






预训练过程



算力评估
目前的开源模型普遍采用 2∼3T 规模的词元进行预训练,这一过程对算力需求量很大,一般来说训练百亿模型至少需要百卡规模算力集群(如A100 80G)联合训练数月时间;而训练千亿模型则需要千卡甚至万卡规模的算力集群.
指令微调对于算力资源的需求相对较小。一般情况下, 若干台单机八卡(A100-80G)的服务器就能在一天或数天的时间内完成百亿模型的指令微调,当指令数据规模较大的时候可以进一步增加所需要的算力资源。这个过程还可以进一步加入多轮次的对话数据来增强模型的人机对话能力。
由于强化学习需要维护更多的辅助模型进行训练,通常来说对于资源的消耗会多于指令微调, 但是也远小于预训练阶段所需要的算力资源。目前还有很多工作试图通过消除奖励模型的使用,或其他使用 SFT 方式来达到与 RLHF 相似的效果,从而简化模型的对齐过程。
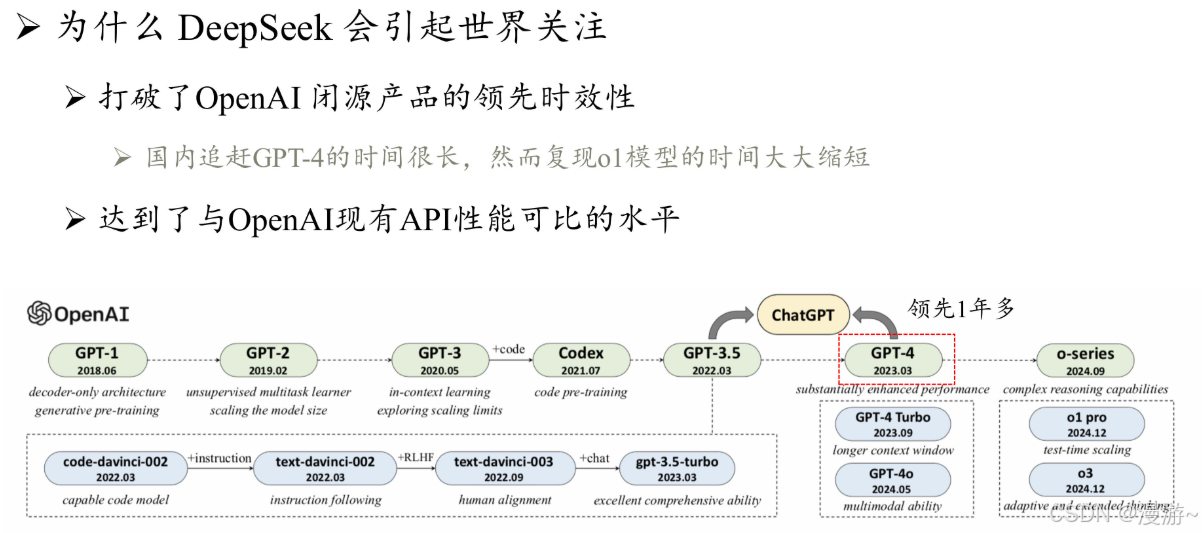
GPT与Deepseek的演变
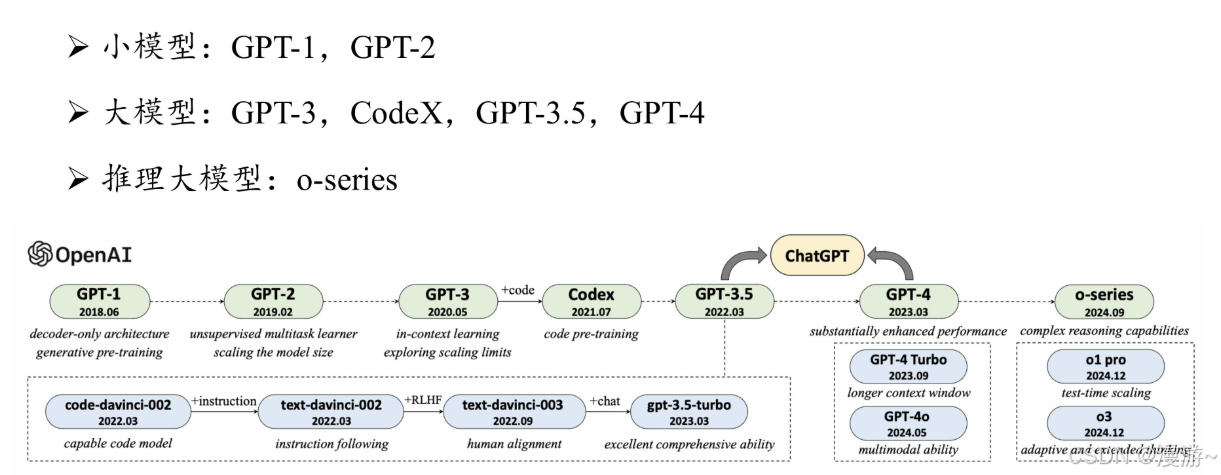

OpenAI对大语言的研发可分为四个阶段:
一,早期探索阶段
2017年Google推出transformer后OpenAI立即在18年发布GPT-1,模型名称 GPT 是生成式预训练(Generative Pre-Training)的缩写.
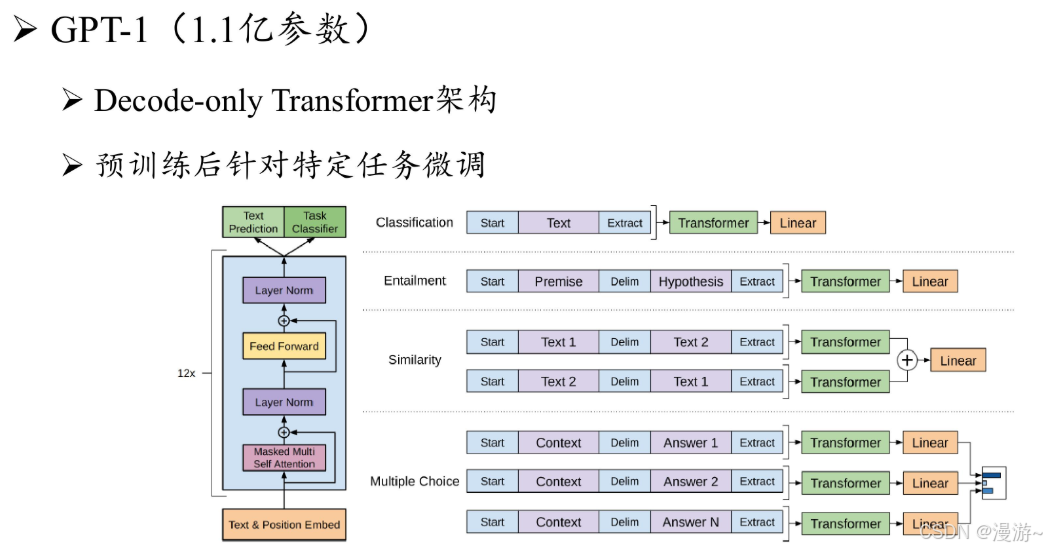
GPT-1原理:GPT-1 基于生成式、仅有解码器的 Transformer 架构开发,奠定了 GPT 系列模型的核心架构与基于自然语言文本的预训练方式, 即预测下一个词元。
GPT-1缺点:由于当时模型的参数规模还相对较小,模型仍然缺乏通用的任务求解能力,因而采用了无监督预训练和有监督微调相结合的范式.
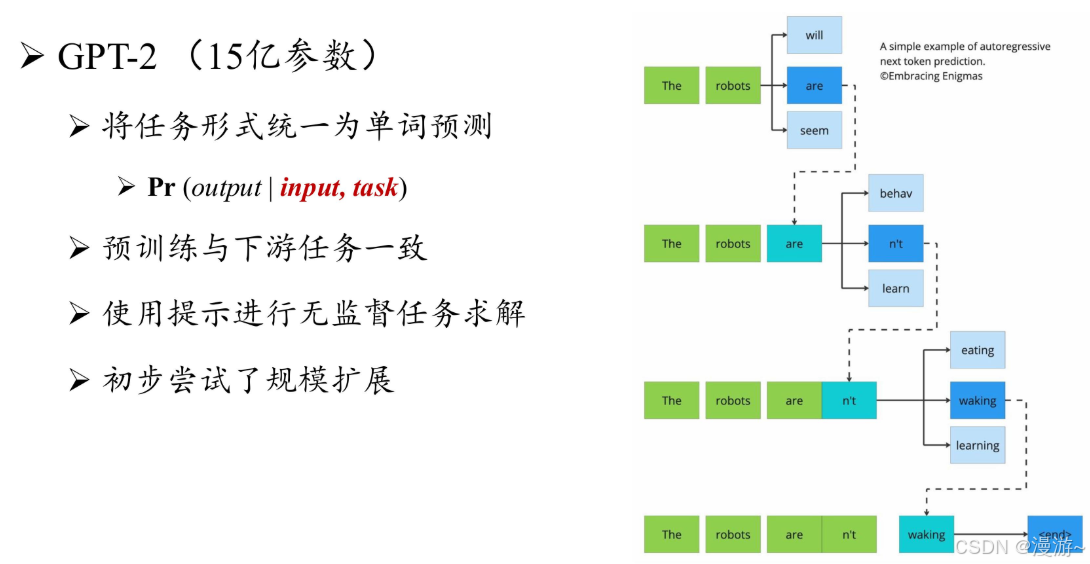
GPT-2原理:GPT-2 沿用了 GPT-1 的类似架构,将参数规模扩大到 1.5B,并使用 大规模网页数据集 WebText 进行预训练。与 GPT-1 不同,GPT-2 旨在探索通过扩大模型参数规模来提升模型性能,并且尝试去除针对特定任务所需要的微调环节。(它试图使用无监督预训练的语言模型来解决各种下游任务,进而不需要使用标注数据进行显式的模型微调。)
GPT-2缺点:模型效果相对有监督微调方法要稍微逊色
二,规模扩展
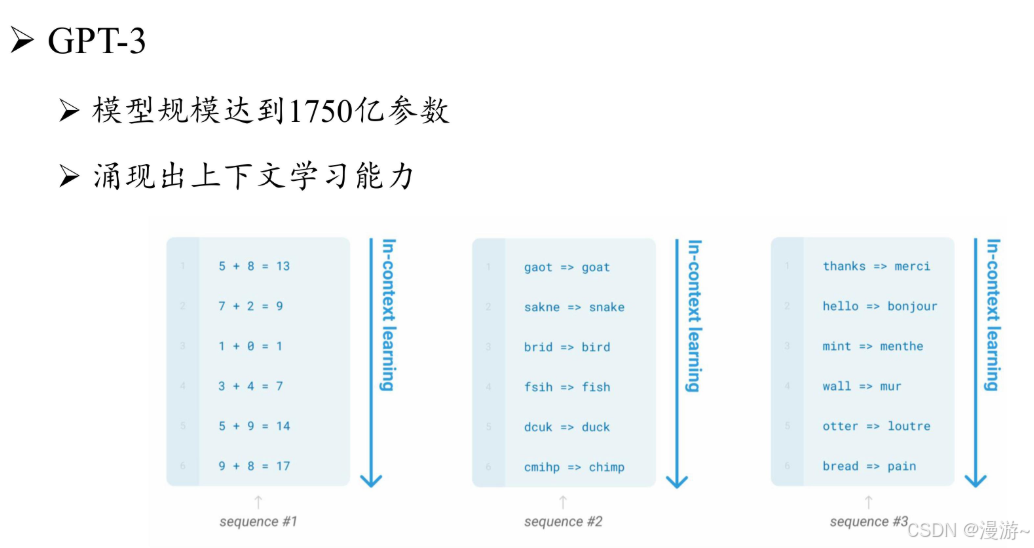
GPT-3原理:将模型参数扩展到了 175B 的规模。与 GPT-2 相比,GPT-3 直接将参数规模提升了 100 余倍.正式使用上下文学习,大语言模型的训练与利用可以通过语言 建模的形式进行统一描述(同年发布拓展法则)
三,能力增强
- 代码数据训练:根据 OpenAI 所发布的 API 信息所示,GPT-3.5模型是在基于代码训练的 GPT 模型(即 code-davinci-002)基础上开发的,这表明在代码数据上进行训练有助于提高 GPT 模型的综合性能,尤其是代码能力。
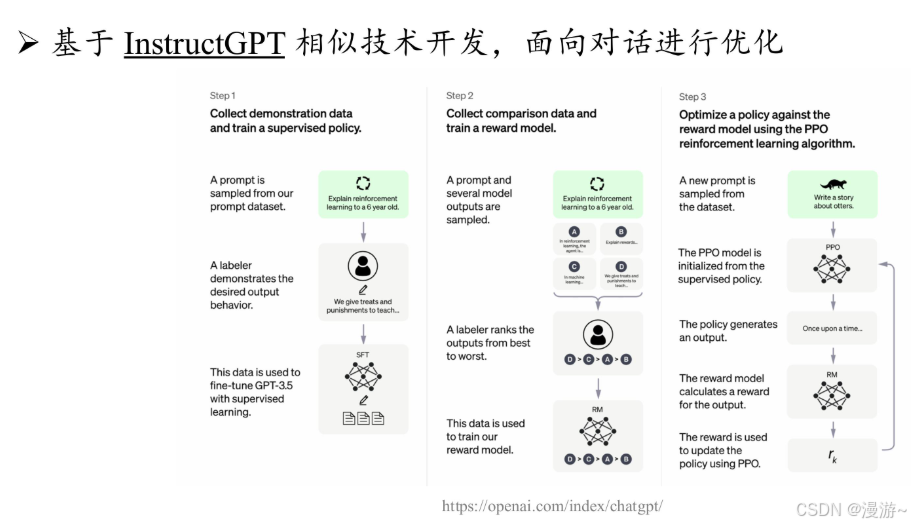
- 人类对齐:2022 年 1 月,OpenAI 正式推出 InstructGPT 这一具有重要影响力的学术工作,旨在改进 GPT-3 模型与人类对齐的能力,正式建立了基于人类反馈的强化学习算法,即 RLHF 算法。



四,性能跃升
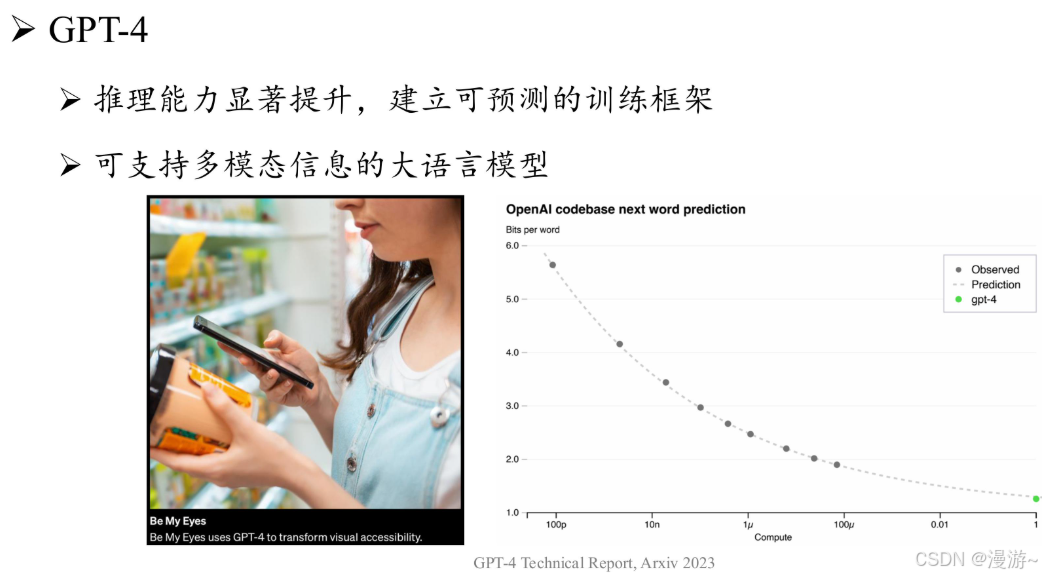
GPT-4:首次将GPT 系列模型的输入由单一文本模态扩展到了图文双模态。GPT-4 搭建了完备的深度学习训练基础架构,进一步引入了可预测扩展的训练机制,可以在模型训练过程中通过较少计算开销来准确预测模型的最终性能。
GPT-4V:广泛讨论了与视觉输入相关的风险评估手段和缓解策略.
GPT-4 Turbo:提升了模型的整体能力(比 GPT-4 更强大),扩展了知识来源(拓展到 2023 年 4 月),支持更长上下文窗口(达到 128K),优化了模型性能(价格更便宜),引入了若干新的功能(如函数调用、可重复输出等)。

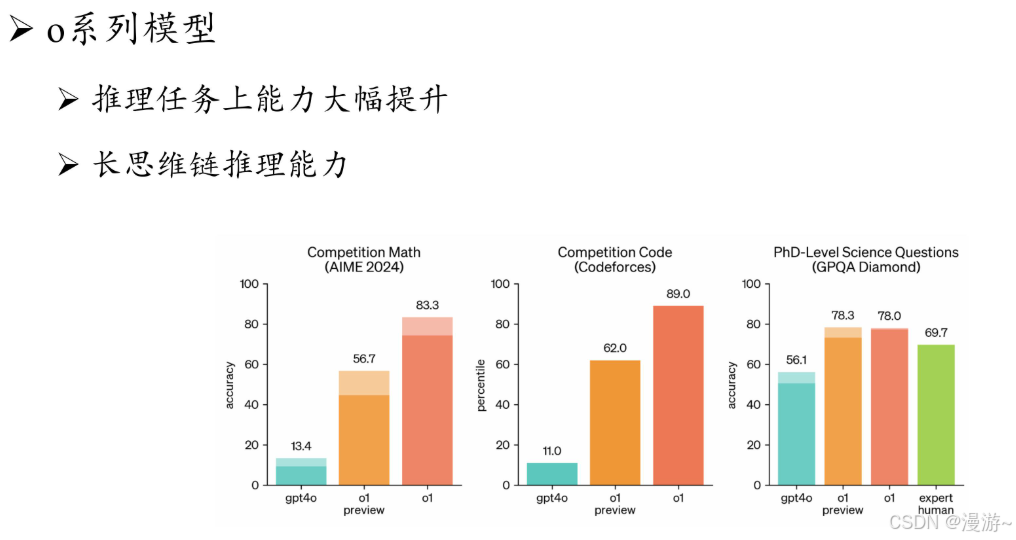

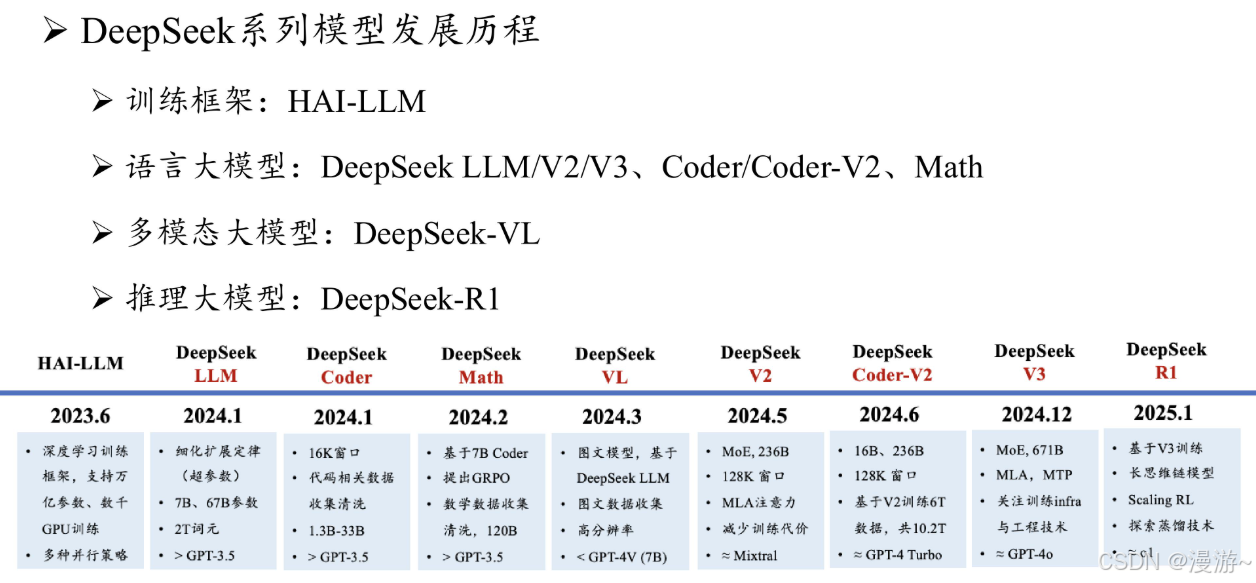
DeepSeek介绍


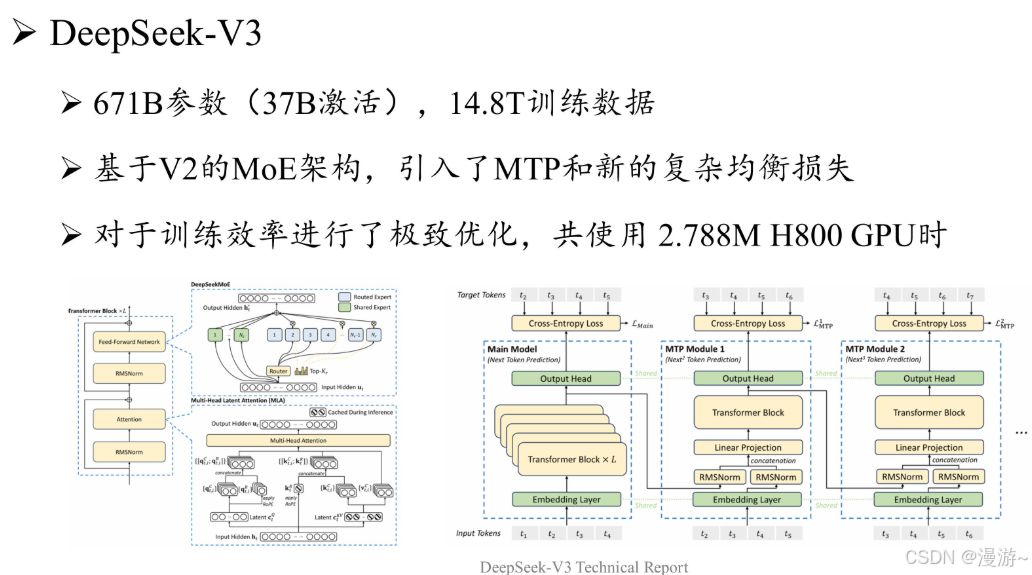
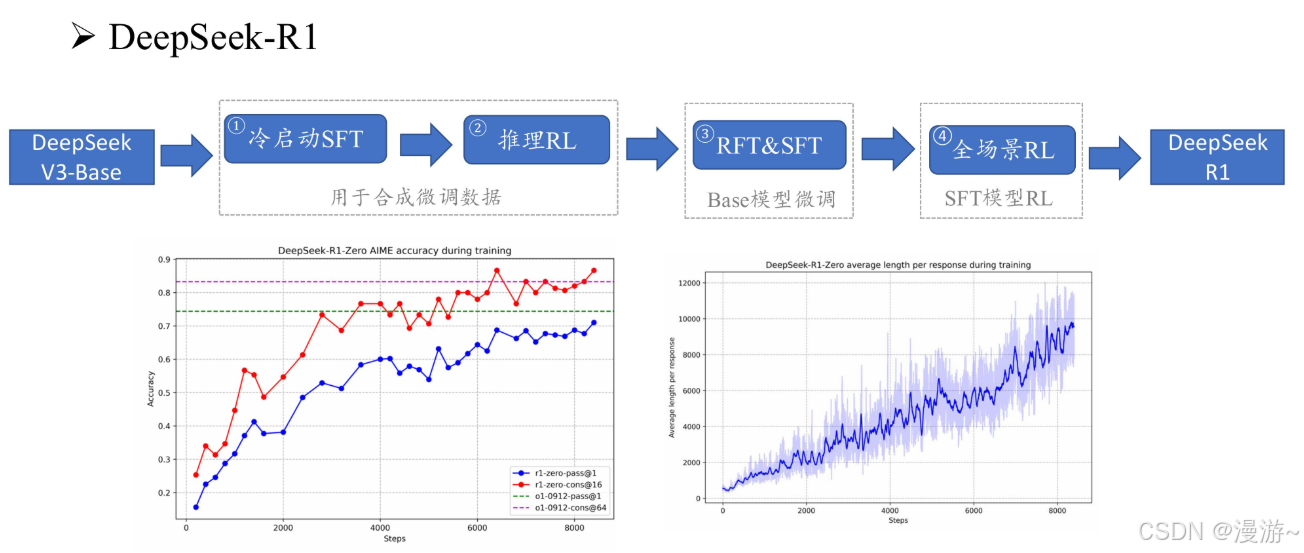
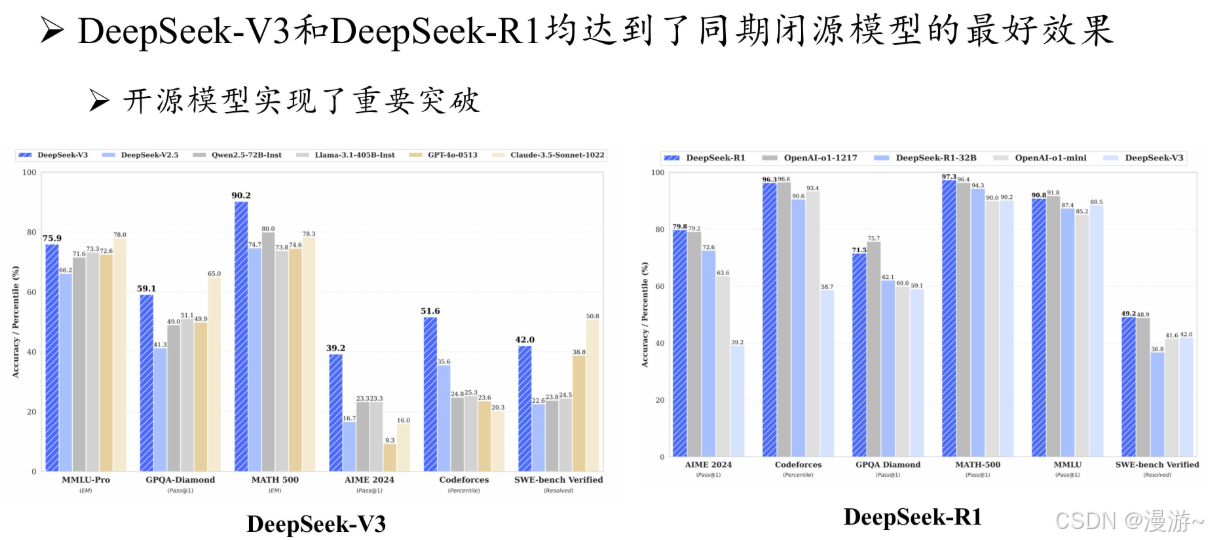
当前使用DeepSeek的问题:思考过程特别慢,也是因为架构决定


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









