






语言模型是根据人类语言规律进行预测,共经历了4个阶段
1,1990年时期统计语言模型(SLM)
- Markov Assumption原理:通常是根据词序 列中若干个连续的上下文单词来预测下一个词的出现概率,即根据一个固定长度 的前缀来预测目标单词。
- 用处:(Information Retrieval, IR)和(Natural Language Processing, NLP)等领域
- 举例:

如果是3元模型,例如我喜欢吃苹果,需要先算出我喜欢吃的改了,前缀为2,计算如下
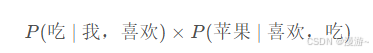


- 缺点:维数灾难

- 解决方案:语言模型平滑策略,如回退估计(Back-off Estimation)和古德-图灵估计(Good-Turing Estimation)。然而平滑方法对于高阶上下文的刻画能力仍然较弱,无法精确建模复杂的高阶语义关系。
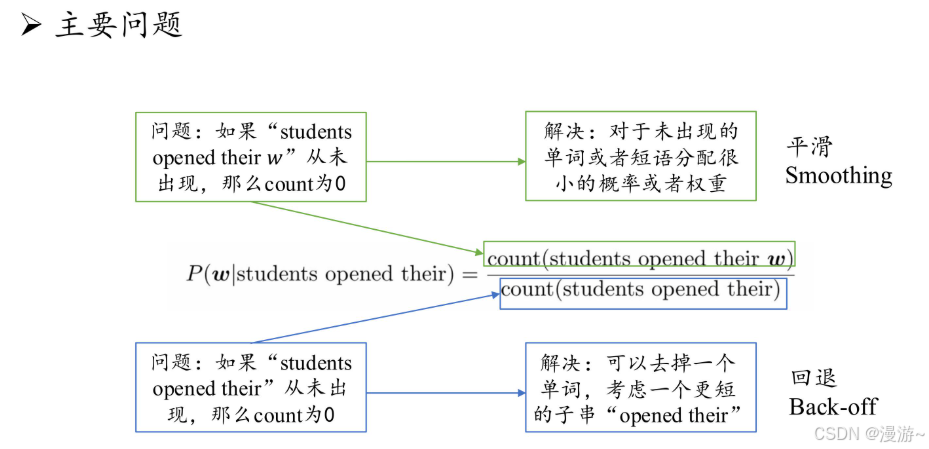
为了解决从未出现的数量,导致零概率,采用加一平滑的处理办法



对于某修前缀不连贯的情况,可以使用回退的方法



2,2013年神经语言模型(Neural Language Model, NLM)
-
Distributed Word Representation原理 :使用分布词,构建分布词向量,使用预测函数,产出对应预测词
-
举例
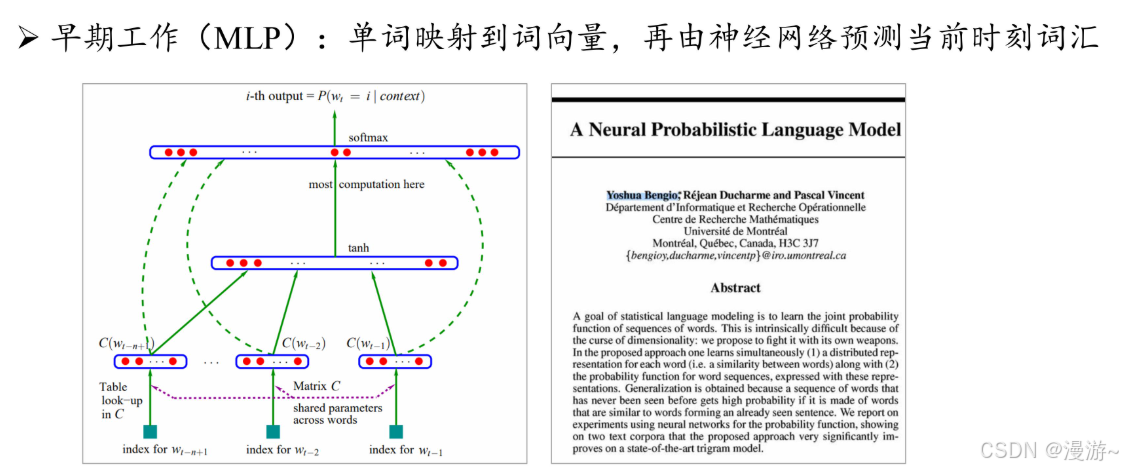


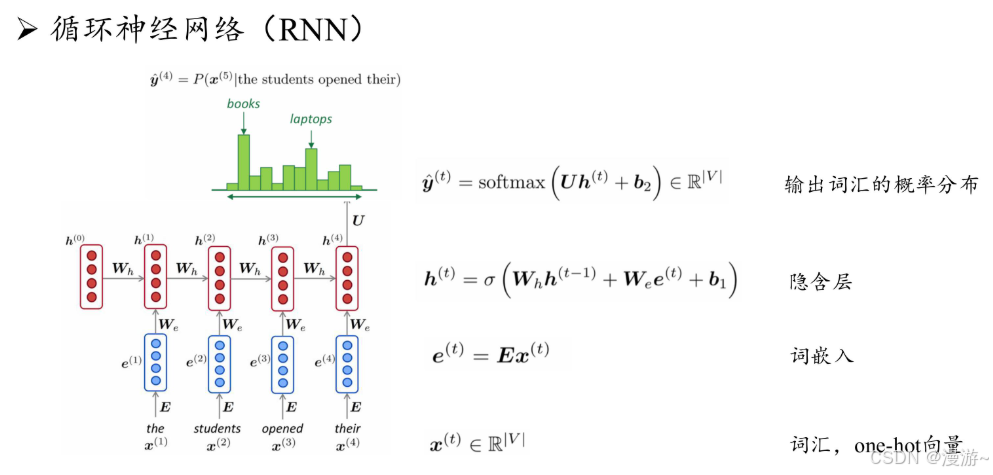

3,2018年预训练模型(Pre-trained Language Model, PLM)
- Transformer原理:通过 自注意力机制建模长程序列关系,其模型设计对 于硬件非常友好,可以通过 GPU 或者 TPU 进行加速训练,这为研发大语言模型提 供了可并行优化的神经网络架构。
谷歌BERT采用编码器的 Transformer 架构,并通过在大规模 无标注数据上使用专门设计的预训练任务来学习双向语言模型。
GPT-1采用了仅有解码器的 Transformer 架构,以及基于下一个词元预测的 预训练任务进行模型的训练
一般来说,编码器架构被认为更适合去解决自然语言理解任务(如完形填空等),而解码器架构更适合解决自然语言生成任务(如文本摘要等)


4,2022年大语言模型(Large Language Model, LLM)
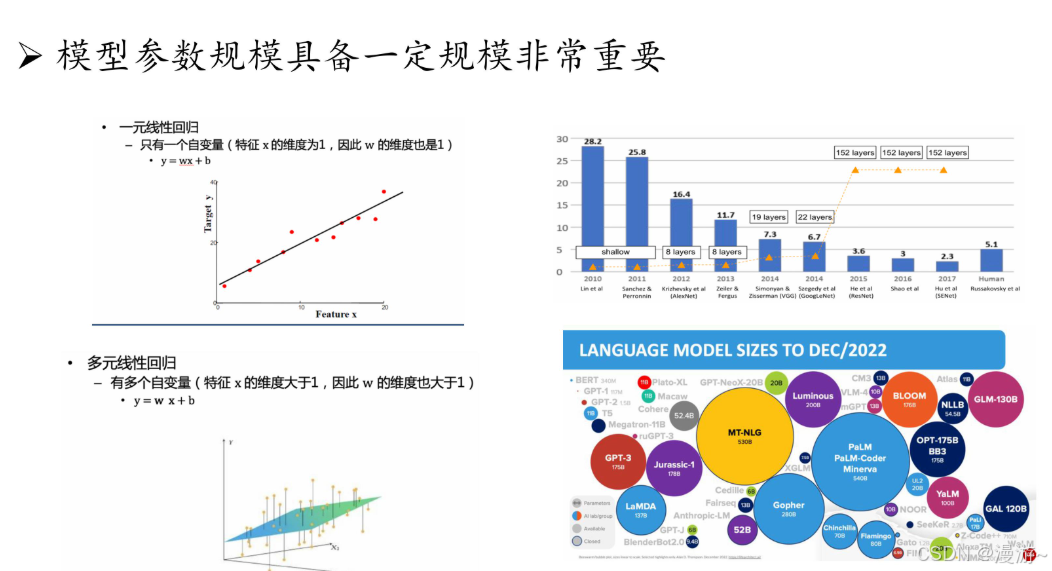
模型扩展(如增加模型参数671B deepseek R1或增大数据规模),会给下游模型带来提升




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









