是Top5都要比ResNet101好。
Deeplab V3+ 定义 encoder 的输入图像空间分辨率和输出图像空间分辨率之比为输出步长(output stride,简写为OS)。一般情况下,图像分类任务中会取 OS=32,表示输出的特征空间分辨率是很小的;但是在语义分割任务中,OS=16 或 OS=8(这在FCN中也能看到),OS如果太大表示丢失的边缘细节会更多,即便进行上采样恢复到输入图像分辨率大小其效果也不会很好。作者通过实验对比说明:OS=16时精度和速度上取得较好的平衡;OS=8时精度更高,但是计算复杂度增加。
3.2 损失函数
Deeplab V3+的损失函数跟FCN是一样的,也是逐像素的交叉熵损失。在这里插入图片描述

3.3 训练数据集
Pretrained用 ImageNet-1K 数据集训练 ResNet101或者优化后的Xception,用来获取dense feature map。对于Xception的预训练还使用了JFT-300M数据集,实验证明用JFT-300M会有1%左右的提升。
接下来的主体网络使用PASCAL VOC 2012数据集训练,包括20类object和1个背景类,训练的输入图像大小为513*513,还做了一定的数据增强。测试集的话作者使用了CityScapes,这是一个大尺度、高分辨率的像素级标注数据集,Deeplab V3+在该数据集上取得了82.1%的成绩。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









