










 PixelLink是一种基于实例分割的场景文本检测方法,通过链接像素实现文本实例的分割,再从分割结果中直接提取文本边界框,避免了位置回归,实验证明在多个基准上表现优秀。
PixelLink是一种基于实例分割的场景文本检测方法,通过链接像素实现文本实例的分割,再从分割结果中直接提取文本边界框,避免了位置回归,实验证明在多个基准上表现优秀。
1. 前言
高产似母猪的一周,这是第五篇模型阅读。同时纪念今天实验室可以连IPv6啦撒花!可以不用费心巴力去找Ubuntu翻墙的方法了开心!Google账户都同步了!!
言归正传,PixelLink是基于分割来检测场景文本,与之前的4种模型(检测框+回归)有些不同。文本实例首先通过将相同实例中的像素链接在一起来分割。然后直接从分割结果中提取文本边框,而不需要位置回归。实验表明,与基于回归的方法相比,PixelLink可以在多个基准测试中获得更好或可比性的性能,同时可以重新查询更少的训练迭代和更少的训练数据。
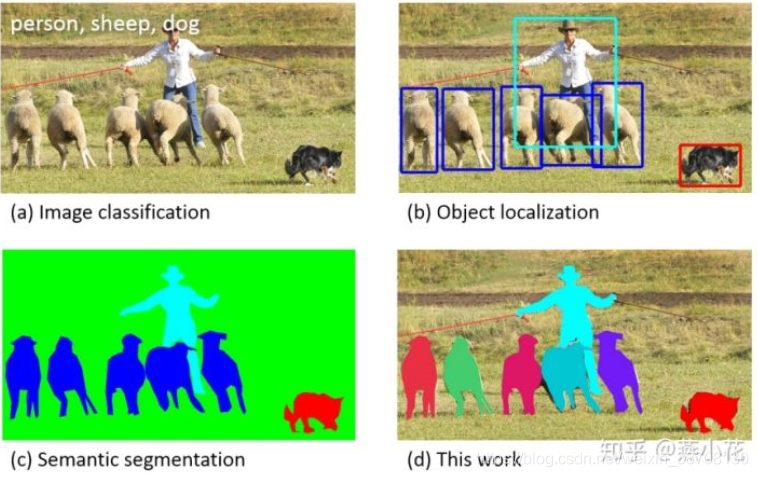
语义分割:对图像中的每个像素都划分出对应的类别,即实现像素级别的分类
实例分割:不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例
对于一般的对象检测来说,实例分割比语义分割更容易识别对象实例。
左:语义分割;右:实例分割
2. 实现
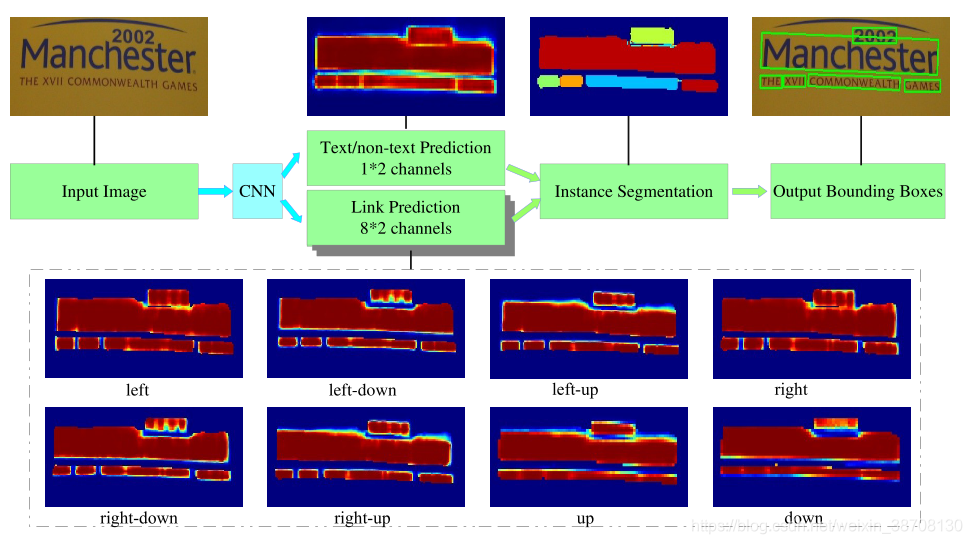
上图所示是PixelLink的体系结构。训练一个CNN模型来执行两种像素预测:文本/非文本预测和链接预测。经过阈值后,正像素通过正链接连接在一起,实现了实例分割。然后应用minAreaRect直接从分割结果中提取边框。利用后滤波可以有效地去除噪声预测。下面虚线框中的八个热图代表了八个方向的链接预测。
2.1 网络结构
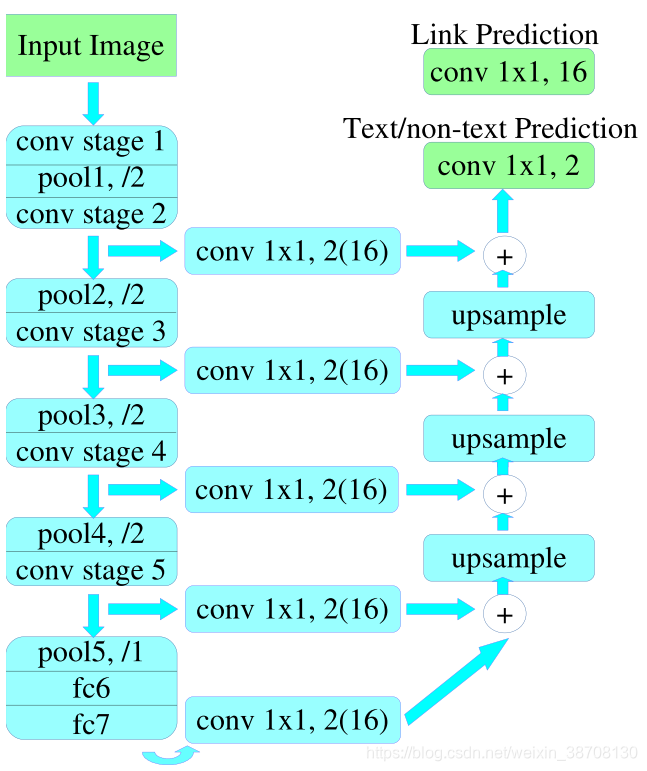
(上图是使用了PixelLink+VGG16 2s的结构)
- 首先用VGG16作为基础网络,并将VGG16的最后两个全连接层改成卷积层
- 提取feature map
- 从下向上采样并加和。共18个channel,16(2*8)个(文本/非文本)link feature map,和2个文本/非文本2分类feature map。
2.2 将像素连接到一起
给定对像素和链接的预测,可以对它们分别应用两个不同的阈值。然后,使用正链接将正像素分组在一起,形成CCs集合,每个CCs代表一个检测到的文本实例。
给定两个相邻的pixel positive,它们之间的link预测是由当前两个pixel共同决定的。而当前两个pixel需要连接(即两个像素属于同一个文本实例)的前提条件:两个links中至少有一个link positive。连接的规则采用的是Disjoint set data structure(并查集)的方法。
2.3 边界框的提取
基于2.2的CCs集合,直接通过opencv的minAreaRext提取文本的带方向信息的外接矩形框(即带角度信息),具体的格式为((x,y),(w,h),θ),分别表示中心点坐标,当前bbox的宽和高,旋转角度。
SegLink与其他基于回归的方法的关键区别:PixelLink是直接从分割结果中提取bbox,而其他采用的是边框回归。
2.4 分割之后的后处理(滤波)
因为Link的过程中不可避免的会引入噪声。文中对已检测的包围框通过一些简单的几何形状判断(包括包围框的宽,高,面积及宽高比等,这些主要是在对应的训练集上进行统计的出来的)进行滤波。经过后处理后,可以提升文本行检出的准确率。
3. 优化
- Ground Truth的计算
像素的生成规则:在文本行包围框内的像素被标注成positive,如果存在重叠文本时,则非重叠的文本框区域内的像素被标注成positive,否则被标注成negative
像素间的link生成规则:给定一个像素,若其与邻域的8像素都属于同一个文本实例,则将其link标注为positive,否则标注为negative
- 损失函数
L = λ L p i x e l + L l i n k L=\lambda L_{pixel}+L_{link} L=λLpixel+Llink
(一) L p i x e l L_{pixel} Lpixel损失
由于文本行大小不一,若在计算loss的时候,对所有的pixel positive给予相同的权重,则会偏向大面积文本行,导致小面积文本行的检测困难,因此论文提出了Instance-Balanced Cross-Entropy Loss(实例的平衡交叉熵损失)。
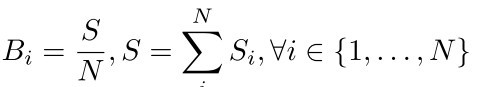
B i B_{i} Bi就是每个实例的权重,S是每个实例的面积,N是实例的总个数。
论文中采用OHEM来选择negative pixel。根据negative-positive比例r (文中设置为3),文本行实例的总面积S,选择loss倒序后的前r*S个negative pixel。 具体的pixel loss公式如下:
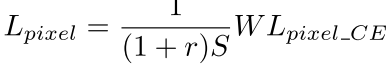
其中W为positive pixel和negative pixel的权重矩阵,是文本/非文本的交叉熵损失,经过上述公式,小面积的文本行可以得到较大的权重,大面积的文本行得到较小的权重,这样就可以让所有的文本行在loss中贡献一样。
(二) L l i n k L_{link} Llink损失
文中只对Positive pixel进行 L l i n k L_{link} Llink损失计算。
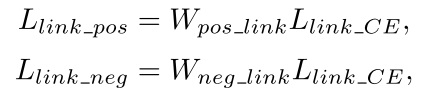
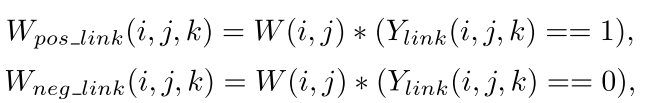
W什么什么是权重,L什么什么是交叉熵损失。
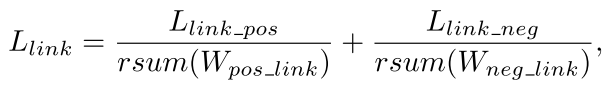
最终的 L l i n k L_{link} Llink是一种类平衡交叉熵损失。 - 数据增广
数据增广的方式和SSD相似,在SSD数据增广上增加了随机旋转步骤。
具体的做法是输入图像先以0.2的概率进行随机旋转,旋转的角度范围值为[ 0 , π 2 , π , 3 π 2 0,\frac{\pi }{2},\pi,\frac{3\pi }{2} 0,2π,π,23π];然后在进行crop操作(面积范围在0.1~1之间,aspect ratio为0.5~2);最后统一将图像缩放到 512 × 512 512\times512 512×512。
经过数据增广后,对于文本行的短边小于10个像素的和文本实例小于20%的进行忽略。对于忽略的文本实例在计算损失函数的时候权重设置为0。
4. 结果

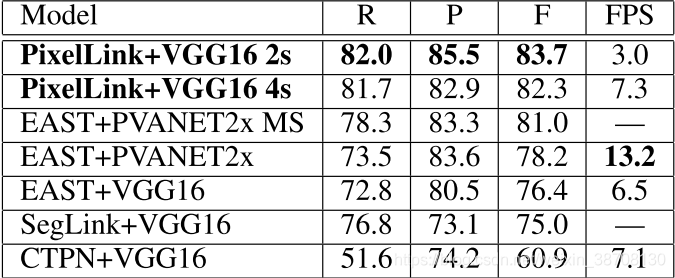
5. 总结
- 与以往基于包围框回归的方法(CTPN,RRPN,DMPNet,EAST)不同的是,PixelLink放弃了包围框回归,而是先分割,再Link,再从Link中直接生成包围框。这样做速度更快。
- 对感受野的要求少(因为每个神经元值只负责检测自己及其邻域内的状态),而且不能检测字与字之间相隔太远的文本(因为太远了Link不到)。
- 适合端到端,直接把图片拿过来作input,不需要尺度变换来微调。
6. 参考文献
1.《PixelLink: Detecting Scene Text via Instance Segmentation》
2.https://zhuanlan.zhihu.com/p/38171172
3.https://blog.youkuaiyun.com/qq_14845119/article/details/80953555
4.https://zhuanlan.zhihu.com/p/33744209
5.代码实现

















 7590
7590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









