









 本文探讨了缓存预热、缓存雪崩和穿透的概念,提出了通过全量数据存储和实时更新策略来确保数据库与Redis数据一致性的方法。介绍了订单服务如何利用MQ或Binlog实现实时更新缓存,并讨论了Canal项目的应用。
本文探讨了缓存预热、缓存雪崩和穿透的概念,提出了通过全量数据存储和实时更新策略来确保数据库与Redis数据一致性的方法。介绍了订单服务如何利用MQ或Binlog实现实时更新缓存,并讨论了Canal项目的应用。
前导概念
- 缓存预热:新的缓存系统没有任何缓存数据,在缓存重建数据的过程中,系统性能和数据库负载都不太好,所以最好是
在系统上线之前就把要缓存的热点数据加载到缓存中,这种缓存预加载手段就是缓存预热。 - 缓存雪崩:
缓存集中在某一时段失效,请求全部转发到数据库,数据库瞬时压力过重导致雪崩效应。 - 缓存穿透:
缓存没有命中时,就穿透缓存去访问数据库。一般情况下,只要做好缓存预热,缓存的命中率就会很高,但是如果Redis缓存服务的是一个超大规模的系统,即便很小比例的请求穿透缓存,打到数据库的请求绝对数量仍然不小,存在雪崩的风险。 彻底避免雪崩的方案:取消缓存穿透机制,即把全量数据都放在redis集群中。
如何更新缓存数据
- 因为我们取消了缓存穿透机制,这种情况下从缓存读到数据就返回,读不到就报错。所以当更新了数据库后,必须及时更新缓存。
- 怎么保证数据库和Redis的数据一致呢,可以用分布式事务,但是对数据更新服务有很强侵入性(
我的理解是需要在代码中保证数据可和Redis都更新成功,一个不成功就返回失败),且如果Redis本身出现故障,写入数据失败,还会导致下单失败,等于是降低了性能和可用性。
方案1
- 比如订单服务,
可以启动一个更新订单缓存的服务,接收订单变更的MQ(消息队列)消息,消费者进行更新Redis中的订单数据。 - 需要担心的问题是,如果丢消息了,那么缓存的数据就会不正确,所以必须保证消息链条的可靠性。
- 不过现在MQ集群,比如Kafka或者RocketMQ,都有高可用的保证,只要正确配置就可以满足需求。
- 像订单服务这样,本身就有很多消费者的情况,增加一个消费者,基本没什么成本。也对其他模块没有侵入。
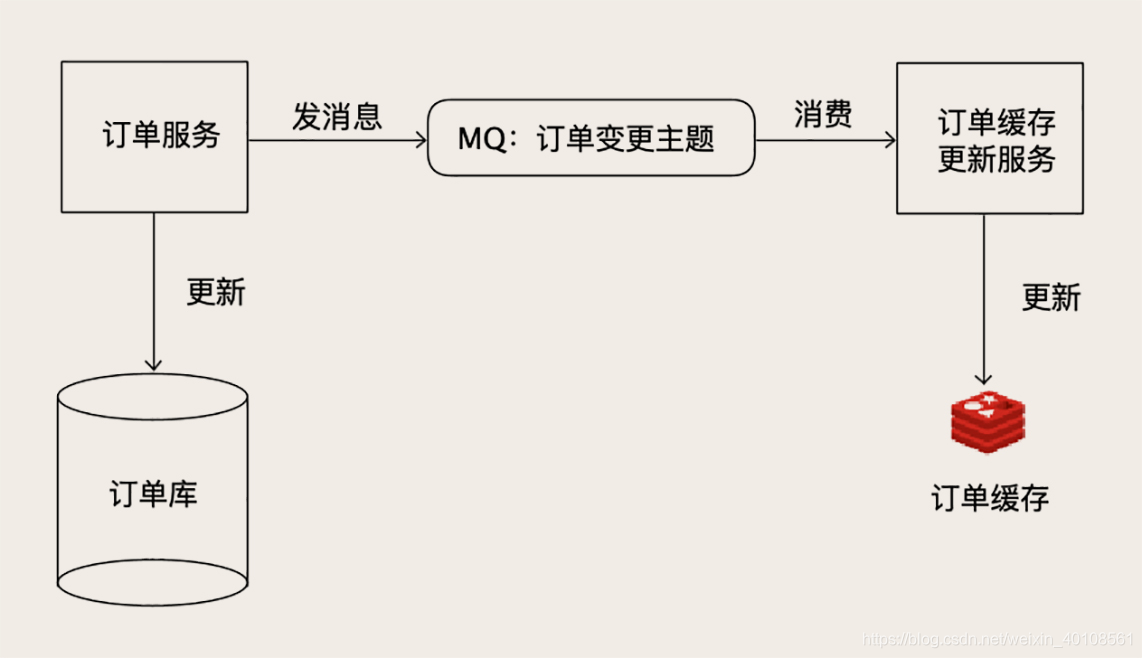
方案2
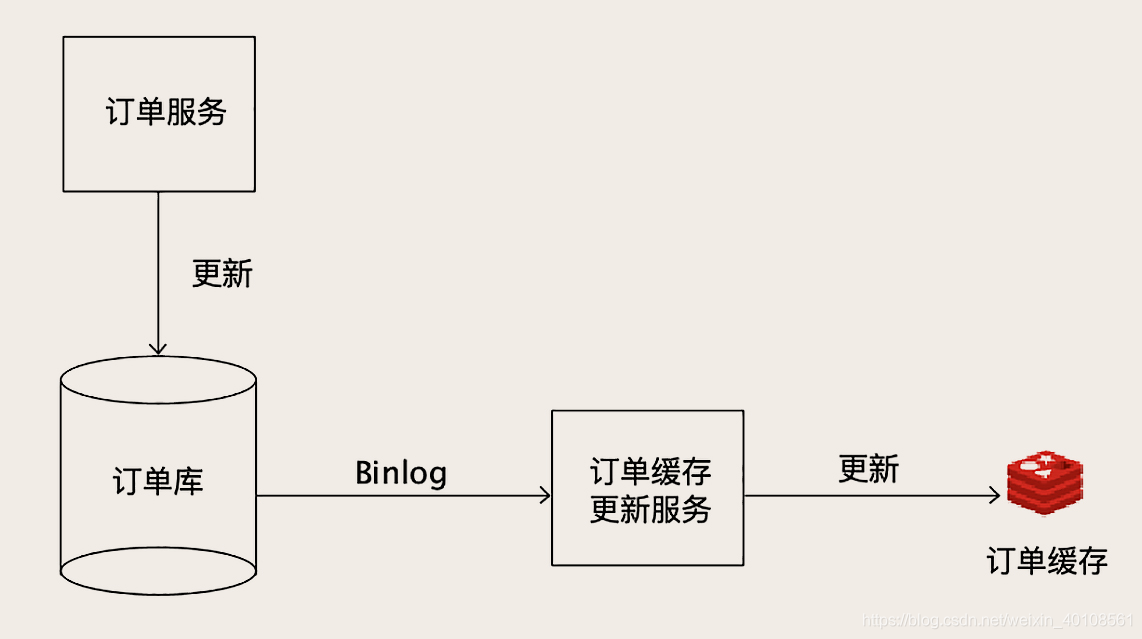
- 如果要缓存的数据,之前没有一份数据更新的MQ消息可以订阅,更通用的方案是
使用Binlog实时更新Redis。 - 数据更新服务只负责处理业务逻辑,更新Mysql。负责更新缓存的服务,
把自己伪装成一个Mysql从节点,从Mysql接收Binlog,解析Binlog之后,可以得到实时的数据变更信息,根据变更信息去更新Redis。 - 方案的缺点是,解析Binlog比较麻烦,可以参考开源项目,比如Canal(java)
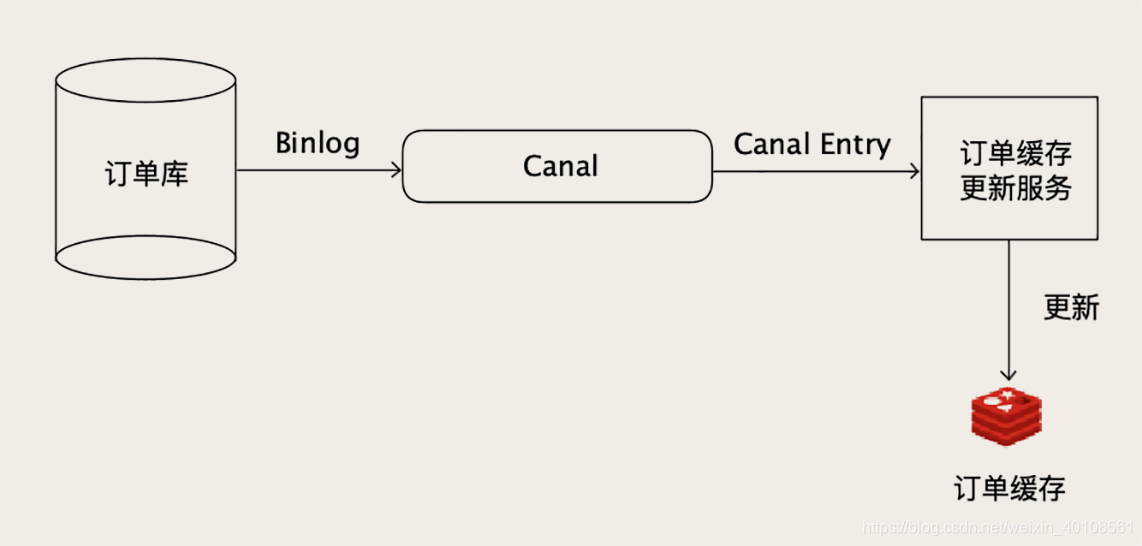
附录
MySQL主备复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)

















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









