






 本文介绍了支持向量机(SVM)的基本概念,包括SVM的优化目标,它如何通过大间隔学习实现更好的分类效果。解释了SVM与Logistic回归的区别,并探讨了核函数在解决非线性问题中的作用,特别是高斯核函数的应用。此外,还提到了在不同数据规模下选择SVM或Logistic回归的策略。
本文介绍了支持向量机(SVM)的基本概念,包括SVM的优化目标,它如何通过大间隔学习实现更好的分类效果。解释了SVM与Logistic回归的区别,并探讨了核函数在解决非线性问题中的作用,特别是高斯核函数的应用。此外,还提到了在不同数据规模下选择SVM或Logistic回归的策略。
终于讲到了算法的内容了,Support Vector Machines(简称SVM)支持向量机是机器学习与数学建模中非常重要的一种算法,一般用于分类与判别,你可以能还会见到Support Vector Classification(简称SVC)、Support Vector Regression(简称SVR),分别用于分类与回归,别担心他们的内理是一模一样的,只是功能不同而进行了划分罢了。
优化目标(Optimization Objective)
我们先从Logistic回归说起,我们知道在Logistic回归中,Sigmoid函数的作用
我们分别画出当
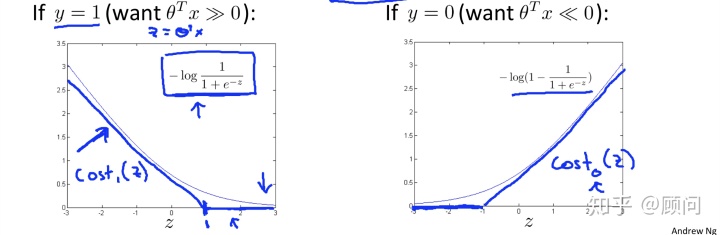
我们可以很明显地看出当
下面我们重写SVM的整体代价函数,我们加入了正则项,并与logistic作对比:
我们可以看出SVM中有一个常数C,没有关系,你可以把他当做和正则化参数一样的东西,用于调整权重的比例,防止过拟合的问题。这就是SVM的优化目标,即代价函数。
大间隔学习(Large Margin Learning)
支持向量机还有一个名称,就是大间隔学习,下面我会用可视化的方式来告诉你为何它是大间隔学习,以及为何它的效果要优于我们的Logistic回归。假设我们有一个二分类的样本,如下图所示:
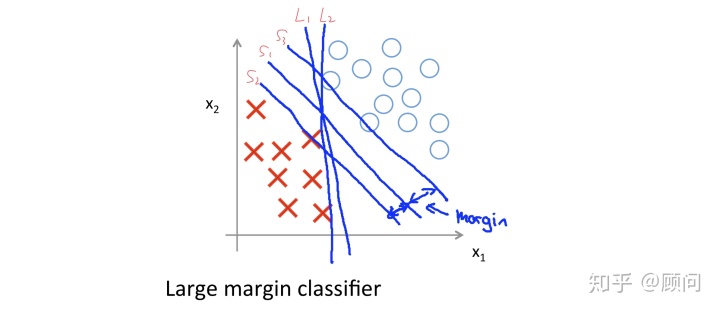
在这里分类问题中,L1和L2是我们Logsitic回归可能得到的决策界限,可以看出的是,虽然这两条直线,确实分开了两个样本,但是分类效果并不太好。而支持向量机划分的决策界限,则是S1,其中S2和S3为初始划定界限,最终选择S1作为决策界限,而S1与S2、S3的距离被称为Margin。这就是我们称SVM为大间隔学习的原因,其中关于SVM为何能做到这样的原因,就牵扯到了其背后的数学原理,在这里不做展开,比较复杂,建议基础扎实后看西瓜书或我老板朋友Free Mind的博客。ps:之前听说有位学长面试时手推SVM,被lamda录取了。
核函数(Kernel)
其实核函数核方法这些东西在所有的模型算法中都能应用到,但是其在SVM中的效果明显,所以核函数常常后来和SVM一起出现。我们在解决非线性问题的时候,常常会为假设函数的选择而困扰,选择单变量一次项
下面我们就来谈谈如何选择这项通用式子中的
其中similarity函数就是我们所经常使用高斯核函数(Gaussion Kernels),如果特征值离我们的定义坐标点越近,则
简单说说,我们如何选择坐标点
那我们便选择m个坐标点,
- String kernel
- chi-square kernel
- histogram intersection kernel
不过最常用且较为容易的还是高斯核函数。
与Logistic如何选择
我们假设
- 如果n相对于m来说非常大:我们选用Logistic回归,或者不用核函数的SVM(不用核函数就相当于线性核函数Linear Kernel)。
- 如果n比较小,m中等:我们选用高斯核函数的SVM。
- 如果n小,m大:那我们需要增加特征向量的种类,然后同理第一种情况。

















 3279
3279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









