







 本文介绍GroupSoftmax交叉熵损失函数如何在不重新标注原有数据的情况下,解决目标检测中类别变化的问题,降低标注成本,适用于多数据集联合训练。
本文介绍GroupSoftmax交叉熵损失函数如何在不重新标注原有数据的情况下,解决目标检测中类别变化的问题,降低标注成本,适用于多数据集联合训练。
参考文献:https://www.zhuanzhi.ai/document/cd49eeb11c338b1feaf4e6feae84ec5d
github【以simpledet为基础网络】:https://github.com/chengzhengxin/groupsoftmax-simpledet
1.能解决的问题
- 在不重新标注原有数据的情况下,对新的标注数据,增加某些新的类别
- 在不重新标注原有数据的情况下,对新的标注数据,修改原有的类别标准,比如将某个类别拆分成新的几个类别
- 已标注数据集中,出现概率较高的类别一般属于简单样本,对新的数据只标注出现概率较低的类别,能够显著降低标注成本
- 在标注大型目标检测数据集时,只标注矩形框,而不选择类别属性,能够有效降低标注成本
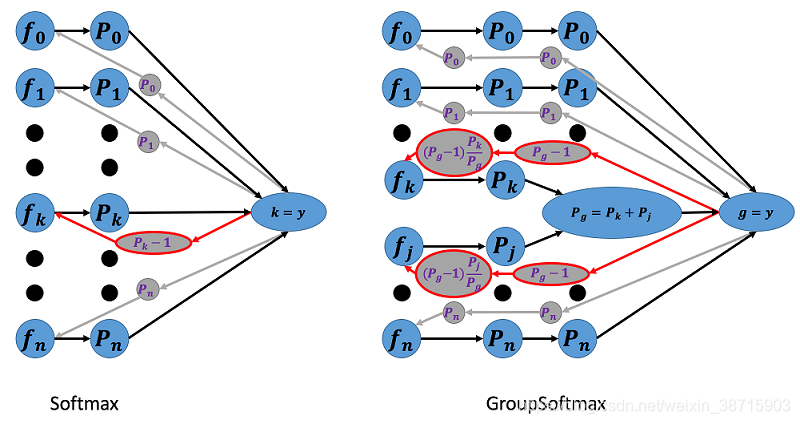
GroupSoftmax 交叉熵损失函数允许类别 K 和类别 j 发生合并,形成一个新的组合类别 g ,当训练样本 y 的真实标签为组合类别 g 时,也能够计算出类别 K 和类别 j 的对应梯度,完成网络权重更新。理论上, GroupSoftmax 交叉熵损失函数能够兼容任意数量、任意标注标准的多个数据集联合训练。
在参考文献中举例说明了为什么现实生活中需要这个损失函数,当数据集中原有的类别C4='自行车',C5='电动车'需要合并成C='非机动车类'时,可以使用GroupSofmax函数进行训练,而不是使用大量人工对样本进行标注。
2.公式的推导
损失函数的定义【对于群组类这个类的损失计算如下】:
上式中,g表示一个群组类,比如说刚刚的非机动车类,里面就包含了自行车和电动车两个类;也有可能就是一个单独的摩托车类别谁也不包含。其中为群组类的概率,公式如下【是两个类的概率和】:
与Softmax损失函数一样,可以使用复合求导的方式进行求导【得到分类对于之前传向它的每个分类的分支的导数】,因此有:
1)公式一:
有两种情况,第一,当 群组类别g中包含了m类别【当样本m为自行车时,群组类别g=非机动车包含了m,但群组类g=摩托车不包含m】
第二,当 群组类别g中不包含m类别
2)公式二:
又要分情况讨论了,
第一,当对应的输出分支为正样本时,这种情况又有两种情况:
m既是正样本 群组类g又包含m类,有
m是正样本 群组类g不包含m类,有
所以有,
第二,当对应的输出分支为负样本时, 这种情况又有两种情况:
m既是负样本 群组类g又包含m类,有
m是负样本 群组类g不包含m类,有
所以有,
3)最后举个例子
对于群组类g=非机动车类来说,当m=电动车时,有
对于群组类g=非机动车类来说,当m=摩托车时,有

















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









