



 这篇博客介绍了如何基于PyTorch实现PredRNN,一个用于强对流天气临近预报的时空序列预测模型。作者参考ConvLSTM2D的开源代码简化了PredRNN的实现,并提供了模型结构、训练与测试的详细说明。结果显示,该模型在预测雷达回波图方面优于ConvLSTM2D。
这篇博客介绍了如何基于PyTorch实现PredRNN,一个用于强对流天气临近预报的时空序列预测模型。作者参考ConvLSTM2D的开源代码简化了PredRNN的实现,并提供了模型结构、训练与测试的详细说明。结果显示,该模型在预测雷达回波图方面优于ConvLSTM2D。
背景:
南京信息工程大学60周年校庆活动暨2020年科技活动月——“高影响天气精细化预报”学术研讨会
报告题目: 张小玲—AI技术在强对流天气预报中的应用
PredRNN++是目前国家气象中心报告题目中提及的用于短临预报的标配模型。但很多朋友普遍反馈PredRNN系列论文的官配完全体代码比较复杂。因此我参考ConvLSTM2D的开源代码,写了一个比较基础简单容易看懂的的PredRNN主干代码供大家参考交流,同时欢迎指出其中可能存在的错误。PredRNN++后续开源,目前测试效果并没有比PredRNN好太多,还在检查阶段。
ConvLSTM2D->ConvLSTM3D->PredRNN->PredNet-> PredRNN++->Memoryin Memory->E3D-LSTM是我暂定的一个复现路线.下面是经过自己理解,在ConLSTM2D开源代码的基础上复现的一个简易版PredRNN.主要的代码解释已经标注在代码中.主要Debug点是Cell中的卷积,欢迎大家指正.
雷达回波数据使用的是厦门,杭州,宁波的雷达拼图, 6min/次滚动更新,由于资料的保密性,因此个人没有公开.
模型设置:
Layer数为2
隐藏层hidden_dim为7,1
Layer方向上时间状态M由于当前层输入和输出维度的一致性,因此统一hidden_dim_m为7.
采用Seq2seq的教师强制训练train模式,test采用t-1时刻的Output作为t时刻的Input,去预测t时刻的雷达回波特征Prediction.
模型Train时使用的是(0-9预测1-10)(0-54min预测6-60min))时刻的雷达回波图,
模型Test时使用的是10-16(60-96min)时刻的雷达回波图。
结果是任何指标上都要明显好于pytorch和tensorflow版的ConvLSTM2D(即使ConvLSTM2D在模型深度的设置上要更占优势).
由于本机配置实在很低,所以将原始雷达回波图压缩成(C,H,W)=(1,100,100).时间关系后续再放上其它几类模型的对比结果吧.下面是雷达回波的外推结果:
 ←实况 预测→
←实况 预测→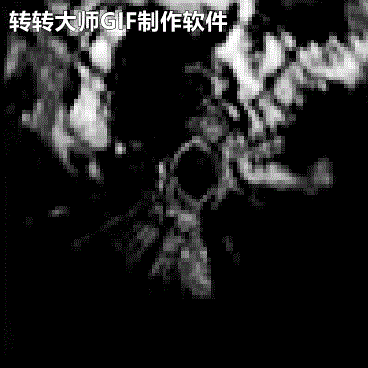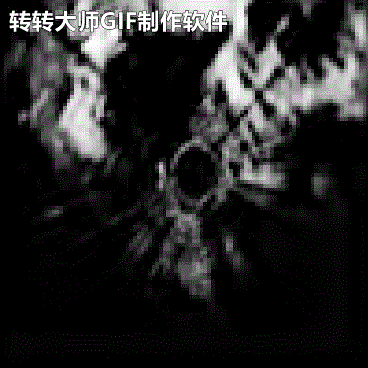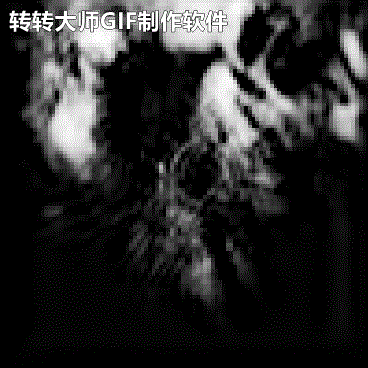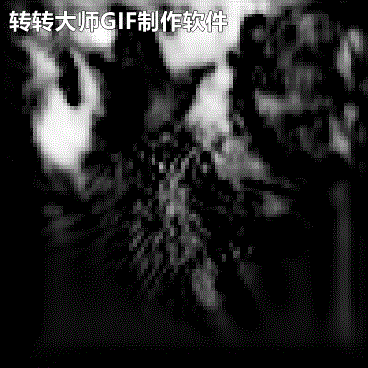
代码分为3文件:
PredRNN_Cell.py #细胞单元
PredRNN_Model.py #细胞单元堆叠而成的主干模型
PredRNN_Main_Seq2seq_test.py #用于外推的Seq2seq//// 编码解码
# PredRNN_Cellimport torch.nn as nnfrom torch.autograd import Variableimport torch###################################### 单层,单时间步的PredRNNCell(细胞/单元),用于构造整个外推模型# The cell/unit of predrnncell of every layer and time_step, for constructing the entire extrapolation model.#####################################class PredRNNCell(nn.Module): def __init__(self, input_size, input_dim, hidden_dim_m, hidden_dim,kernel_size, bias): super(PredRNNCell, self).__init__() self.height, self.width = input_size self.input_dim = input_dim self.hidden_dim = hidden_dim self.hidden_dim_m = hidden_dim_m # hidden of M self.kernel_size = kernel_size self.padding = kernel_size[0] // 2, kernel_size[1] // 2 self.bias = bias ##################################################################################### # 相应符号可对应参照论文 # Corresponding symbols can correspond to reference paper # conv_h_c for gt, it, ft # conv_m for gt', it', ft' # conv_o for ot # self.conv_h_next for Ht self.conv_h_c = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim, out_channels=3 * self.hidden_dim, kernel_size=self.kernel_size, padding=self.padding, bias=self.bias) self.conv_m = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim_m, out_channels=3 * self.hidden_dim_m, kernel_size=self.kernel_size, padding=self.padding, bias=self.bias) self.conv_o = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim * 2 + self.hidden_dim_m, out_channels=self.hidden_dim, kernel_size=self.kernel_size, padding=self.padding, bias=self.bias) self.conv_h_next = nn.Conv2d(in_channels=self.hidden_dim + self.hidden_dim_m, out_channels=self.hidden_dim, kernel_size=1, bias=self.bias) def forward(self, input_tensor, cur_state, cur_state_m): h_cur, c_cur= cur_state #cur = Current input of H and C h_cur_m = cur_state_m #cur = Current input of m combined_h_c = torch.cat([input_tensor,h_cur], dim=1) combined_h_c = self.conv_h_c(combined_h_c) cc_i, cc_f, cc_g = torch.split(combined_h_c, self.hidden_dim, dim=1) combined_m = torch.cat([input_tensor, h_cur_m], dim=1) combined_m = self.conv_m(combined_m) cc_i_m, cc_f_m, cc_g_m = torch.split(combined_m, self.hidden_dim_m, dim=1) i = torch.sigmoid(cc_i) f = torch.sigmoid(cc_f) g = torch.tanh(cc_g) c_next = f * c_cur + i * g i_m = torch.sigmoid(cc_i_m) f_m = torch.sigmoid(cc_f_m) g_m = torch.tanh(cc_g_m) h_next_m = f_m * h_cur_m + i_m * g_m combined_o = torch.cat([input_tensor, h_cur, c_next, h_next_m], dim=1) combined_o = self.conv_o(combined_o) o = torch.sigmoid(combined_o) h_next = torch.cat([c_next, h_next_m], dim=1) h_next = self.conv_h_next(h_next) h_next = o * torch.tanh(h_next) return h_next, c_next, h_next_m ##################################### # # 用于在t=0时刻时初始化H,C,M # For initializing H,C,M at t=0 # ##################################### def init_hidden(self, batch_size): return (Variable(torch.zeros(batch_size, self.hidden_dim, self.height, self.width)).cuda(), Variable(torch.zeros(batch_size, self.hidden_dim, self.height, self.width)).cuda())#PredRNN_Modelimport torch.nn as nnimport torchimport numpy as npfrom torch.autograd import Variablefrom PredRNN_Cell import PredRNNCell################################################ 构造PredRNN# Construct PredRNN###############################################class PredRNN(nn.Module): def __init__(self, input_size, input_dim, hidden_dim, hidden_dim_m, kernel_size, num_layers, batch_first=False, bias=True): super(PredRNN, self).__init__() self._check_kernel_size_consistency(kernel_size) kernel_size = self._extend_for_multilayer(kernel_size, num_layers) # 按照层数来扩充 卷积核尺度/可自定义 hidden_dim = self._extend_for_multilayer(hidden_dim, num_layers) # 按照层数来扩充 LSTM单元隐藏层维度/可自定义 hidden_dim_m = self._extend_for_multilayer(hidden_dim_m, num_layers) # M的单元应保持每层输入和输出的一致性. if not len(kernel_size) == len(hidden_dim) == num_layers: # 判断相应参数的长度是否与层数相同 raise ValueError('Inconsistent list length.') self.height, self.width = input_size self.input_dim = input_dim self.hidden_dim = hidden_dim self.hidden_dim_m = hidden_dim_m self.kernel_size = kernel_size self.num_layers = num_layers self.batch_first = batch_first self.bias = bias cell_list = [] for i in range(0, self.num_layers): if i == 0: # 0 时刻, 图片的输入即目前实际输入 cur_input_dim = self.input_dim else: cur_input_dim = self.hidden_dim[i - 1] # 非0时刻,输入的维度为上一层的输出 #Cell_list.appenda为堆叠层操作 cell_list.append(PredRNNCell(input_size=(self.height, self.width), input_dim=cur_input_dim, hidden_dim=self.hidden_dim[i], hidden_dim_m=self.hidden_dim_m[i], kernel_size=self.kernel_size[i], bias=self.bias).cuda()) self.cell_list = nn.ModuleList(cell_list)#Cell_list进行Model化 def forward(self, input_tensor, hidden_state=False, hidden_state_m=False): if self.batch_first is False: input_tensor = input_tensor.permute(1, 0, 2, 3, 4) if hidden_state is not False: hidden_state = hidden_state else: #如果没有输入自定义的权重,就以0元素来初始化 hidden_state = self._init_hidden(batch_size=input_tensor.size(0)) if hidden_state_m is False: h_m = Variable(torch.zeros(input_tensor.shape[0], self.hidden_dim_m[0], input_tensor.shape[3], input_tensor.shape[4]) ,requires_grad=True).cuda() else: h_m = hidden_state_m layer_output_list = [] #记录输出 layer_output_list_m = [] # 记录每一层m layer_output_list_c = [] # 记录每一层c last_state_list = [] #记录最后一个状态 layer_output_list_m = [] # 记录最后一个m last_state_list_m = [] # 记录最后一个m seq_len = input_tensor.size(1) #第二个时间序列,3 cur_layer_input_1 = input_tensor #x方向上的输入 all_layer_out = [] for t in range(seq_len): concat=[] output_inner_c = [] # 记录输出的c output_inner = [] #记录输出的c output_inner_m = [] # 记录输出的m output_inner_h_c=[] # 记录输出的h 和c h0 = cur_layer_input_1[:, t, :, :, :] #确定layer = 1 时的输入,如雷达回波图等矩阵信息 for layer_idx in range(self.num_layers): # 由于M在layer上传递,所以优先考虑layer上的传递 if t == 0: # 由于M在layer上传递,所以要区分t=0(此时m初始化) h, c = hidden_state[layer_idx] # h和c来自于初始化/自定义 h, c, h_m = self.cell_list[layer_idx](input_tensor=h0, cur_state=[h, c], cur_state_m=h_m)#经过一个cell/units输出的h,c,m output_inner_c.append(c) #记录输出的c进行 output_inner.append(h) output_inner_m.append(h_m) output_inner_h_c.append([h,c]) h0=h else: h = cur_layer_input[layer_idx] c = cur_layer_input_c[layer_idx] h, c, h_m = self.cell_list[layer_idx](input_tensor=h0, cur_state=[h, c], cur_state_m=h_m) output_inner_c.append(c) output_inner.append(h) output_inner_m.append(h_m) output_inner_h_c.append([h, c]) h0 = h cur_layer_input = output_inner#记录某个t,全部layer的输出h cur_layer_input_c = output_inner_c#记录某个t,全部layer的输出c cur_layer_input_m = output_inner_m#记录某个t,全部layer的输出m alllayer_output = torch.cat(output_inner, dim=1) #把某个t时刻每个隐藏层的输出进行堆叠,以便于在解码层参照Convlstm使用1x1卷积得到输出 all_layer_out.append(alllayer_output)#记录每个t时刻,所有隐藏层输出的h,以便于在解码层参照Convlstm使用1x1卷积得到输出 per_time_all_layer_stack_out=torch.stack(all_layer_out, dim=1)#记录每个t时刻,所有隐藏层输出的h,以便于在解码层参照Convlstm使用1x1卷积得到输出 layer_output_list.append(h)# 记录每一个t得到的最后layer的输出h last_state_list.append([h, c])#记录每一个t得到的最后layer的输出h,C last_state_list_m.append(h_m)#记录每一个t得到的最后layer的输出m #按层对最后一层的H和C进行扩展 # ↓↓↓↓↓↓↓↓↓全部t时刻最后layer的输出h # ↓↓↓↓↓↓↓↓↓最后t时刻全部layer的输出h和c # ↓↓↓↓↓↓↓↓↓全部t时刻最后layer的输出m/t+1时刻0 layer的输入m # ↓↓↓↓↓↓↓↓↓全部时刻全部layer的h在隐藏层维度上的总和,hidden_dim = [7,1],则输出channels = 8 return torch.stack(layer_output_list, dim=1),\ output_inner_h_c,\ torch.stack(last_state_list_m, dim=0),\ per_time_all_layer_stack_out def _init_hidden(self, batch_size): init_states = [] for i in range(self.num_layers): init_states.append(self.cell_list[i].init_hidden(batch_size)) return init_states @staticmethod def _check_kernel_size_consistency(kernel_size): if not (isinstance(kernel_size, tuple) or (isinstance(kernel_size, list) and all([isinstance(elem, tuple) for elem in kernel_size]))): raise ValueError('`kernel_size` must be tuple or list of tuples') @staticmethod def _extend_for_multilayer(param, num_layers): if not isinstance(param, list): param = [param] * num_layers return param#PredRNN_Seq2Seqfrom PredRNN_Model import PredRNNimport torch.optim as optimimport torch.nn as nnimport matplotlib.pyplot as pltimport numpy as npfrom torch.autograd import Variableimport torchfrom PIL import Imagefrom torch.utils.data import Dataset, DataLoaderimport osimport timeinput=torch.rand(1,1,1,100,100).cuda() # Batch_size , time_step, channels, hight/width, width/highttarget=torch.rand(1,1,1,100,100).cuda() # Batch_size , time_step, channels, hight/width, width/hightclass PredRNN_enc(nn.Module): def __init__(self): super(PredRNN_enc, self).__init__() self.pred1_enc=PredRNN(input_size=(100,100), input_dim=1, hidden_dim=[7, 1], hidden_dim_m=[7, 7], kernel_size=(7, 7), num_layers=2, batch_first=True, bias=True).cuda() def forward(self,enc_input): _, layer_h_c, all_time_h_m, _ = self.pred1_enc(enc_input) return layer_h_c, all_time_h_mclass PredRNN_dec(nn.Module): def __init__(self): super(PredRNN_dec, self).__init__() self.pred1_dec=PredRNN(input_size=(100,100), input_dim=1, hidden_dim=[7, 1], hidden_dim_m=[7, 7], kernel_size=(7, 7), num_layers=2, batch_first=True, bias=True).cuda() self.relu = nn.ReLU() def forward(self,dec_input,enc_hidden,enc_h_m): out, layer_h_c, last_h_m, _ = self.pred1_dec(dec_input,enc_hidden,enc_h_m) out = self.relu(out) return out, layer_h_c, last_h_menc=PredRNN_enc().cuda()dec=PredRNN_dec().cuda()import itertoolsloss_fn=nn.MSELoss()position=0optimizer=optim.Adam(itertools.chain(enc.parameters(), dec.parameters()),lr=0.001)for epoch in range(1000): loss_total=0 enc_hidden, enc_h_m = enc(input) for i in range(input.shape[1]): optimizer.zero_grad() out, layer_h_c, last_h_m = dec(input[:,i:i+1,:,:,:], enc_hidden, enc_h_m[-1]) loss=loss_fn(out, target[:,i:i+1,:,:,:]) loss_total+=loss enc_hidden = layer_h_c enc_h_m = last_h_m loss_total=loss_total/input.shape[1] loss_total.backward() optimizer.step() print(epoch,epoch,loss_total)最终感谢几位大佬:
京东张老师和他的公众号 MeteoAI
东南大学的蜗牛哥和他的公众号 AI蜗牛车
特此特别谢谢上面两个大佬带我Gank比赛??,
尤其感谢张老师的一个Request让我一周装5次Linux和WRF
尤其感谢蜗牛哥公众号:时空预测模型专栏
上海眼控科技的吕老师
特别谢谢吕老师带我AI的同时还带我溜数值模式,虽然我现在还是个菜?。
地主黑总
无敌高冷喵老师
说实话在这个群,哪怕我不说什么话,也能学到很多东西
PredRNN论文,ConvLSTM2D,PredRNN_Pytorch简易版的链接如下:
PredRNN Paper: Recurrent Neural Networks for Predictive Learningusing Spatiotemporal LSTMs: http://ise.thss.tsinghua.edu.cn/ml/doc/2017/predrnn-nips17.pdf
PytorchConvLSTM2D: https://github.com/ndrplz/ConvLSTM_pytorch
PredRNN: https://github.com/ZhiChaZhang/Basic_PredRNN_Seq2seq


















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









