







这位博主有、东西哦:https://cuijiahua.com/blog/2017/11/ml_10_adaboost.html
机器学习实战中介绍的前几种算法都是分类算法,我们可以将多种分类器或在不同情况下的单种分类器进行集成,这样的方法叫做元算法(meta-algorithm)或者叫做集成方法(ensemble method)。Adaboost就是一种集成方法,通过集成不同设置下的单种分类器,达到提升分类器性能的目的。
在了解Adaboost之前,需要了解两种基础方法--bagging和boosting。
一、集成方法:
1. bagging:
bagging(bootstrap aggregating)成为自举汇聚法,他的思路是从原始的数据集中选择N次,得倒N个新数据集。方法如下:
-
从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
-
每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
-
对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
2. boosting:
Boosting的思路则是采用重赋权(re-weighting)法迭代地训练基分类器,主要思想:
-
每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果。
-
基分类器之间采用序列式的线性加权方式进行组合。
3. 两种方法的本质都是将多个分类器整合成一个分类器,其中的区别只是在整合过程中的权重问题,bagging的权重是平均的而boosting的权重是随着训练改变的。
目前最先进的bagging方法叫做随机森林,由bagging和决策树两种算法结合而成。
二、AdaBoost算法:
AdaBoost(adaptive boosting)算法是一种基于错误提升分类器性能的方法,其数学原理如下:
1. 样本权重:
在Adaboost算法中,每个训练样本都有其对应的权重,算法会根据预测的结果更改这些权重值,并将其应用到下一轮的计算中,权重的初始值是一样的在程序中用D表示,假设有N个样本,则每个样本的初始权重都为1/n。
2. 计算错误率:
每一次使用弱分类算法完成预测后都会对错误率进行统计,统计的方法为:未正确分类的样本数目/总结样本的数目。
3. 计算样本的权重
4. 更新权重:

5. Adaboost算法:

三、构建若分类器作为Aaboost的基础:
1. 读取数据并可视化:
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def showDataSet(dataMat, labelMat):
"""
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
无
"""
data_plus = [] #正样本
data_minus = [] #负样本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #转换为numpy矩阵
data_minus_np = np.array(data_minus) #转换为numpy矩阵
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正样本散点图
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #负样本散点图
plt.show()
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
showDataSet(dataArr,classLabels)上面的两个函数定义了一个简单的数据集并将数据集可视化,可以放在模块中使用。
2. 构建单层的决策树:
构建单层的决策树,需要一个判断机制和生成树的函数,代码如下:
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
"""
创建单层决策树的数据集
Parameters:
无
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
"""
datMat = np.matrix([[ 1. , 2.1],
[ 1.5, 1.6],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
"""
单层决策树分类函数
Parameters:
dataMatrix - 数据矩阵
dimen - 第dimen列,也就是第几个特征
threshVal - 阈值
threshIneq - 标志
Returns:
retArray - 分类结果
"""
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray为1
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小于阈值,则赋值为-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大于阈值,则赋值为-1
return retArray
def buildStump(dataArr,classLabels,D):
"""
找到数据集上最佳的单层决策树
Parameters:
dataArr - 数据矩阵
classLabels - 数据标签
D - 样本权重
Returns:
bestStump - 最佳单层决策树信息
minError - 最小误差
bestClasEst - 最佳的分类结果
"""
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T
m,n = np.shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1)))
minError = float('inf') #最小误差初始化为正无穷大
for i in range(n): #遍历所有特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特征中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #计算步长
for j in range(-1, int(numSteps) + 1):
for inequal in ['lt', 'gt']: #大于和小于的情况,均遍历。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #计算阈值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#计算分类结果
errArr = np.mat(np.ones((m,1))) #初始化误差矩阵
errArr[predictedVals == labelMat] = 0 #分类正确的,赋值为0
weightedError = D.T * errArr #计算误差
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到误差最小的分类方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
D = np.mat(np.ones((5, 1)) / 5)
bestStump,minError,bestClasEst = buildStump(dataArr,classLabels,D)
print('bestStump:\n', bestStump)
print('minError:\n', minError)
print('bestClasEst:\n', bestClasEst)上边代码的运行结果如下图:
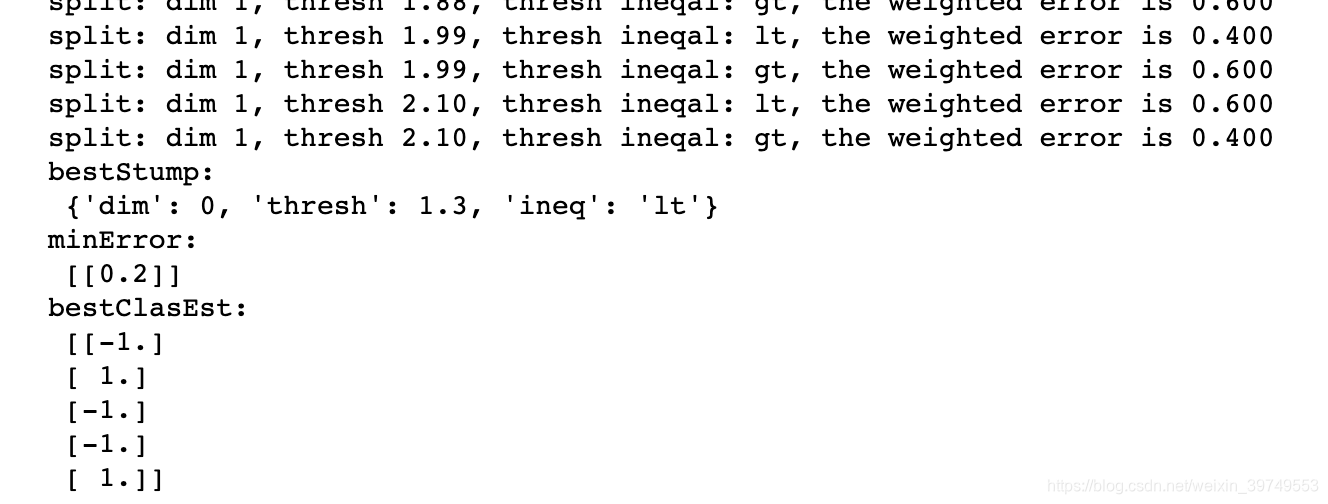
代码运行的过程是,在遍历数据集的过程中不断的改变阈值,计算最终的分类误差,并找到分类误差最小的一个分类方式,将该分类方式存储下来,这样就找到了一个最佳的单层决策树。这里lt表示less than,表示分类方式,对于小于阈值的样本点赋值为-1,gt表示greater than,也是表示分类方式,对于大于阈值的样本点赋值为-1。经过遍历,我们找到,训练好的最佳单层决策树的最小分类误差为0.2,就是对于该数据集,无论用什么样的单层决策树,分类误差最小就是0.2。这就是我们训练好的弱分类器。接下来,使用AdaBoost算法提升分类器性能,将分类误差缩短到0,看下AdaBoost算法是如何实现的。
四、 使用Adaboost提升分类器性能
在程序中添加如下代码,
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m, 1)) / m) #初始化权重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #构建单层决策树
print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #计算弱学习算法权重alpha,使error不等于0,因为分母不能为0
bestStump['alpha'] = alpha #存储弱学习算法权重
weakClassArr.append(bestStump) #存储单层决策树
print("classEst: ", classEst.T)
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #计算e的指数项
D = np.multiply(D, np.exp(expon))
D = D / D.sum() #根据样本权重公式,更新样本权重
#计算AdaBoost误差,当误差为0的时候,退出循环
aggClassEst += alpha * classEst
print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #计算误差
errorRate = aggErrors.sum() / m
print("total error: ", errorRate)
if errorRate == 0.0: break #误差为0,退出循环
return weakClassArr, aggClassEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print(weakClassArr)
print(aggClassEst)运行后的结果如下:
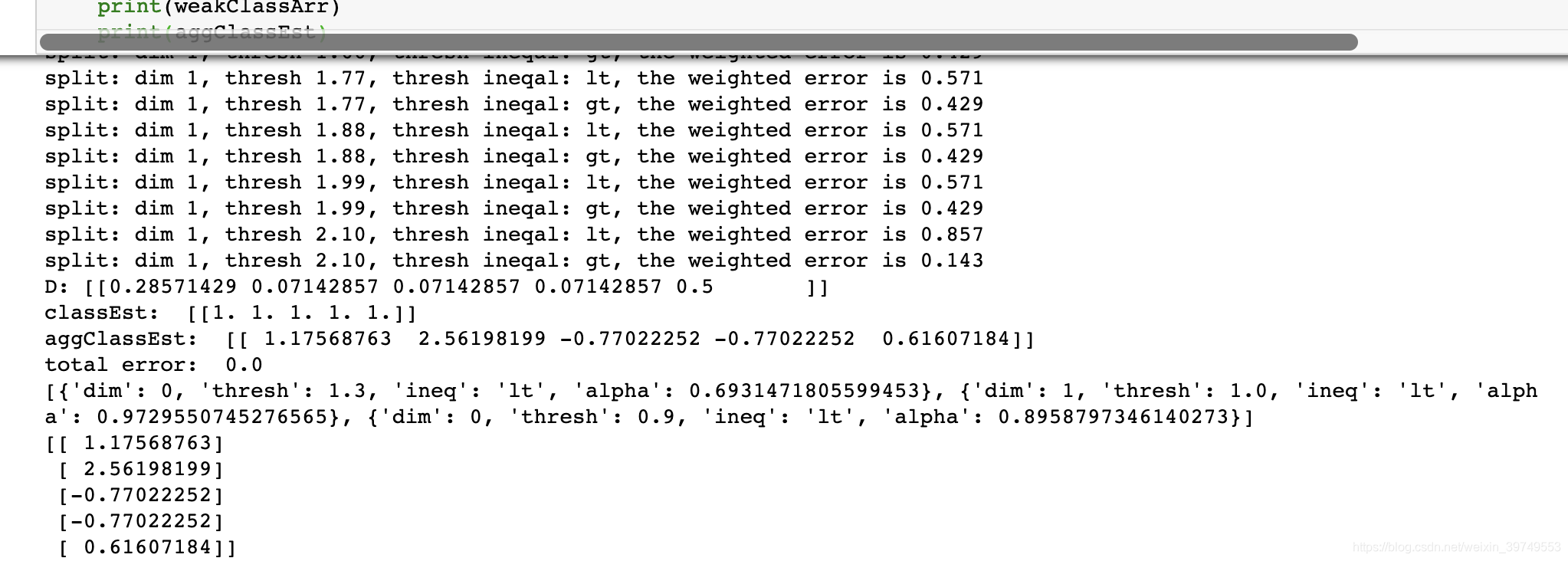
在第一轮迭代中,D中的所有值均为0.2 ,结果第一个数据点被错分了。在第二轮迭代中,程序通过错误率的计算,使D向量给第一个数据点的权重增加到了0.5。最后通过变量aggClassEst的符号来了解分类的结果(aggClassEst的符号为正代表+1,为负代表-1,因为程序后由sign()函数,也就是说最终程序判断分类结果是通过aggClassEst的符号而不是weakClassArr)。
第二次迭代之后,第一个数据点已经正确分类了,但此时最后一个数据点却是错分了。D向量中的最后一个元素变为0.5,而D向量中的其他值都变得非常小。最后,第三次迭代之后aggClassEst所有值的符号和真是类别标签都完全吻合,那么训练错误率为0,程序终止运行。
最后训练结果包含了三个弱分类器,其中包含了分类所需要的所有信息。一共迭代了3次,所以训练了3个弱分类器构成一个使用AdaBoost算法优化过的分类器,分类器的错误率为0。
五、在稍微复杂的数据机上使用Adaboost
首先添加一个读取数据的代码段:
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t'))) #每个样本的特征数,包含了一个分类结果
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1): # -1是因为最后一个数是标签
lineArr.append(float(curLine[i])) #生成数据向量
dataMat.append(lineArr)
labelMat.append(float(curLine[-1])) #生成标签向量
return dataMat, labelMat然后添加一个Adaboost分类代码和测试代码段,
def adaClassify(datToClass,classifierArr):
"""
AdaBoost分类函数
Parameters:
datToClass - 待分类样例
classifierArr - 训练好的分类器
Returns:
分类结果
"""
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #遍历所有分类器,进行分类
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
# print(aggClassEst)
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
print(weakClassArr)
predictions = adaClassify(dataArr, weakClassArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('训练集的错误率:%.3f%%' % float(errArr[predictions != np.mat(LabelArr).T].sum() / len(dataArr) * 100))
predictions = adaClassify(testArr, weakClassArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('测试集的错误率:%.3f%%' % float(errArr[predictions != np.mat(testLabelArr).T].sum() / len(testArr) * 100))
这里使用的数据集就是《机器学习实战》中第七章的 horseColicTraining2.txt 在网上很容易下载到。运行结果如图:
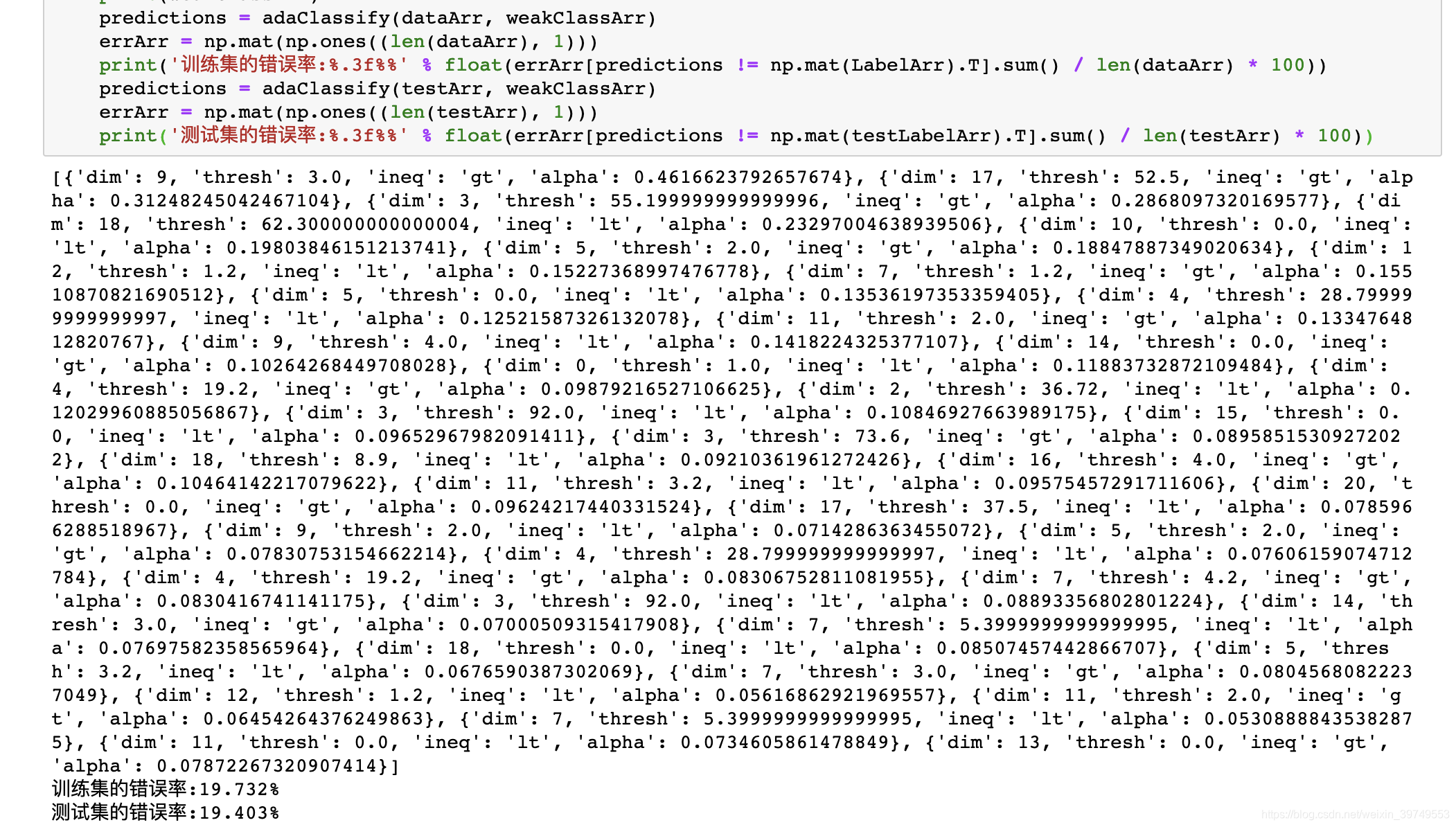
这里输出的是AdaBoost算法训练好的分类器的组合,由于迭代了40次,也就是训练了40个弱分类器,最终的结果是由这40个分类器叠加而成的。最终,训练集的错误率为19.732%,测试集的错误率为19.403%,相对于逻辑回归方法,错误率降低了。这个仅仅是我们训练40个弱分类器的结果,如果训练更多弱分类器,效果会更好。但是当弱分类器数量过多的时候,你会发现训练集错误率降低很多,但是测试集错误率提升了很多,这种现象就是过拟合(overfitting)。也就是分类器对训练集的拟合效果好,但是泛化性能变差,只对训练集的分类效果好,这是我们不希望看到的。
Adaboost算法的介绍就是这些,总之,按照我目前的理解,Adaboost自身不是一种分类算法,它是应用在弱分类器上用于增强弱分类器性能的算法。Adaboost的基本思路来自于bagging和boosting两种方法,这两种方法也衍生出了很多其他的新算法,可以自行查找。
参考资料:
《机器学习实战》
《机器学习》-- 周志华

















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









