






Transformer解码器架构
Transformer模型包括两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器负责处理输入数据,解码器则生成输出。可以把编码器看作“翻译器”,而解码器则是“说话者”。
Transformer解码器在生成时是“逐字”进行的,也就是说,每生成一个单词,它会依据已经生成的所有单词以及输入信息来决定下一个单词。例如:
- 初始时,解码器可能开始生成一个句子的第一个单词,例如 “Il” (法语“他”或“它”)。
- 然后,它会观察到这个单词,并结合编码器的输出(原文的上下文),接着生成第二个单词,比如 “est”。
- 这个过程会持续进行,直到生成完整的句子或达到预设的结束标记。
解码器的主要任务是根据编码器提供的信息生成目标序列(例如,将英语翻译成法语)。解码器通常由多个层(Layers)组成,每层又包含以下几个主要组件:
自注意力机制(Self-Attention):
- 比喻:想象一下你在写一篇文章时,回过头去看看之前写的句子,以确保语句的连贯性。这就是自注意力机制的作用,它让解码器能够关注已经生成的部分,以保持输出的一致性。
编码器-解码器注意力(Encoder-Decoder Attention):
- 比喻:想象你在翻译一句句子。这时你不仅要看自己已经翻译过的句子,还需要参考原文(编码器的输出)。这个注意力机制让解码器能够结合输入信息,生成更合适的输出。
前馈神经网络(Feed-Forward Neural Network):
- 比喻:解码器在自注意力和编码器-解码器的注意力之后,还需要进一步处理信息,就像通过过滤器对生成的内容进行加工,以确保表达的清晰和准确。
层归一化和残差连接(Layer Normalization and Residual Connections):
- 比喻:想象你在跑步,经过一段时间后你可能会累,但保持好状态的关键是适时得到一些支持。层归一化和残差连接帮助模型在较深的层次中保持稳定性,减少训练时的困难。

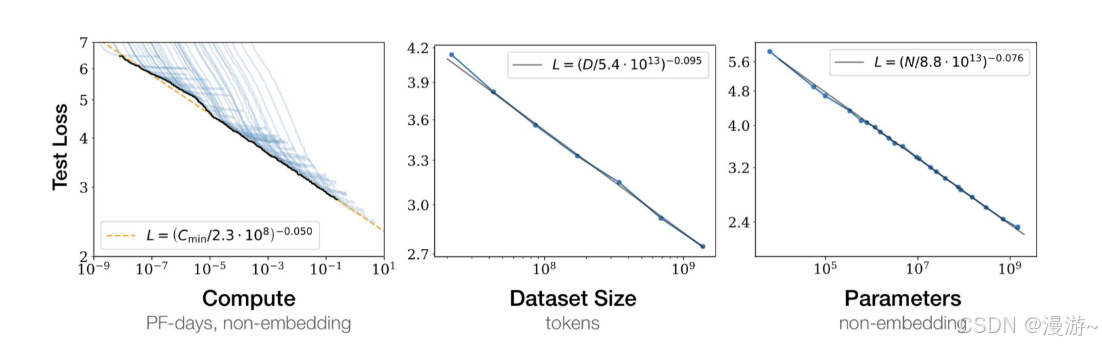
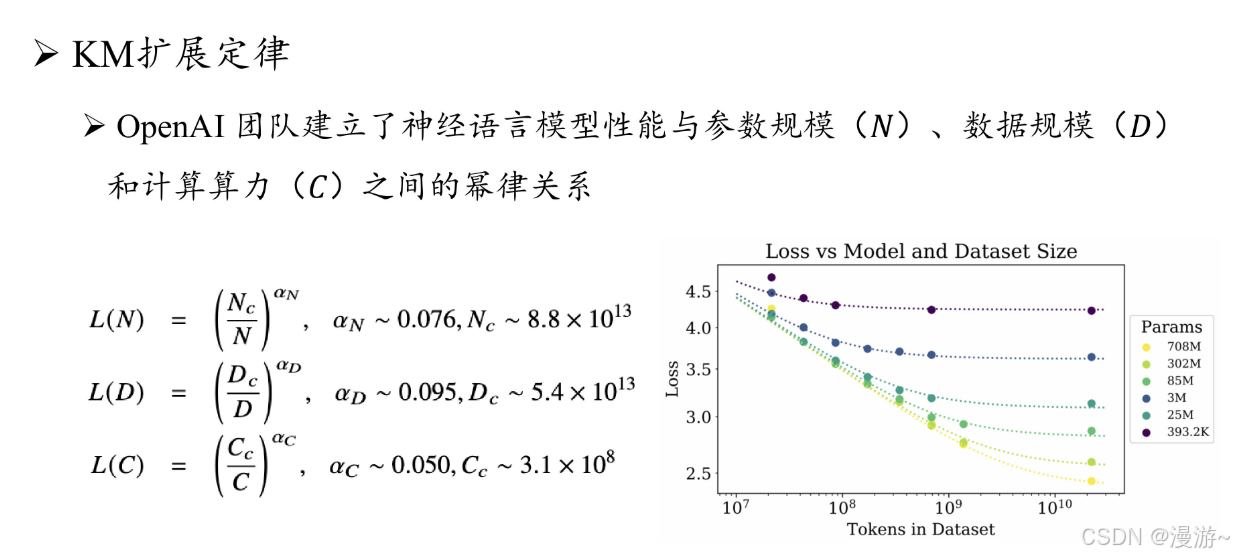
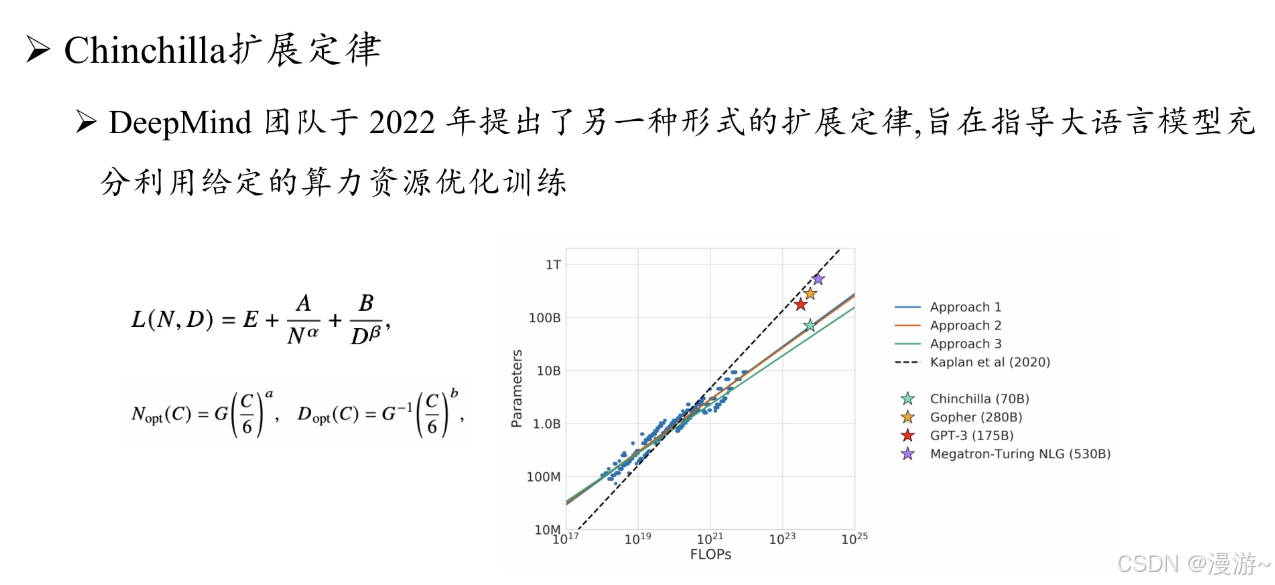
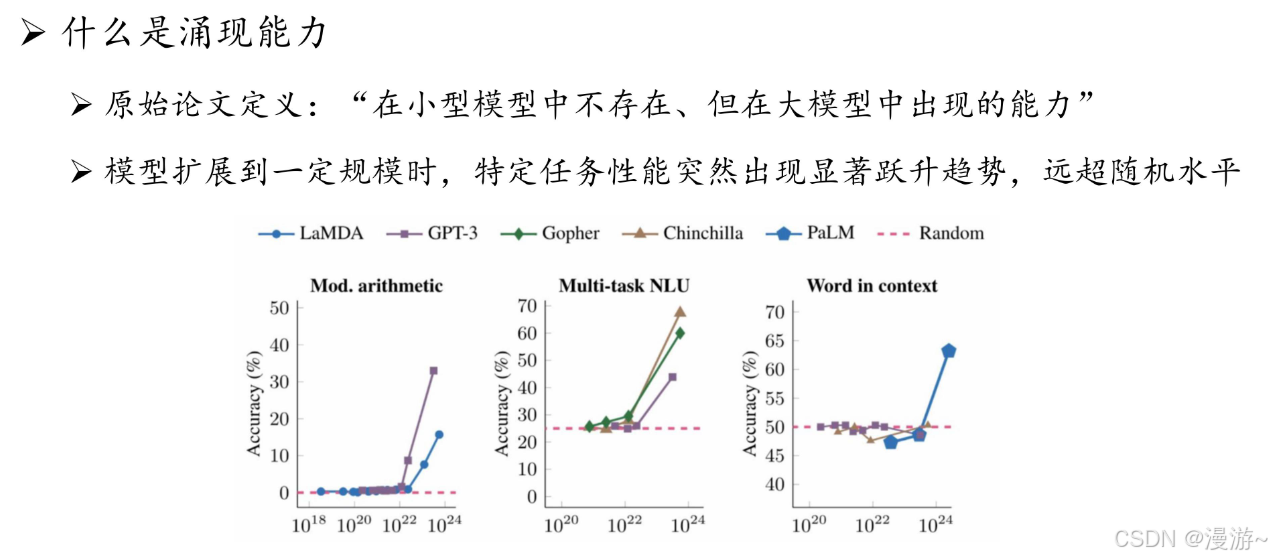
大语言模型关键技术突破主要从参数,数据,算力三个方面进行优化
- 参数规模 :可达千亿级参数
2.数据工程:
(1)数据来源全面高质
(2)精细的清理,提升数据质量
(3)设计有效的数据配比与数据课程,加强模型对于数据语义信息的利用效率

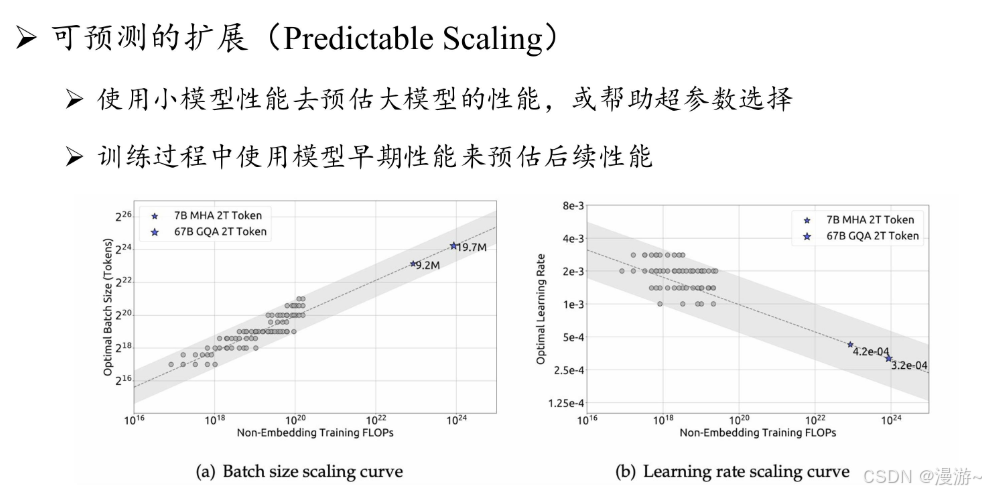
3.高效预训练:
由于参数巨大,设计分布式并行算法,为节省算例,实际操作中需要开展基于小模型的沙盒测试实验,进而确定面向大模型的最终训练策略。
4.能力激发:
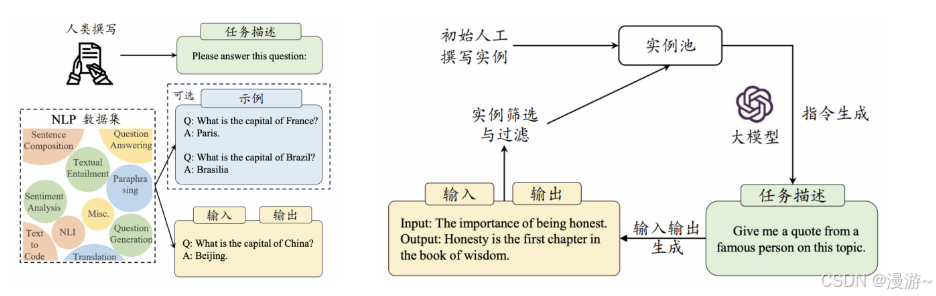
为了提升模型的任务求解能力,需要设计合适的指令微调以及提示策略进行激发或诱导
- 指令微调是在原有模型的基础上,通过具体的任务示例进行再训练,使模型能够理解和执行新的指令,提升特定任务的效果。
- 提示策略则通过构造巧妙的输入提示,帮助模型在没有再训练的情况下利用已有知识产生更符合预期的输出。
进一步,大语言模型还具有较好的规划能力,能够针对复杂任务生成逐步求解的解决方案,从而简化通过单一步 骤直接求解任务的难度,进一步提升模型在复杂任务上的表现。

5.人类对齐
大量训练数据可能包含低质量、个人隐私、事实错误的数据信息,导致大语言模型可能会生成有偏见、泄露隐私甚至对人类有害的内容。
“ 3 H 对齐标准”,即 Helpfulness ( 有用性 )、 Honesty ( 诚实性 )和 Harmlessness( 无害性 )。RLHF: 首先训练能够区分模型输出质量好坏的奖励模型,进而使用强化学习算法来指导语言模型输出行为的调整,让大语言模型能够生成符合人类预期的输出。为解决RLHF太复杂的问题, 使用监督微调的对齐方式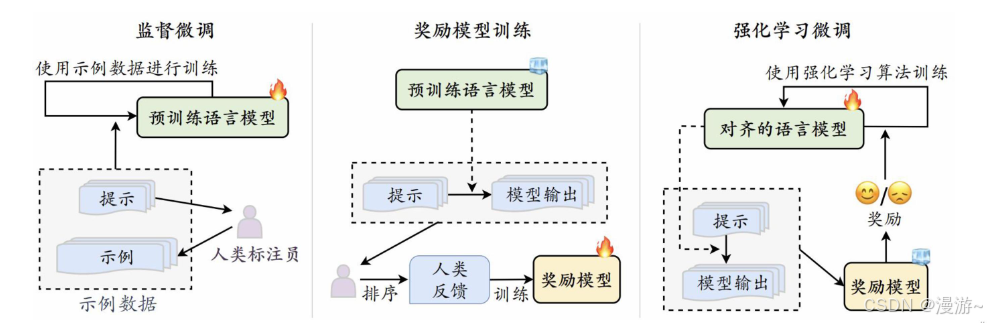
6.工具使用
大语言模型本质是大规模文本数据的语义学习,因此受限非自然语言形式的任务(数值计算)和超过预训练数据所提供的信息,无法有效推断出超过数据时间范围和覆盖内容的语义信息。
为解决上述问题,模型可以在指令微调和提示策略进行工具的调用,例如,大语言模型可以利用计 算器进行精确的数值计算,利用搜索引擎检索最新的时效信息。
历史流变
当前困境
- 大模型中某些重要能力(如上下文学习)缺乏理论基础和深入原因探究
- 大模型成本太高,已有的成果开源性不够,导致壁垒高
- 与人类对齐有困难

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









